


這篇文章帶給大家的內容是關於使用Jsoup實現爬蟲技術的方法介紹,有一定的參考價值,有需要的朋友可以參考一下,希望對你有所幫助。
1.Jsoup簡述
#Java中支援的爬蟲框架有很多,例如WebMagic、Spider、Jsoup等。今天我們使用Jsoup來實作一個簡單的爬蟲程式。
Jsoup擁有十分方便的api來處理html文檔,例如參考了DOM物件的文檔遍歷方法,參考了CSS選擇器的用法等等,因此我們可以使用Jsoup快速地掌握爬取頁面資料的技巧。
2.快速開始
1)寫HTML頁面

#頁面中表格的商品資訊是我們要爬取的資料。其中屬性pname類的商品名稱,以及屬於pimg類的商品圖片。
2)使用HttpClient讀取HTML頁面
HttpClient是處理Http協定資料的工具,使用它可以將HTML頁面作為輸入流讀進java程式中。可以從http://hc.apache.org/下載HttpClient的jar套件。

3)使用Jsoup解析html字串
透過引入Jsoup工具,直接呼叫parse方法來解析一個描述html頁面內容的字串來獲得一個Document物件。該Document物件以操作DOM樹的方式來獲得html頁面上指定的內容。相關API可以參考Jsoup官方文件:https://jsoup.org/cookbook/
下面我們使用Jsoup來取得上述html中指定的商品名稱和價格的資訊。
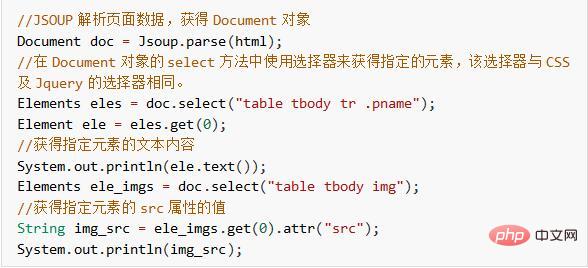
至此,我們已經實作使用HttpClient Jsoup爬取HTML頁面資料的功能。接下來,我們讓效果更直覺一些,例如將爬取的資料存到資料庫中,將圖片存到伺服器上。
3.儲存爬取的頁面資料
1)儲存普通資料到資料庫中
將爬取的資料封裝進實體Bean中,並存到資料庫內。
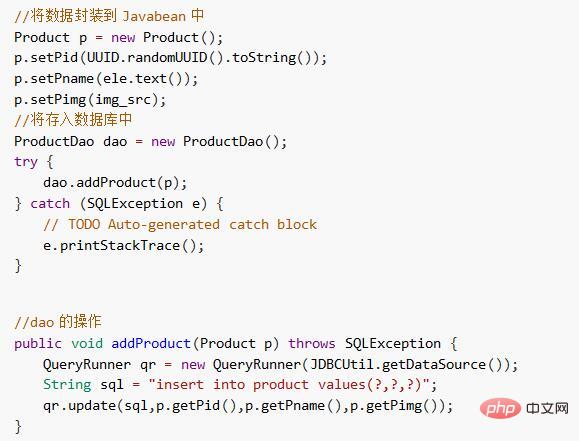
2)將圖片儲存到伺服器上
直接透過下載圖片的方式將圖片儲存到伺服器本機。

4.總結
本案簡單實作了使用HttpClient Jsoup爬取網路數據,對於爬蟲技術本身,還有很多值得深挖的地方,以後再為大家講解。
以上是使用Jsoup實現爬蟲技術的方法介紹的詳細內容。更多資訊請關注PHP中文網其他相關文章!