
Mysql database sub-database sub-table solution, once the database is too large, especially when writes are too frequent and it is difficult to be supported by one host, we will still face expansion bottlenecks. At this time, we must find other technical means to solve this bottleneck, which is the bad data segmentation technology we will introduce in this chapter.
The expansion achieved through the MySQLReplication function will always be limited by the size of the database. Once the database is too large, especially when writes are too frequent and it is difficult to be supported by one host, we will still face expansion bottlenecks. At this time, we must find other technical means to solve this bottleneck, which is the bad data segmentation technology we will introduce in this chapter.
Many readers may have seen related articles about data segmentation many times on the Internet or in magazines, but they are just called it in some articles. Sharding of data. In fact, whether it is called Sharding of data or segmentation of data, the concept is the same.
Simply put, it means that the data we store in the same database is dispersed and stored on multiple databases (hosts) through certain specific conditions, so as to achieve the effect of dispersing the load of a single device. Data segmentation can also improve the overall availability of the system after a single device crashes. Only some part of the overall data is unavailable, not all of the data.
The sharding of data is based on the type of its sharding rules. It can be divided into two segmentation modes.
One is to split it into different databases (hosts) according to different tables (or Schema). This kind of splitting can be called vertical (vertical) splitting of data. The other is to split the data in the same table into multiple databases (hosts) according to certain conditions based on the logical relationship of the data in the table. Such segmentation is called horizontal (horizontal) segmentation of data.
The biggest feature of vertical segmentation is that the rules are simple and the implementation is more convenient. It is especially suitable for very low coupling between various businesses. A system with very little interaction and very clear business logic. In such a system, it is very easy to split the tables used by different business modules into different databases. Split according to different tables. The impact on the application will also be smaller, and the splitting rules will be simpler and clearer.
Horizontal segmentation is compared to vertical segmentation. Relatively speaking, it is slightly more complicated. Since different data in the same table needs to be split into different databases, for the application, the splitting rules themselves are more complicated than splitting based on table names, and later data maintenance will also be more complicated. .
When the amount of data and access to one (or some) of our tables is particularly large, and it still cannot meet the performance requirements after vertically slicing it on an independent device, then we will Vertical and horizontal slicing must be combined. Cut vertically first, then horizontally. Only in this way can we solve the performance problem of such a very large table.
Below we conduct a corresponding analysis of the architecture implementation of the three data segmentation methods of vertical, horizontal, and combination.
Let’s first take a look at what the vertical segmentation of data is. Vertical slicing of data. It can also be called vertical segmentation. Think of a database as being made up of many "data chunks" (tables), one chunk at a time. We cut these "data chunks" vertically and spread them across multiple database hosts. Such a segmentation method is a vertical (longitudinal) data segmentation.
An application system with good architectural design. Its overall function must be composed of many functional modules. The data required by each functional module corresponds to one or more tables in the database.
In architectural design, the more unified and fewer the interaction points between each functional module, the lower the coupling of the system, and the better the maintainability and scalability of each module of the system. Such a system. It will be easier to achieve vertical segmentation of data.
When our functional modules are clearer and the coupling is lower, the rules for vertical data segmentation will be easier to define. The data can be segmented according to the functional modules. The data of different functional modules are stored in different database hosts, which can easily avoid the existence of cross-database Joins. At the same time, the system architecture is also very clear.
certainly. It is very difficult for a system to make the tables used by all functional modules completely independent, without the need to access each other's tables or the tables of two modules for Join operations. In this case, we must evaluate and weigh based on the actual application scenario. Decide whether to accommodate the application to store all related data of tables that need to be joined in the same database, or to let the application do many other things, that is, the program obtains data from different databases entirely through the module interface, and then in the program The Join operation is completed.
Generally speaking. Suppose it is a system with a relatively light load, and table associations are very frequent. Then the database may give way. The solution of merging several related modules together to reduce the work of the application can reduce the workload even more. is a feasible solution.
certainly. Through the concession of the database, allowing multiple modules to centrally share data sources, in fact, it briefly introduces the development of increased coupling of each module architecture, which may make the future architecture worse and worse. Especially when it reaches a certain stage of development, it is found that the database cannot bear the pressure brought by these tables. Have to face the time of splitting again. The cost of structural transformation may be much greater than the initial cost.
so. When the database is vertically segmented, how to segment it and to what extent is a challenging problem. It can only be done by balancing the costs and benefits of all aspects in actual application scenarios. Only then can you analyze a split plan that truly suits you.
For example, let’s briefly analyze the example database of the demonstration sample system used in this book. Then design a simple segmentation rule to perform a vertical split.
System functions can be basically divided into four functional modules: users, group messages, photo albums and events. For example, they correspond to the following tables:
1. User module table: user, user_profile, user_group, user_photo_album
2. Group discussion table: groups, group_message, group_message_content, top_message
3. Photo album related table: photo, photo_album, photo_album_relation, photo_comment
4. Event information table: event
At first glance, no module can exist independently from other modules , there are relationships between modules. Could it be that it cannot be divided?
Of course not. Let’s do a little more in-depth analysis and we can find that although the tables used by each module are related to each other, the related relationships are relatively clear and simple.
◆ The group discussion module and the user module are mainly related through user or group relationships. Generally, the association is done through the user's id or nick_name and the group's id. Implementing it through interfaces between modules won't cause too much trouble.
◆ The photo album module is only related to the user module through the user. The association between these two modules is basically related to the content through the user ID. Simple and clear, the interface is clear;
◆ The event module may be related to each module, but they only focus on the ID information of the objects in each module. It can also be split very easily.
so. Our first step can be to vertically split the database according to tables related to functional modules. The tables involved in each module are stored in a separate database, and the table relationships between modules are handled through interfaces on the application system side. For example, you can see it in the following picture:

After such vertical segmentation. Services that were previously only available through a database. It was split into four databases to provide services, and the service capabilities were naturally increased several times.
Advantages of vertical segmentation
◆ Database splitting is simple and clear, and the splitting rules are clear;
◆ Application modules are clear and easy to integrate.
◆ Data maintenance is convenient and easy to locate.
Disadvantages of vertical segmentation
◆ Some table associations cannot be completed at the database level. It needs to be completed in the program.
◆ For tables that are accessed extremely frequently and have large amounts of data, there is still a performance lull, which may not necessarily meet the requirements.
◆ Transaction processing is relatively more complex;
◆ After sharding reaches a certain level, scalability will encounter limitations;
◆ Over-read sharding may cause System transitions are complex and difficult to maintain.
It is very difficult to find a better solution at the database level for vertical segmentation that may encounter data segmentation and transaction problems. In actual application cases, the vertical segmentation of the database mostly corresponds to the modules of the application system. The data sources of the same module are stored in the same database, which can solve the problem of data association within the module. Between modules, the required data is provided to each other through application programs in the form of service interfaces.
Although this will indeed increase the overall number of operations on the database, it is intentional in terms of the overall scalability of the system and the modularization of the architecture. The single response time of some operations may be slightly increased. However, the overall performance of the system is very likely to be improved to a certain extent. And the expansion bottleneck problem. It can only be overcome by relying on the data horizontal segmentation architecture that will be introduced in the next section.
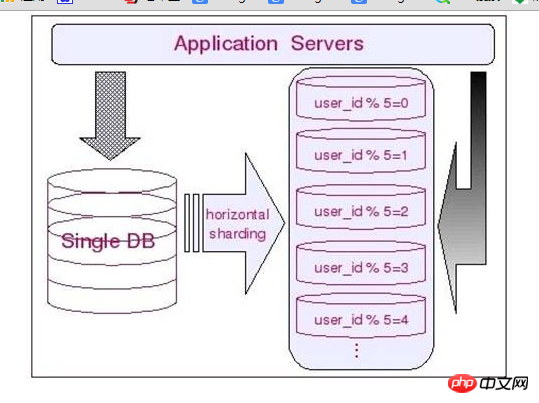
The above section analyzes and introduces the vertical segmentation of data. This section will analyze the horizontal segmentation of data. Vertical segmentation of data can basically be simply understood as segmenting data according to tables and modules, while horizontal segmentation is no longer segmented according to tables or functional modules. Generally speaking, simple horizontal sharding is mainly to disperse a table with extremely mediocre access into multiple tables according to certain rules of a certain field. Each table contains a portion of data.
simply put. We can understand the horizontal segmentation of data as segmentation according to data rows. It means that some rows in the table are split into one database, and some other rows are split into other databases. Of course, in order to easily determine which database each row of data is divided into, the division always needs to be carried out according to certain rules.
If a numeric type field is based on a specific number, the range of a time type field. Or the hash value of a character type field. It is assumed that most core tables in the entire system can be related through a certain field. Then this field is naturally the best choice for horizontal partitioning. Of course, if it is very special and cannot be used, you can only choose another one.
Generally speaking, Web2.0 type sites are very popular on the Internet today. Basically, most data can be associated through member user information, and many core tables may be very suitable for horizontal segmentation of data through member IDs.
And like the forum community discussion system. It is even easier to segment. It is very easy to horizontally segment the data according to the forum number.
There will basically be no interaction between libraries after segmentation.
Such as our demonstration sample system. All data is associated with users. Then we can perform horizontal splitting based on users and split the data of different users into different databases. Of course, the only difference is that the groups table in the user module is not directly related to users. Therefore, groups cannot be split horizontally based on users. For such special cases, we can completely stand alone. Separately placed in a separate database.
In fact, this approach can be said to make use of the "vertical segmentation of data" method introduced in the previous section. In the next section, I will introduce in more detail the joint segmentation method used at the same time for vertical segmentation and horizontal segmentation.
Therefore, for our demo sample database, most tables can be horizontally segmented based on user ID. Data related to different users is segmented and stored in different databases. For example, all user IDs are taken modulo 2 and then stored in two different databases.
Every table associated with a user ID can be segmented in this way. In this way, basically every user-related data. They are all in the same database, and even if they need to be related, they can be related very easily.
We can display the relevant information of horizontal segmentation more intuitively through the following figure: Advantages of horizontal segmentation
In the above two sections. We respectively learned about the implementation of the two segmentation methods of "vertical" and "horizontal" and the architectural information after segmentation. At the same time, the advantages and disadvantages of the two architectures were also analyzed. But in actual application scenarios, the load is not too large except for those. Systems with relatively simple business logic can solve scalability problems through one of the above two segmentation methods. I'm afraid that most other systems with a slightly more complex business logic and a larger system load cannot achieve better scalability through any of the above data segmentation methods. It is necessary to combine the above two segmentation methods, and use different segmentation methods in different scenarios.
In this section. I will combine the advantages and disadvantages of vertical slicing and horizontal slicing to further improve our overall architecture and further improve the scalability of the system.
Generally speaking. It is very difficult to connect all the tables in our database through one (or a few) fields, so it is very difficult to solve all problems simply by horizontal segmentation of data. Vertical sharding can only solve part of the problem. For systems with very high loads, even a single table cannot bear the load on a single database host.
We must combine the "vertical" and "horizontal" splitting methods at the same time to make full use of the strengths of both and avoid their shortcomings.
The load of each application system increases step by step. When they begin to encounter performance bottlenecks, most architects and DBAs will choose to vertically split the data first, because this cost is the highest. First. It is most in line with the maximum input-output ratio pursued during this period. However. As the business continues to expand. As the system load continues to grow, after the system is stable for a period of time, the database cluster that has been vertically split may be overwhelmed again and encounter a performance bottleneck.
How should we choose at this time? Should we further subdivide the modules again, or seek other solutions? Assuming that we continue to subdivide modules and perform vertical segmentation of data as we did at the beginning, we may encounter the same problems we are facing today in the near future. And with the continuous refinement of modules, the architecture of the application system will become more and more complex, and the entire system may very well get out of control.
At this time we must take advantage of the horizontal segmentation of data to solve the problems encountered here. Moreover, we do not need to overthrow the previous results of vertical data segmentation when using horizontal data segmentation. Instead, we use the advantages of horizontal segmentation to avoid the disadvantages of vertical segmentation. Solve the problem of expanding system complexity.
The disadvantages of horizontal splitting (the rules are difficult to unify) have also been solved by the previous vertical splitting. Make horizontal splitting easy.
For our demo sample database. Assume at the beginning. We performed vertical segmentation of data. However, as the business continued to grow, the database system encountered bottlenecks, so we chose to reconstruct the architecture of the database cluster. How to refactor? Considering that the vertical segmentation of data has been done before, and the module structure is clear.
And the momentum of business growth is getting stronger and stronger. Even if the modules are further split now, it will not last long.
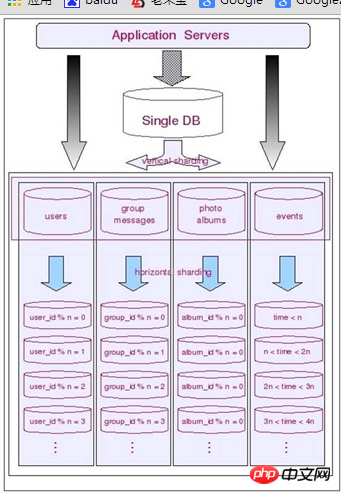
We chose to split horizontally based on vertical segmentation.
After experiencing vertical split, each database cluster has only one functional module. Basically, all tables in each functional module are associated with a certain field. For example, all user modules can be segmented by user ID, and group discussion modules can all be segmented by group ID. The photo album module is segmented based on the album ID. The final event notification information table takes into account the time limit of the data (only the information of a recent event segment will be accessed), so it is considered to be divided by time.
The following figure shows the entire architecture after segmentation:
In fact, in many large-scale application systems, vertical segmentation and horizontal segmentation are These two data segmentation methods basically coexist. And they are often carried out alternately to continuously add the expansion capabilities of the system. When we deal with different application scenarios, we also need to fully consider the limitations and advantages of these two segmentation methods. Use different bonding methods at different times (load pressure).
Advantages of joint sharding
◆ Can make full use of the advantages of vertical slicing and horizontal slicing to avoid their respective defects;
◆ Maximize the scalability of the system cultural improvement.
Disadvantages of joint segmentation
◆ The database system architecture is relatively complex. Maintenance is more difficult.
◆ The application architecture is also relatively more complex;
Through the previous chapters. We have already made it very clear that data segmentation through the database can greatly improve the scalability of the system. However, after the data in the database is stored in different database hosts through vertical and/or horizontal segmentation, the biggest problem faced by the application system is how to better integrate these data sources. Perhaps this is also an issue that many readers are very concerned about. Our main focus in this section is to analyze the various overall solutions that can be used to help us achieve data segmentation and data integration.
It is very difficult to integrate data by relying on the database itself to achieve this effect, although MySQL has a Federated storage engine that can solve some similar problems. However, it is very difficult to use it well in actual application scenarios. So how do we integrate these data sources scattered on various MySQL hosts?
In general, there are two solutions:
1. Configure and manage one (or more) data sources you need in each application module. Directly access each database and complete data integration within the module;
2. Unify management of all data sources through the intermediate proxy layer. The back-end database cluster is transparent to the front-end application;
Maybe more than 90% of people will tend to choose the other when facing the above two solutions, especially as the system continues to become larger and more complex. when.
really. This is a very correct choice. Although the short-term cost may be relatively larger, it is very helpful for the scalability of the entire system.
Therefore, I will not prepare too much analysis on the first solution idea here. Below I will focus on analyzing some solutions in another solution idea.
★ Develop your own intermediate proxy layer
After deciding to use the intermediate proxy layer of the database to solve the architectural direction of data source integration, many companies (or enterprises) have chosen to develop it yourself. Proxy layer applications that meet specific application scenarios.
By developing your own intermediate proxy layer, you can respond to the specificities of your own applications to the greatest extent. Maximized customization meets individual needs and can flexibly respond to changes. This should be said to be the biggest advantage of developing your own proxy layer.
Of course, while choosing to develop by yourself and enjoy the fun of maximizing personalized customization, you will naturally need to invest a lot of other costs in early research and development and subsequent continuous upgrades and improvements. And the technical threshold itself may be higher than that of simple web applications. Therefore, before deciding to develop it yourself, you still need to conduct a more comprehensive evaluation.
Since many times when doing self-development, you consider how to better adapt to your own application system and cope with your own business scenarios, so it is not easy to analyze too much here. Later, we will mainly analyze several currently popular data source integration solutions.
★Use MySQLProxy to achieve data segmentation and integration
MySQLProxy is a database proxy layer product officially provided by MySQL. Like MySQLServer, it is also an open source product based on the GPL open source agreement. Can be used to monitor, analyze or transmit communication information between them. Its flexibility allows you to use it to the maximum extent. Its current functions mainly include connection routing, Query analysis, Query filtering and modification, and load balancing. As well as the main HA mechanism, etc.
In fact, MySQLProxy itself does not have all of the above functions. Instead, it provides the basis for implementing the above functions.
To realize these functions, we need to write LUA scripts ourselves.
MySQLProxy actually establishes a connection pool between the client request and MySQLServer. All client requests are sent to MySQLProxy, and then the corresponding analysis is performed through MySQLProxy. It is inferred whether it is a read operation or a write operation, and distributed to the corresponding MySQL Server. For multi-node Slave clusters, load balancing can also be achieved. The following is the basic architecture diagram of MySQLProxy:
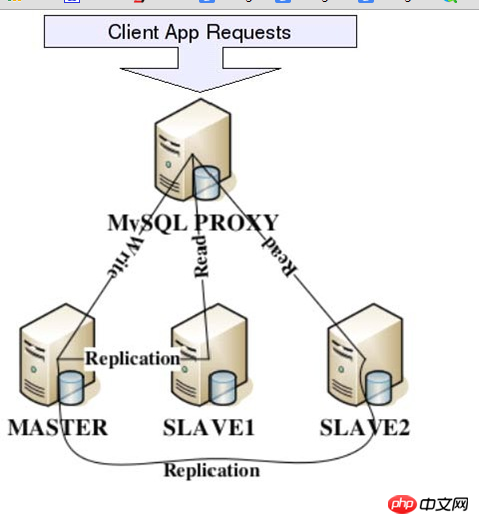
Through the above architecture diagram. We can very clearly see the position of MySQLProxy in practical applications and the basic things it can do.
About the more specific implementation details of MySQLProxy, there are very specific introductions and demonstration examples in the official MySQL documentation. Interested readers can download it for free directly from the MySQL official website or read it online. I will not go into the waste of paper here.
★Use Amoeba to achieve data segmentation and integration
Amoeba is an open source framework developed based on Java and focused on solving distributed database data source integration Proxy programs. It is based on the GPL3 open source agreement. At present, Amoeba already has Query routing, Query filtering, read-write separation, load balancing and HA mechanism and other related content.
Amoeba mainly solves the following problems:
1. Integrate complex data sources after data segmentation;
2. Provide data segmentation rules and reduce data segmentation The impact of rules on the database.
3. Reduce the number of connections between the database and the client.
4. Read-write separation routing;
We can see that what Amoeba does is exactly what we need to improve the scalability of the database through data segmentation.
Amoeba is not a proxy layer Proxy program, but a development framework for developing database proxy layer Proxy programs. Currently, there are two Proxy programs developed based on Amoeba: AmoebaForMySQL and AmoebaForAladin.
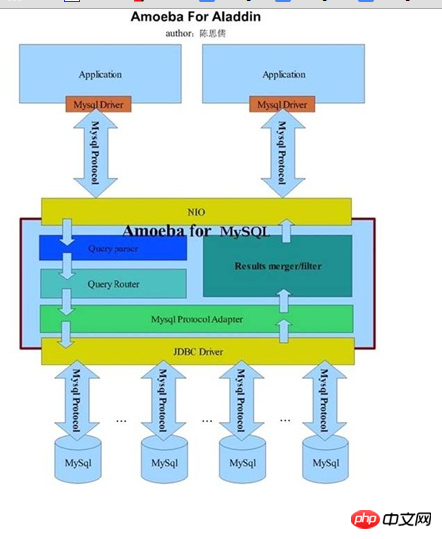
AmoebaForMySQL is mainly a solution specifically for MySQL database. The protocol requested by the front-end application and the data source database connected by the back-end must be MySQL. For any client application, there is no difference between AmoebaForMySQL and a MySQL database. Any client request using the MySQL protocol can be parsed by AmoebaForMySQL and processed accordingly. The following can tell us the architectural information of AmoebaForMySQL (from the Amoeba developer blog):
AmoebaForAladin is more widely applicable. A more powerful Proxy program.
He can connect to data sources in different databases at the same time to provide services for front-end applications, but only accepts client application requests that comply with the MySQL protocol. In other words, as long as the front-end application is connected through the MySQL protocol, AmoebaForAladin will actively analyze the Query statement and automatically identify the data source of the Query based on the data requested in the Query statement. On a physical host. The following figure shows the architectural details of AmoebaForAladin (from the Amoeba developer blog):
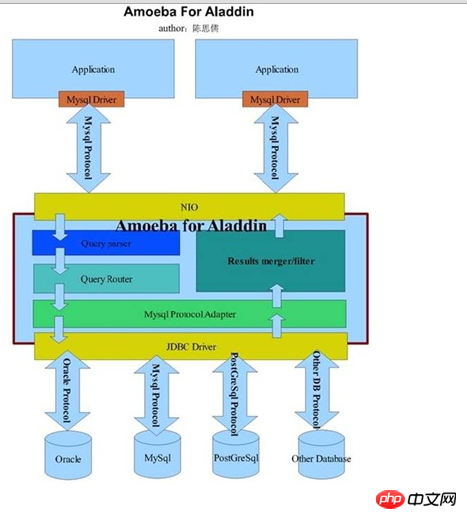
At first glance, the two seem to be exactly the same. After taking a closer look, you will find that the main difference between the two is only after processing through MySQLProtocalAdapter. The data source database is inferred based on the analysis results. Then select a specific JDBC driver and corresponding protocol to connect to the back-end database.
In fact, through the above two architecture diagrams, you may have discovered the characteristics of Amoeba. It is just a development framework. In addition to the two products he has provided, ForMySQL and ForAladin. It can also carry out corresponding secondary development based on its own needs. Get a Proxy program that is more suitable for our own application characteristics.
When using MySQL database. Both AmoebaForMySQL and AmoebaForAladin can be used very well. Of course, considering that the more complex a system is, its performance will definitely suffer a certain loss, and the maintenance cost will naturally be relatively higher. Therefore, when you only need to use the MySQL database, I still recommend using AmoebaForMySQL.
AmoebaForMySQL is very simple to use. All configuration files are standard XML files, and there are four configuration files in total. They are:
◆ amoeba.xml: main configuration file, configures all data sources and Amoeba's own parameter settings.
◆ rule.xml: Configure all Query routing rule information.
◆ functionMap.xml: Configure the Java implementation class corresponding to the function in Query;
◆ rullFunctionMap.xml: Configure the implementation class of specific functions that need to be used in routing rules ;
If your rules are not too complicated, basically you only need to use the first two of the above four configuration files to complete all the work. Features often used by Proxy programs include separation of reading and writing. Load balancing and other configurations are performed in amoeba.xml. also. Amoeba already supports its own active routing that implements vertical and horizontal sharding of data. Routing rules can be set in rule.xml.
The main shortcomings of Amoeba at the moment are its online management functions and support for transactions. I have made relevant suggestions during the communication process with relevant developers in the past, and I hope to provide a system that can perform online maintenance and management. The command line management tool is convenient for online maintenance. The feedback received is that a dedicated management module has been included in the development schedule. In addition, in terms of transaction support, Amoeba is still unable to do so. Even if the client application includes transaction information in the request submitted to Amoeba, Amoeba will ignore the transaction-related information. Of course, after continuous improvement, I believe that transaction support is definitely a feature that Amoeba will consider adding.
Readers who have more specific usage of Amoeba can obtain it through the user manual provided on the Amoeba developer blog (http://amoeba.sf.net), which will not be described in detail here.
★Use HiveDB to achieve data segmentation and integration
Like the previous MySQLProxy and Amoeba, HiveDB is also an open source framework based on Java that provides data segmentation and integration for MySQL databases. However, HiveDB currently only supports horizontal segmentation of data.
Mainly solves the problem of database scalability and high-performance data access under large data volumes, while supporting data redundancy and the main HA mechanism.
The implementation mechanism of HiveDB is somewhat different from MySQLProxy and Amoeba. It does not use MySQL's Replication function to achieve data redundancy, but implements its own data redundancy mechanism, and its underlying layer is mainly based on HibernateShards To achieve data segmentation work.
In HiveDB, data is dispersed into multiple MySQL Servers through various Partitionkeys defined by the user (in fact, it is the formulation of data segmentation rules). At the time of visit. When executing a Query request. It will actively analyze the filter conditions by itself, read data from multiple MySQL Servers in parallel, and merge the result sets and return them to the client application.
Purely from a functional perspective, HiveDB may not be as powerful as MySQLProxy and Amoeba, but its data segmentation ideas are not essentially different from the previous two. In addition, HiveDB is not just content shared by open source enthusiasts, but an open source project supported by commercial companies.
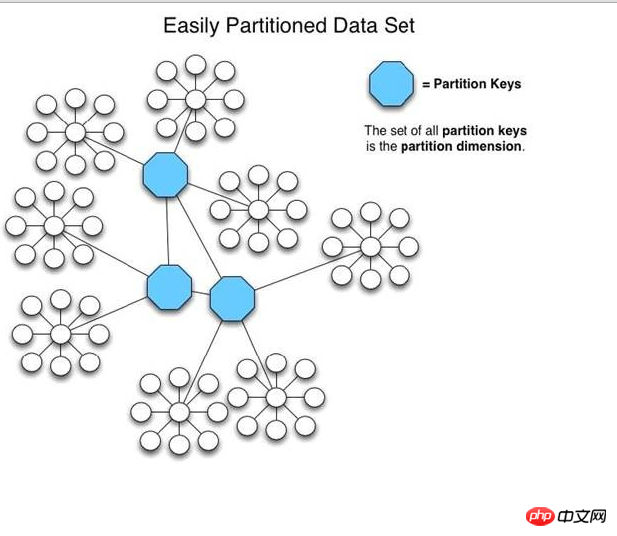
The following is a picture from the first chapter of the HiveDB official website, which describes the basic information about how HiveDB organizes data. Although it cannot specifically show too much architectural information, it can basically show its use in data. A unique aspect of segmentation.
★ mycat data integration: specific http://www.songwie.com/articlelist/11
★ Other solutions to achieve data segmentation and integration Method
In addition to the several overall solutions for data segmentation and integration introduced above, there are many other solutions that provide the same data segmentation and integration. For example, HSCALE is further expanded based on MySQLProxy, and SpockProxy is built through Rails. As well as Pathon-based Pyshards and more.
No matter which solution you choose to use, the overall design idea should basically not change at all. That is to enhance the overall service capabilities of the database through vertical and horizontal segmentation of data, so that the overall scalability of the application system can be improved as much as possible. The expansion method is as convenient as possible.
As long as we use the middle layer Proxy application to better overcome the problems of data segmentation and data source integration. Then the linear scalability of the database will be very easy to be as convenient as our application. Just by adding a cheap PCServerserver, the overall service capacity of the database cluster can be linearly increased, so that the database no longer easily becomes the performance bottleneck of the application system.
Here. Everyone should have a certain understanding of the implementation of data segmentation and integration. Perhaps many readers and friends have basically selected a solution suitable for their own application scenarios based on the advantages and disadvantages of the respective characteristics of various solutions. The subsequent work is mainly implementation preparation.
Before implementing the data segmentation plan, we still need to do some analysis on some possible problems.
Generally speaking, the main problems we may encounter are as follows:
◆ The problem of introducing distributed transactions.
◆ Cross-node Join problem;
◆ Cross-node merge sorting and paging problem.
1. Introducing the problem of distributed transactions
Once the data is split and stored in multiple MySQLServers, no matter how perfect our splitting rules are designed (actually it is not There is no perfect segmentation rule), it may cause that the data involved in some previous transactions is no longer in the same MySQL Server.
In this scenario, assume that our application still follows the old solution. Then it is necessary to introduce distributed transactions to solve it. Among the various versions of MySQL, only versions starting from MySQL 5.0 have begun to provide support for distributed transactions, and currently only Innodb provides distributed transaction support. Not only that. Even if we happen to be using a MySQL version that supports distributed transactions. At the same time, the Innodb storage engine was also used. Distributed transactions themselves consume a lot of system resources, and the performance itself is not too high. And the introduction of distributed transactions itself will bring more factors that are difficult to control in terms of exception handling.
what to do? In fact, we can solve this problem through a workaround. The first thing to consider is: Is the database the only place where transactions can be resolved? In fact, this is not the case. We can completely solve the problem by combining both the database and the application. Each database handles its own affairs. Then use the application to control transactions on multiple databases.
That is to say. Just if we want to. It is completely possible to split a distributed transaction across multiple databases into multiple small transactions that only exist on a single database. And use the application to control various small transactions.
Of course, the requirement for this is that our Russian application must be robust enough. Of course, it will also bring some technical difficulties to the application.
2. Cross-node Join issues
The above introduces the issues that may introduce distributed transactions. Now let’s look at the issues that require cross-node Join.
After data segmentation. This may cause some old Join statements to no longer be used. Because the data source used by Join may be split into multiple MySQL Servers.
what to do? From the perspective of the MySQL database, if this problem has to be solved directly on the database side, I am afraid it can only be overcome through Federated, a special storage engine of MySQL. The Federated storage engine is MySQL's solution to problems similar to Oracle's DBLink.
The main difference between Federated and OracleDBLink is that Federated will save a copy of the definition information of the remote table structure locally. At first glance, Federated is indeed a very good solution to cross-node Join. But we should also be clear. It seems that if the remote table structure changes, the local table definition information will not change accordingly. It is assumed that the local Federated table definition information is not updated when updating the remote table structure. It is very likely that Query execution errors will occur and correct results will not be obtained.
To deal with this kind of problem, I still recommend handling it through the application program. First, retrieve the corresponding driver result set from MySQL Server where the driver table is located. Then retrieve the corresponding data from the MySQL Server where the driven table is located based on the driver result set. Many readers may think that this will have a certain impact on performance. Yes, it will indeed have a certain negative impact on performance, but apart from this method, there are basically not many other better solutions.
And, since the database is better expanded, the load of each MySQL Server can be better controlled. For a single Query, its response time may be slightly higher than before it is not segmented, so the negative impact on performance is not too great. not to mention. There are not too many requirements for cross-node Join similar to this. Relative to the overall performance, it may only be a very small part. So for the sake of overall performance, occasionally sacrifice a little bit. It's actually worth it. After all, system optimization itself is a process with many trade-offs and balances.
3. Cross-node merge sorting and paging issues
Once the data is horizontally split, it may not only be the cross-node Join that cannot be executed normally, but also some sorting and paging Query statements. The data source may also be split into multiple nodes. The direct consequence of this is that these sorting and paging queries cannot continue to execute normally. In fact, this is the same as cross-node Join. The data source exists on multiple nodes and needs to be solved through a Query, which is the same operation as cross-node Join. Similarly, Federated can also partially solve it. Of course there are risks as well.
Still the same problem, what should I do? I still continue to recommend solving it through the application.
How to solve it? The solution idea is generally similar to the solution of cross-node Join, but there is one thing that is different from cross-node Join. Join often has a driver-driven relationship. Therefore, data reading between multiple tables involved in the Join itself generally has a sequential relationship. But sorting paging is different. The data source of sorting paging can basically be said to be a table (or a result set). There is no sequential relationship in itself, so the process of fetching data from multiple data sources can be completely parallelized.
so. We can achieve higher efficiency in retrieving sorted paging data than cross-database Join. Therefore, the performance loss caused is relatively smaller, and in some cases it may be more efficient than in the original database without data segmentation.
Of course, whether it is cross-node Join or cross-node sorting and paging. This will cause our application server to consume a lot of other resources, especially memory resources, because the process of reading, accessing and merging result sets requires us to process a lot more other data than before.
Проанализировав этот момент, многие читатели могут обнаружить, что все вышеперечисленные проблемы в основном решаются с помощью приложений. Возможно, каждый начинает роптать в своих сердцах. Не потому ли, что я администратор баз данных, я оставляю многое архитекторам и разработчикам приложений?
На самом деле это совсем не так.В первую очередь приложение обусловлено его особенностью. Очень легко добиться очень хорошей масштабируемости, но база данных другая. Расширение должно достигаться многими другими способами. И в этом процессе расширения очень сложно избежать ситуаций, которые можно решить в централизованной базе данных, но которые становятся сложной проблемой после разделения на кластер базы данных.
Чтобы максимизировать общее расширение системы, мы можем разрешить приложению выполнять только многие другие функции. Для решения проблем, которые не могут быть решены с помощью кластеров баз данных.
Используйте технологию сегментации данных, чтобы разделить большой MySQLServer на несколько маленьких MySQLServer, что не только устраняет проблему узкого места в производительности записи, но и еще раз улучшает масштабируемость всего кластера базы данных. Будь то вертикальная сегментация или горизонтальная сегментация. Все это может снизить вероятность возникновения узких мест в системе. Особенно когда мы используем комбинацию методов вертикальной и горизонтальной нарезки, теоретически мы больше не будем сталкиваться с узкими местами расширения.
Связанные рекомендации:
Mysql методы подбазы данных и подтаблиц (часто используемые)_MySQL
mysql master-slave Database , таблица суббазы суббазы данных и другие примечания_MySQL
#Old boy mysql видео:MySQL метод устранения неполадок при запуске нескольких экземпляров базы данных и практический метод устранения неполадок Поиск неисправностей
The above is the detailed content of Strategies to solve technical difficulties in mysql database sub-database and table sub-tables. For more information, please follow other related articles on the PHP Chinese website!