
Home > Article > Backend Development > IP automatic proxy example in python crawling technology

I recently planned to crawl soft exam questions on the Internet for the exam, and encountered some problems during the crawling. The following article mainly introduces the use of python to crawl soft exam questions and the relevant information of IP automatic proxy. The article introduces it in great detail. , friends who need it can come and take a look below.
Preface
There is a software professional level exam recently, hereafter referred to as the soft exam. In order to better review and prepare for the exam, I plan to grab www. Soft test questions on rkpass.cn.
First of all, let me tell you the story (keng) about how I crawled the soft exam questions. Now I can automatically capture all the questions in a certain module, as shown below:
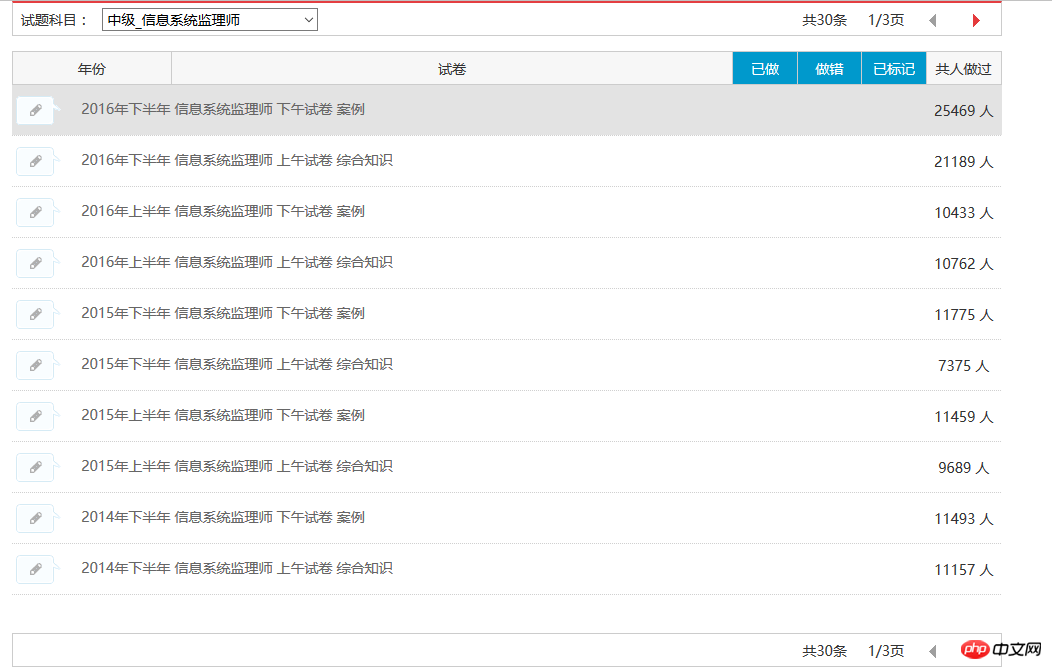
Currently, I can capture all 30 test question records of the information system supervisor. The result is as shown below:
The captured content picture:

Although some information can be captured However, the quality of the code is not high. Take the capture information system supervisor as an example. Because the goal is clear and the parameters are clear, in order to capture the test paper information in a short time, no exception handling is done. Yesterday I have been filling in the hole for a long time at night.
Back to the topic, I am writing this blog today because I have encountered a new pitfall. From the title of the article, we can guess that there must have been too many requests, so the IP was blocked by the anti-crawler mechanism of the website.
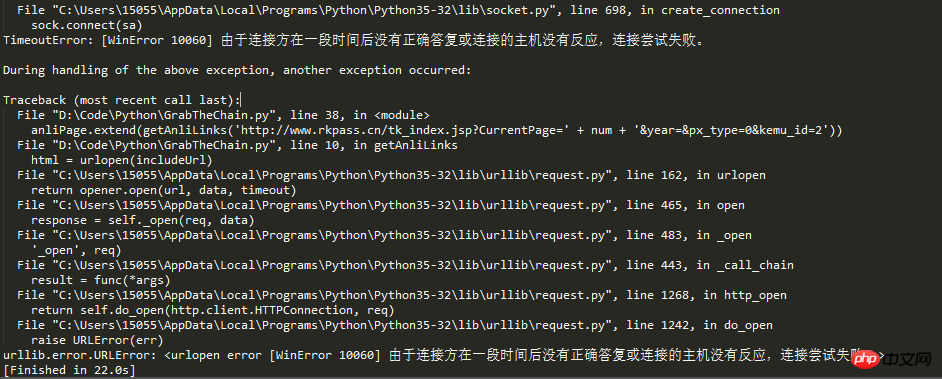
Living people cannot suffocate to death. The deeds of our revolutionary ancestors tell us that as the successors of socialism, we cannot succumb to difficulties, open roads across mountains and build bridges across rivers. , in order to solve the IP problem, the idea of IP proxy came out.
During the process of web crawlers capturing information, if the crawling frequency exceeds the website's set threshold, access will be prohibited. Usually, the website's anti-crawler mechanism identifies crawlers based on IP.
So crawler developers usually need to take two methods to solve this problem:
1. Slow down the crawling speed and reduce the pressure on the target website. But this will reduce the amount of crawling per unit time.
2. The second method is to break through the anti-crawler mechanism and continue high-frequency crawling by setting proxy IP and other means. But this requires multiple stable proxy IPs.
Not much to say, just go to the code:
# IP地址取自国内髙匿代理IP网站:www.xicidaili.com/nn/
# 仅仅爬取首页IP地址就足够一般使用
from bs4 import BeautifulSoup
import requests
import random
#获取当前页面上的ip
def get_ip_list(url, headers):
web_data = requests.get(url, headers=headers)
soup = BeautifulSoup(web_data.text)
ips = soup.find_all('tr')
ip_list = []
for i in range(1, len(ips)):
ip_info = ips[i]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
return ip_list
#从抓取到的Ip中随机获取一个ip
def get_random_ip(ip_list):
proxy_list = []
for ip in ip_list:
proxy_list.append('http://' + ip)
proxy_ip = random.choice(proxy_list)
proxies = {'http': proxy_ip}
return proxies
#国内高匿代理IP网主地址
url = 'http://www.xicidaili.com/nn/'
#请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36'}
#计数器,根据计数器来循环抓取所有页面的ip
num = 0
#创建一个数组,将捕捉到的ip存放到数组
ip_array = []
while num < 1537:
num += 1
ip_list = get_ip_list(url+str(num), headers=headers)
ip_array.append(ip_list)
for ip in ip_array:
print(ip)
#创建随机数,随机取到一个ip
# proxies = get_random_ip(ip_list)
# print(proxies)Screenshot of the running result:
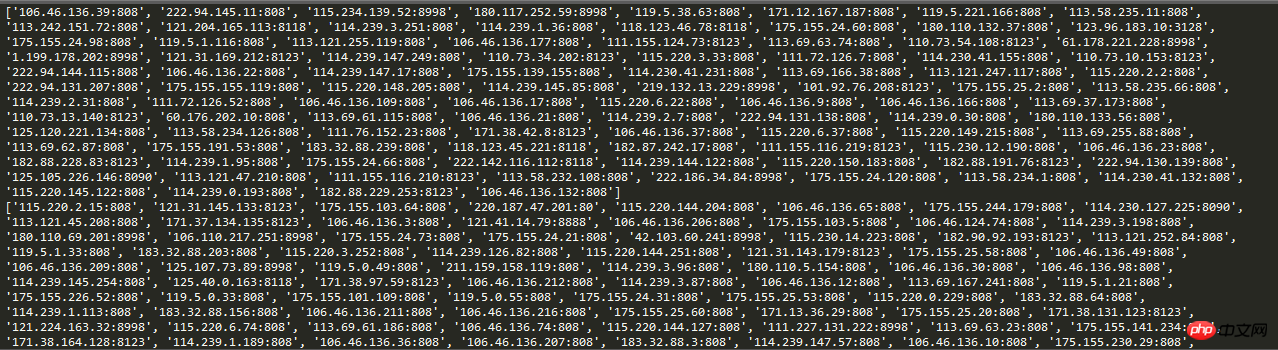
In this way, when the crawler requests, Setting the request IP to automatic IP can effectively avoid the simple blocking of fixed IP in the anti-crawler mechanism.
-------------------------------------------------- -------------------------------------------------- ---------------------------------------
For the stability of the website, Everyone should keep the speed of the crawler under control, after all, it is not easy for webmasters either. The test in this article only captured 17 IP pages.
Summarize
The above is the detailed content of IP automatic proxy example in python crawling technology. For more information, please follow other related articles on the PHP Chinese website!