

This article brings you a basic introduction to MapReduce (with code). It has certain reference value. Friends in need can refer to it. I hope it will be helpful to you. .
1. WordCount program
1.1 WordCount source program
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount [...] ");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class TokenizerMapper extends Mapper {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
public static class IntSumReducer extends Reducer {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable values, Reducer.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
} 1.2 Run the program, Run As->Java Application
1.3 Compile and package Program to generate Jar files
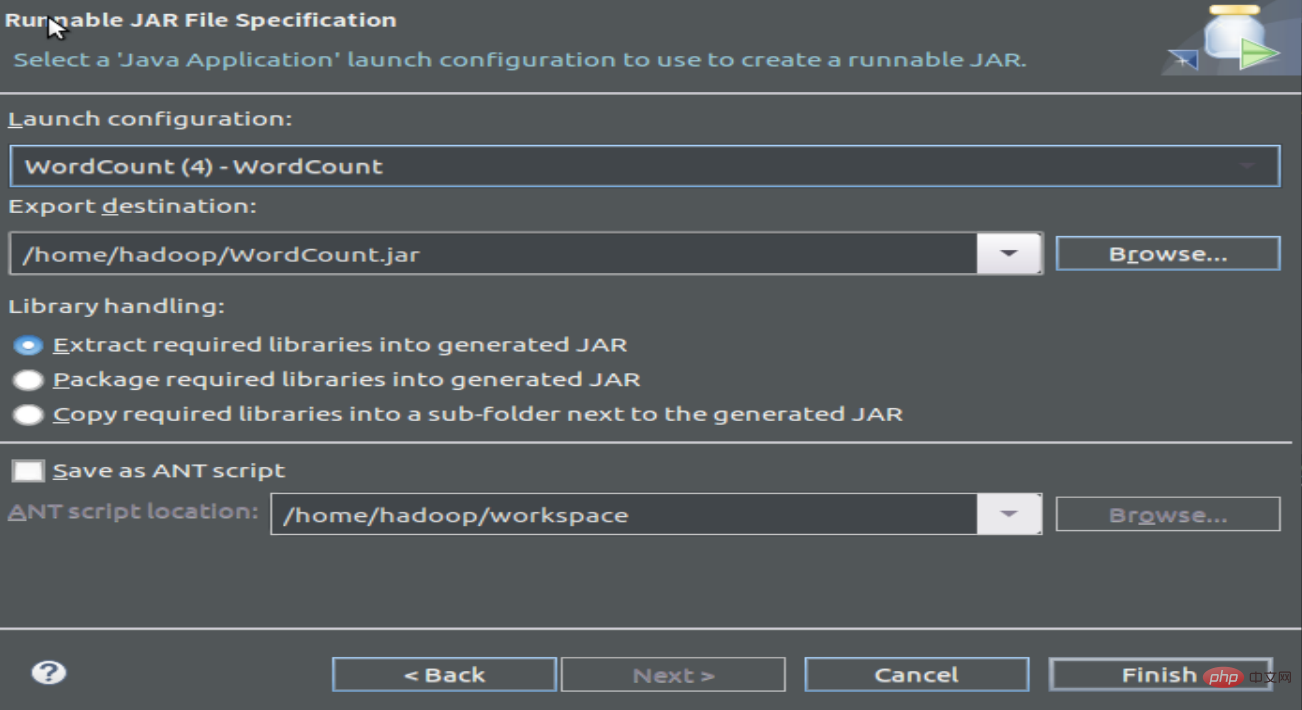
2 Run the program
2.1 Create a text file to count word frequency
wordfile1.txt
Spark Hadoop
Big Data
wordfile2.txt
Spark Hadoop
Big Cloud
2.2 Start hdfs and create a new input file folder, upload the word frequency file
cd /usr/local/hadoop/
./sbin/start-dfs.sh
./bin/hadoop fs -mkdir input
./bin/hadoop fs -put /home/hadoop/wordfile1.txt input
./bin/hadoop fs -put /home/hadoop/wordfile2.txt input
2.3 View the uploaded word frequency file:
hadoop@dblab-VirtualBox:/usr/local/hadoop$ ./bin/hadoop fs -ls .
Found 2 items
drwxr-xr- x - hadoop supergroup 0 2019-02-11 15:40 input
-rw-r--r-- 1 hadoop supergroup 5 2019-02-10 20:22 test.txt
hadoop@dblab-VirtualBox: /usr/local/hadoop$ ./bin/hadoop fs -ls ./input
Found 2 items
-rw-r--r-- 1 hadoop supergroup 27 2019-02-11 15:40 input/ wordfile1.txt
-rw-r--r-- 1 hadoop supergroup 29 2019-02-11 15:40 input/wordfile2.txt
2.4 Run WordCount
./bin /hadoop jar /home/hadoop/WordCount.jar input output
A large piece of information will be entered on the screen
Then you can view the running results:
hadoop@dblab-VirtualBox: /usr/local/hadoop$ ./bin/hadoop fs -cat output/*
Hadoop 2
Spark 2
The above is the detailed content of Introduction to the basic content of MapReduce (with code). For more information, please follow other related articles on the PHP Chinese website!