


Related free learning recommendations: mysql video tutorial
In a relational database, an index is a separate, physical storage structure that sorts the values of one or more columns in a database table. It is a collection of the values of one or several columns in a table. Collection and corresponding list of logical pointers to the data pages in the table that physically identify these values. The index is equivalent to the table of contents of a book. You can quickly find the required content based on the page numbers in the table of contents.
When there are a large number of records in the table, if you want to query the table, the first way to search for information is to search the whole table, which is to take out all the records one by one, compare them one by one with the query conditions, and then return Records that meet the conditions will consume a lot of database system time and cause a lot of disk I/O operations; the second is to create an index in the table, then find the index value that meets the query conditions in the index, and finally save it in the index The ROWID (equivalent to the page number) in the table can quickly find the corresponding record in the table.
The index data structure used by the InnoDB storage engine after MySQL5.5 mainly uses: B Tree; this article will take you to talk about the past and present life of B Tree;
**Mark**
:
B Tree can be used for , >=, BETWEEN, IN , and LIKE usage indexes that do not start with a wildcard. (After MySQL 5.5)
These facts may subvert some of your perceptions, such as in other articles or books you have read. All of the above are "range queries" and are not indexed!
That’s right, before 5.5, the optimizer would not choose to search through the index. The optimizer believed that the rows retrieved in this way were more than those of the full table scan, because it would have to go back to the table to check again, which may involve The number of I/O rows is larger and is abandoned by the optimizer.
After optimization of the algorithm (B Tree), it supports scanning of some range types (taking advantage of the orderliness of the B Tree data structure). This approach also violates the leftmost prefix principle, resulting in the condition after the range query being unable to use the joint index, which we will explain in detail later.
Therefore, only the most frequently queried and most frequently sorted data columns should be indexed. (The total number of indexes in the same data table in MySQL is limited to 16)
One of the meanings of the existence of a database is to solve data storage and fast search. So where does the data in the database exist? That's right, it's a disk. What are the advantages of a disk? Cheap! What about the disadvantages? Slower than memory access.
So do you know the data structures mainly used by MySQL indexes?
B tree! you blurt out.
What kind of data structure is the B-tree? Why did MySQL choose B-tree for index?
In fact, the final choice of B-tree went through a long process of evolution:
# A friend asked me “What is the difference between B-tree and B-tree?” ? To generalize here, MySQL data structures only have B-Tree (B tree) and B Tree (B tree). Most of them are just different pronunciations. "B-Tree" is generally called B-tree. You can also call it B-tree~ ~ Also, the red-black tree mentioned by a friend is a storage structure in a programming language, not MySQL; for example, Java's HashMap uses a linked list plus a red-black tree. Okay, today I will take you through the process of evolving into a B-tree.#Binary sorting tree → Binary balanced tree → B-Tree(B tree) → B Tree(B tree)
Before understanding the B-tree, let’s briefly talk about the binary sorting tree. For a node, its left child The value of the child node of the tree must be less than itself, and the value of the child node of its right subtree must be greater than itself. If all nodes meet this condition, then it is a binary sorted tree. (Here you can string together the knowledge points of binary search) 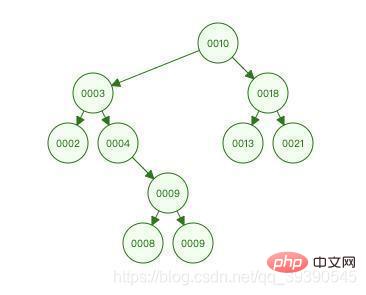
The picture above is a binary sorting tree. You can try to use its characteristics to experience the process of finding 9:
Compared 4 times in total, then you Have you ever thought about how to optimize the above structure?
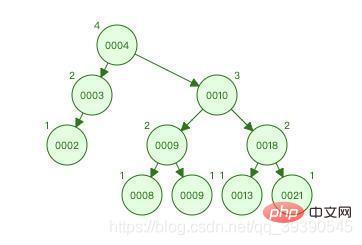
The above picture is an AVL tree. The number and value of nodes are equal to the binary sorting tree. Exactly the same
Let’s look at the process of finding 9:
. It has been compared a total of 3 times, and the same amount of data is once less than the binary sorting tree. Why? ? Because the height of the AVL tree is smaller than that of the binary sorting tree, the higher the height, the more the number of comparisons. Don’t underestimate this optimization. If it is 2 million pieces of data, the number of comparisons will be significantly different.
You can imagine a balanced binary tree with 1 million nodes and a tree height of 20. A query may need to access 20 data blocks. In the era of mechanical hard disks, it took about 10 ms of seek time to randomly read a data block from the disk. In other words, for a table with 1 million rows, if a binary tree is used to store it, it may take 20 10 ms to access a single row. This query is really slow!
B-tree is a multi-way self-balancing search tree. It is similar to an ordinary binary tree, but the B tree allows Each node has more child nodes. The schematic diagram of the B-tree is as follows:
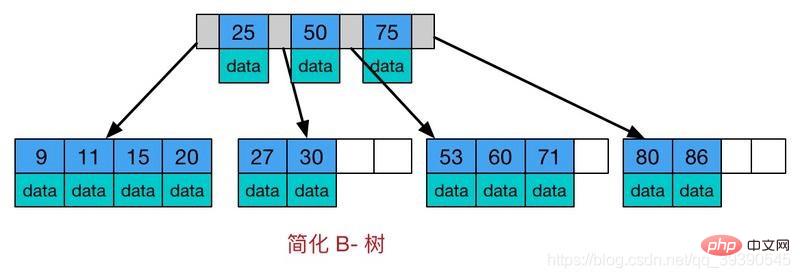
Characteristics of the B-tree:
In order to improve efficiency, the number of disk I/Os should be reduced as much as possible. In the actual process, the disk is not read strictly on demand every time, but is read ahead every time.
After the disk reads the required data, it will read some more data into the memory in order. The theoretical basis for this is the locality principle noted in computer science:
B-Tree uses the computer disk read-ahead mechanism:
Every time a new node is created, a page of space is applied for, so each time a node is searched, only one I/ O;Because in actual applications, the node depth will be very small, so the search efficiency is very high.
So how is the final version of the B-tree made?
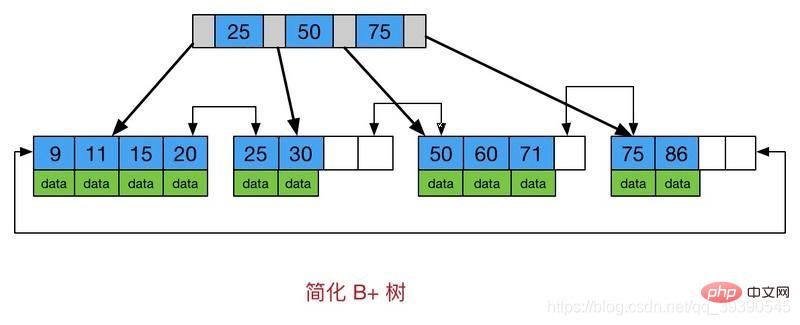
You can also see from the picture , The difference between B-tree and B-tree is:
** Therefore, B Tree can use indexes for , >=, BETWEEN, IN, and LIKE that does not start with a wildcard character. **
Advantages of B tree:
The number of comparisons is balanced, reducing the number of I/Os, improving the search speed, and making the search more stable.
What you need to know is that every time you create a table, the system will Automatically create an ID-based clustered index (the above-mentioned B-tree) for you to store all data; every time you add an index, the database will create an additional index for you (the above-mentioned B-tree), and the number of fields selected by the index is each The number of node storage data indexes. Note that this index does not store all data.
For example, if you create name, age index name_age_index, query the data
select * from table where name ='陈哈哈' and age = 26; 1复制代码
is used because there are only name and age in the additional index. Therefore, after hitting the index, the database must go back to the clustered index to find other data. This is table return. This is also the one you memorize: use less The reason for select *.
It will be better understood when combined with the return table. For example, in the above name_age_index index, there is a query
select name, age from table where name ='陈哈哈' and age = 26; 1复制代码
At this time, the selected field name, age is in the index name_age_index can be obtained, so there is no need to return to the table, index coverage is satisfied, and the data in the index is returned directly, which is highly efficient. It is the preferred optimization method for DBA students when optimizing.
The node storage index order of the B tree is stored from left to right. When matching, it is natural to satisfy the left-to-right matching; usually when we create When jointly indexing, that is, indexing multiple fields. I believe students who have established indexes will find that both Oracle and MySQL will let us choose the order of the index. For example, we want to index the three fields a, b, and c. To create a joint index, we can choose the priority we want, a, b, c, or b, a, c or c, a, b, etc. in order. Why does the database let us choose the order of fields? Aren’t they all joint indexes of three fields? This leads to the principle of the leftmost prefix of database indexes.
In our development, we often encounter the problem that a joint index is built for this field, but the index is not used when SQL queries this field. For example, the index abc_index: (a, b, c) is a joint index of the three fields a, b, c. When the following sql is executed, the index abc_index cannot be hit;
select * from table where c = '1'; select * from table where b ='1' and c ='2'; 123复制代码
The following three situations will cause the index to be lost. :
select * from table where a = '1'; select * from table where a = '1' and b = '2'; select * from table where a = '1' and b = '2' and c='3'; 12345复制代码
Do you have any clues from the above two examples?
Yes, the index abc_index: (a,b,c) will only be used in three types of queries: (a), (a,b), and (a,b,c). In fact, there is a bit of ambiguity here. In fact, (a,c) will also be used, but only the a field index will be used, and the c field will not be used.
In addition, there is a special case. In the following type, only a and b will be indexed, and c will not be indexed.
select * from table where a = '1' and b > '2' and c='3'; 1复制代码
For a sql statement of the above type, after a and b are indexed, c is already out of order, so c cannot be indexed, and the optimizer will think that it is not as good as the full index. Table scan c field comes quickly.
**Leftmost prefix: As the name suggests, it means leftmost priority. In the above example, we created a_b_c multi-column index, which is equivalent to creating (a) single column index and (a, b) combined index. And (a,b,c) combination index. **
Therefore, when creating a multi-column index, the most frequently used column in the where clause should be placed on the far left according to business needs.
Or index name_age_index, the following sql
select * from table where name like '陈%' and age > 26; 1复制代码
This statement has two execution possibilities:
Obviously, the second method returns fewer rows to the table and the number of I/Os will also be reduced. This is index pushdown. So not all likes will not hit the index.
As long as the columns contain null values, they will not be included. In the index, as long as one column in the composite index contains a null value, then this column is invalid for this composite index. Therefore, we recommend not to let the default value of a field be null when designing the database.
对串列进行索引,如果可能应该指定一个前缀长度。例如,如果有一个char(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
查询只使用一个索引,因此如果where子句中已经使用了索引的话,那么order by中的列是不会使用索引的。因此数据库默认排序可以符合要求的情况下不要使用排序操作;尽量不要包含多个列的排序,如果需要最好给这些列创建复合索引。
一般情况下不推荐使用like操作,如果非使用不可,如何使用也是一个问题。like “%陈%” 不会使用索引而like “陈%”可以使用索引。
这将导致索引失效而进行全表扫描,例如
SELECT * FROM table_name WHERE YEAR(column_name)6、不使用not in和操作
这不属于支持的范围查询条件,不会使用索引。
我的体会
曾经,我一度以为我很懂MySQL。
刚入职那年,我还是个孩子,记得第一个需求是做个统计接口,查询近两小时每隔5分钟为一时间段的网站访问量,JSONArray中一共返回24个值,当时菜啊,写了个接口循环二十四遍,发送24条SQL去查(捂脸),由于那个接口,被技术经理嘲讽~~表示他写的SQL比我吃的米都多。虽然我们山东人基本不吃米饭,但我还是羞愧不已。。
然后经理通过调用一个dateTime函数分组查询处理一下,就ok了,效率是我的几十倍吧。从那时起,我就定下目标,深入MySQL学习,万一日后有机会嘲讽回去?筒子们,MySQL路漫漫,其修远兮。永远不要眼高手低,一起加油,希望本文能对你有所帮助。
The above is the detailed content of Cry..I thought I knew MySQL indexes well. For more information, please follow other related articles on the PHP Chinese website!