
Home > Article > Backend Development > Simple and easy-to-use parallel acceleration techniques in Python


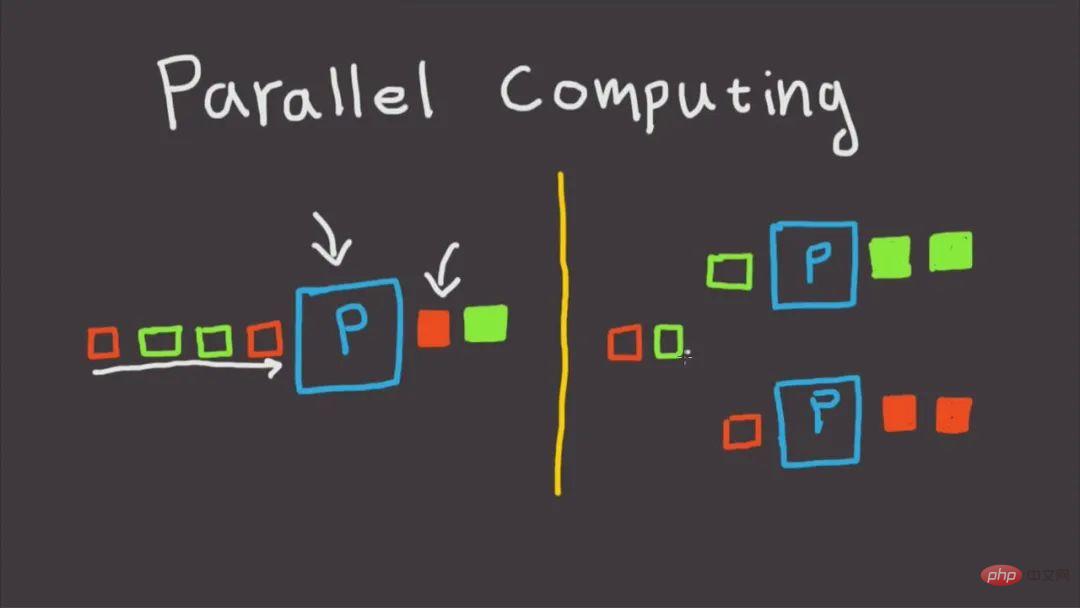
When we use Python on a daily basis to perform various data calculation and processing tasks, if we want to obtain obvious calculation acceleration effects, the simplest and clearest way is It is to find a way to extend the tasks that run on a single process by default to use multiple processes or multi-threads.
For those of us who are engaged in data analysis, it is particularly important to achieve equivalent acceleration operations in the simplest way, so as to avoid spending too much time on writing programs. In today's article, Mr. Fei, I will teach you how to use the relevant functions in joblib, a very simple and easy-to-use library, to quickly achieve parallel computing acceleration effects.
As a widely used third-party Python library (for example, joblib is widely used in the scikit-learn project framework (parallel acceleration of many machine learning algorithms), we can use pip install joblib to install it. After the installation is complete, let’s learn about the common methods of parallel operations in joblib:
To implement parallel computing in joblib, you only need to use its Parallel and delayed methods. It is very simple and convenient to use. Let’s demonstrate it directly with a small example:
joblib implementation The idea of parallel computing is to schedule a set of serial computing subtasks generated through loops in a multi-process or multi-thread manner. All we need to do for custom computing tasks is to encapsulate them into functions. Yes, for example:
import time def task_demo1(): time.sleep(1) return time.time()
Then you only need to set the relevant parameters for Parallel() as shown below, and then connect the loop to create the list derivation process of the subtask, in which delayed() is used to wrap the custom task function. Then connect () to pass the parameters required by the task function. The n_jobs parameter is used to set the number of workers to execute parallel tasks at the same time. Therefore, in this example, you can see that the progress bar increases in groups of 4. You can see The final time overhead also achieved the parallel acceleration effect:
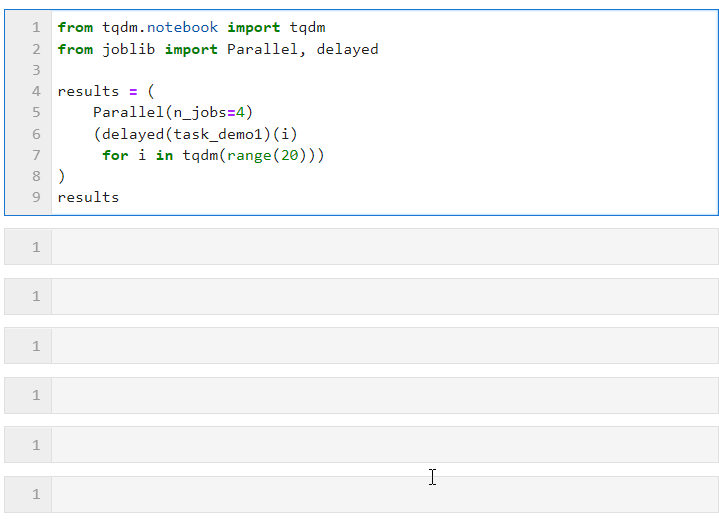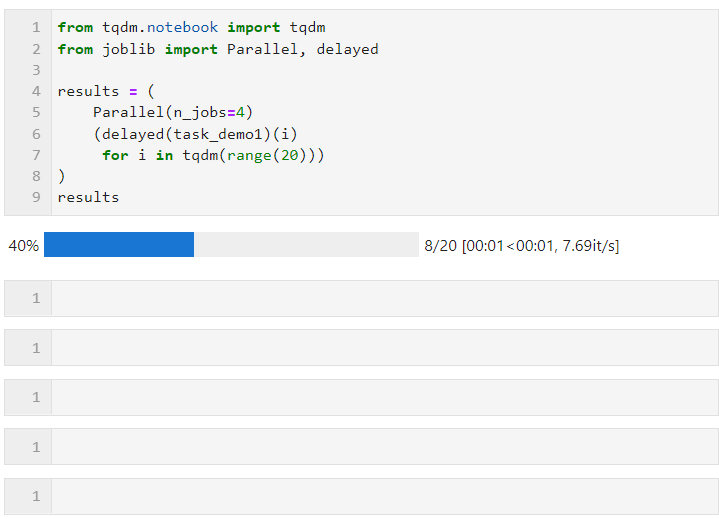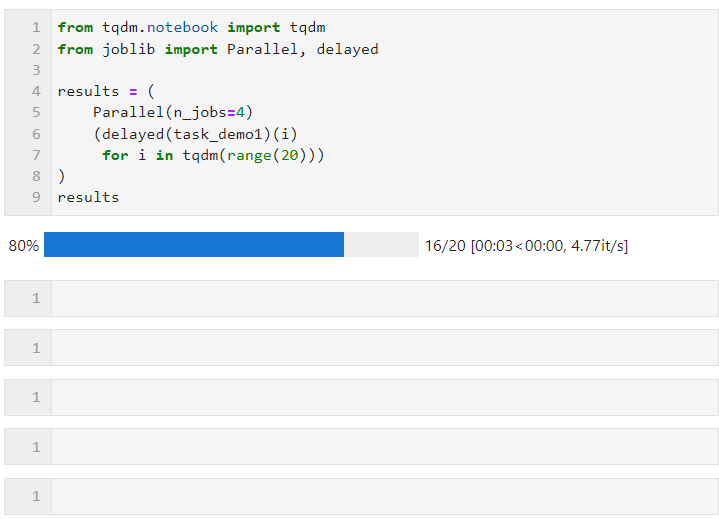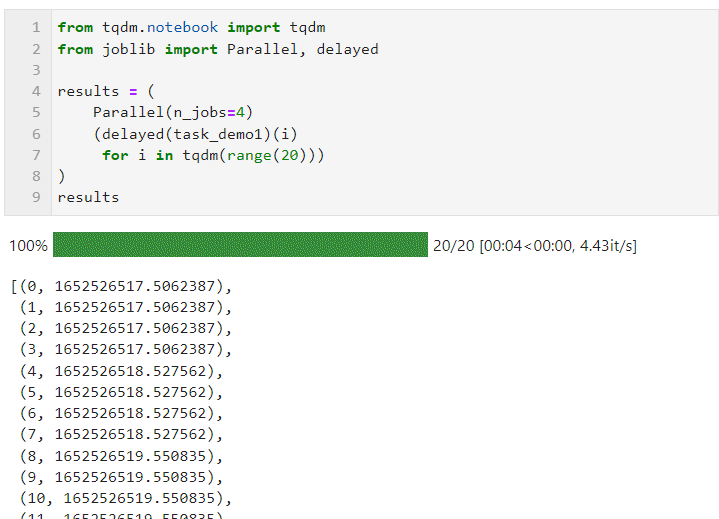
The parameters for Parallel() can be adjusted according to the specific conditions of the computing task and the number of machine CPU cores. The core parameters are:
For example, in the following example, on my machine with 8 logical cores, two cores are reserved for parallel computing:
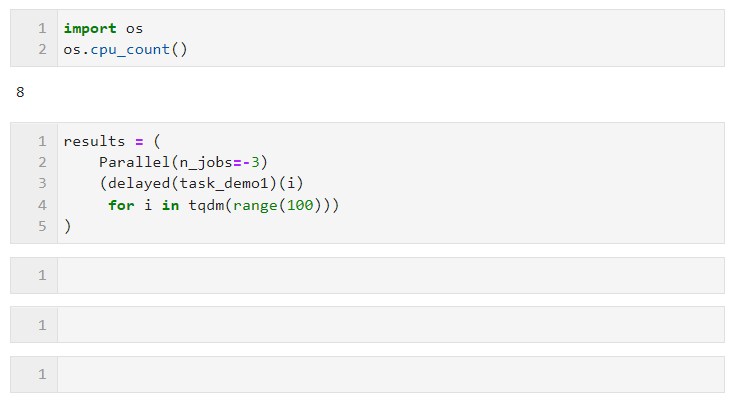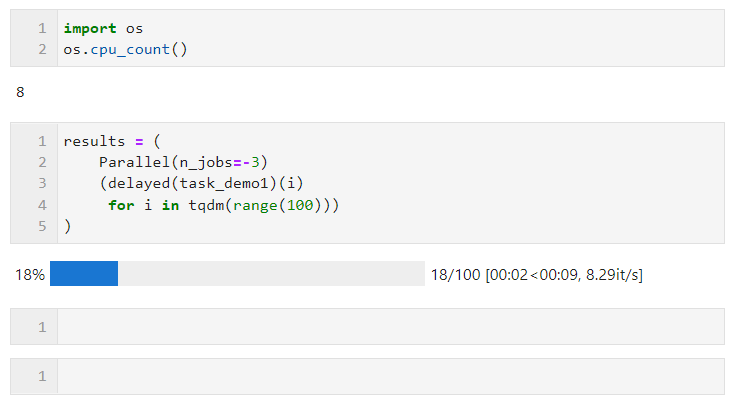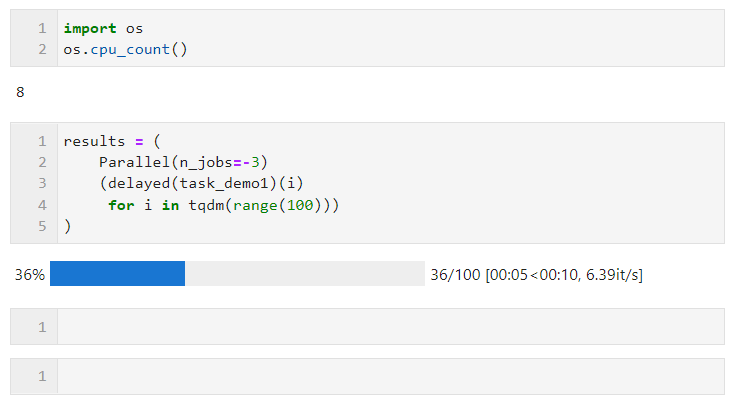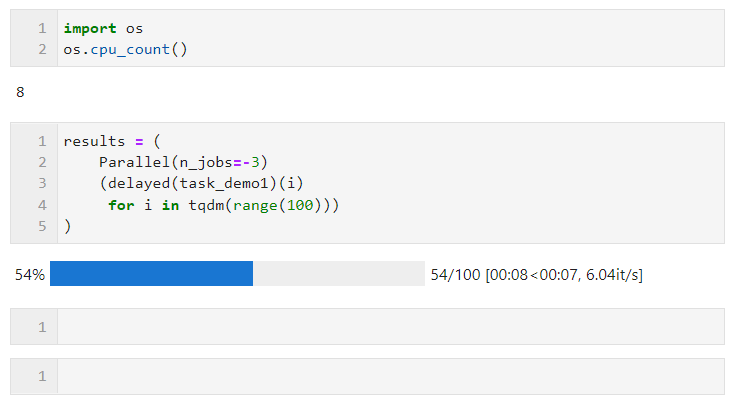
Regarding the choice of parallel mode, due to the limitation of the global interpreter lock when multi-threading in Python, if your task is computationally intensive, it is recommended to use the default multi-process mode to accelerate. If your task is IO intensive, such as file reading, Writing, network requests, etc., multi-threading is a better way and n_jobs can be set very large. As a simple example, you can see that through multi-threading parallelism, we completed 1,000 requests in 5 seconds. , much faster than the result of 100 requests in 17 seconds in a single thread (this example is for reference only, please do not visit other people’s websites too frequently when learning and trying):
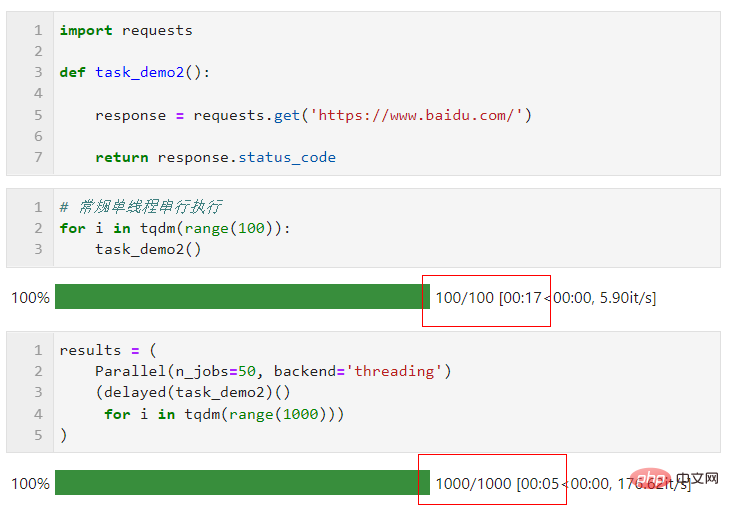
You can make good use of joblib to speed up your daily work according to your actual tasks.
The above is the detailed content of Simple and easy-to-use parallel acceleration techniques in Python. For more information, please follow other related articles on the PHP Chinese website!