LRU 알고리즘에 대해 이야기해 보겠습니다
는 가장 최근에 사용되지 않은 데이터를 필터링하는 것입니다. 가장 적게 사용된 데이터는 필터링되고 최근에 자주 사용된 데이터는 캐시에 유지됩니다.
그럼 정확히 어떻게 검진을 받나요? LRU는 모든 데이터를 연결 목록으로 구성합니다. 연결 목록의 머리 부분과 끝 부분은 각각 MRU 끝과 LRU 끝을 나타내며 가장 최근에 사용된 데이터와 가장 최근에 가장 적게 사용된 데이터를 나타냅니다.
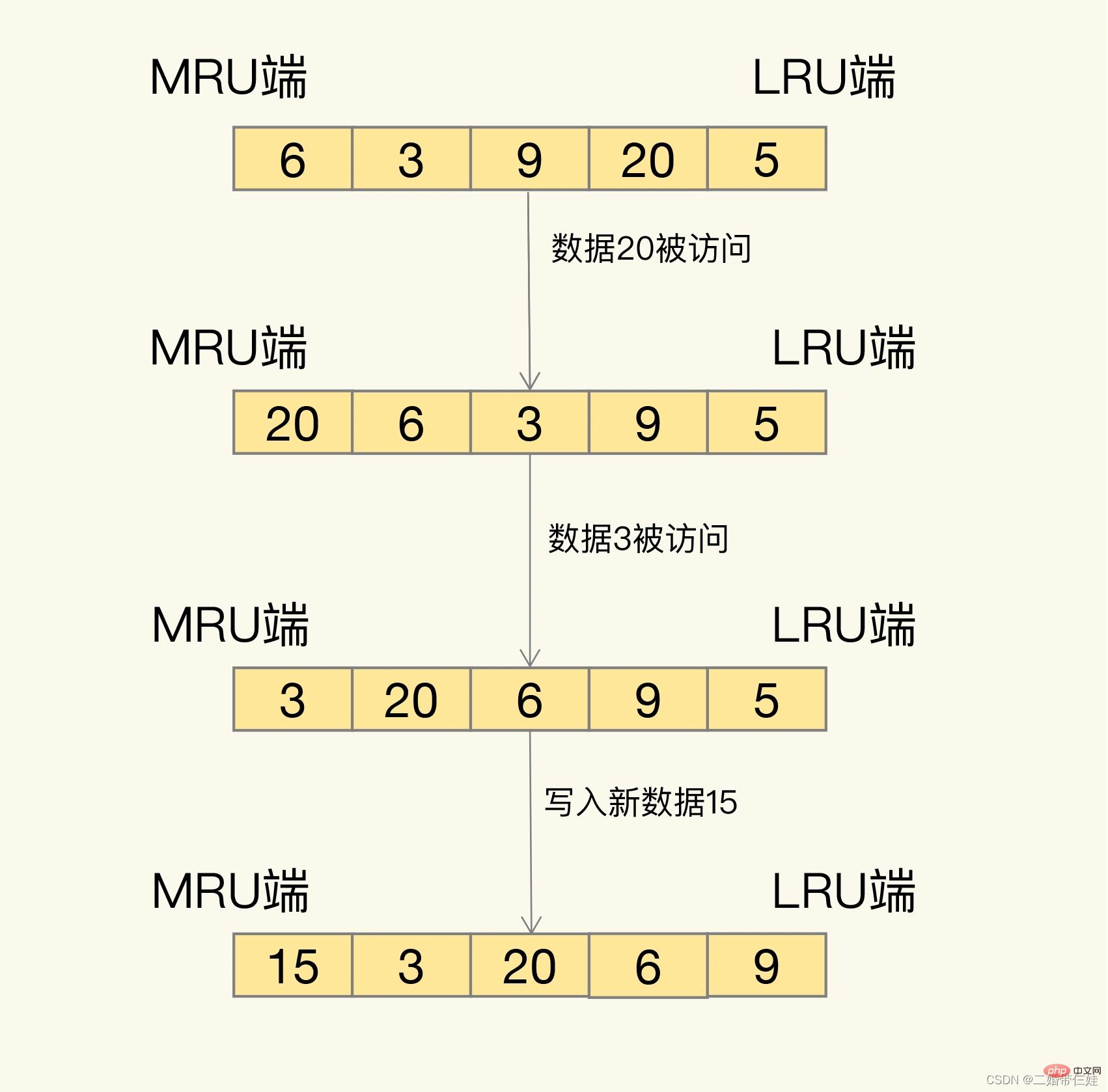
LRU 알고리즘의 기본 아이디어는 매우 간단합니다. 방금 액세스한 데이터는 반드시 다시 액세스할 것이라고 믿으므로 오랫동안 액세스하지 않은 데이터는 반드시 MRU 측에 배치됩니다. 다시 접근할 수 없도록 점차적으로 LRU 측으로 이동시키고, 캐시가 가득 차면 먼저 삭제하세요.
문제: LRU 알고리즘이 실제로 구현되면 캐시된 모든 데이터를 관리하기 위해 연결 목록을 사용해야 하므로 추가 공간 오버헤드가 발생합니다. 또한 데이터에 접근할 때 연결된 목록의 MRU로 데이터를 이동해야 하므로 많은 양의 데이터에 접근할 경우 연결 목록 이동 작업이 많이 발생하므로 시간이 많이 걸리고 Redis 캐시 성능이 저하됩니다. .
Solution:
Redis에서는 데이터 제거가 캐시 성능에 미치는 영향을 줄이기 위해 LRU 알고리즘이 단순화되었습니다. 특히 Redis는 기본적으로 각 데이터의 가장 최근 액세스 타임스탬프를 기록합니다(키-값 쌍 데이터 구조 RedisObject의 lru 필드에 기록됨). 그런 다음 Redis가 제거할 데이터를 결정하면 처음으로 N개의 데이터를 무작위로 선택하여 후보 세트로 사용합니다. 다음으로 Redis는 이러한 N개 데이터의 lru 필드를 비교하고 lru 필드 값이 가장 작은 데이터를 캐시에서 제거합니다.
데이터를 다시 제거해야 하는 경우 Redis는 첫 번째 제거 중에 생성된 후보 세트에 들어갈 데이터를 선택해야 합니다. 여기서 선택 기준은 후보 세트에 들어갈 수 있는 데이터의 lru 필드 값이 후보 세트의 가장 작은 lru 값보다 작아야 한다는 것입니다. 후보 데이터 세트에 새 데이터가 입력될 때 후보 데이터 세트의 데이터 수가 maxmemory-samples에 도달하면 Redis는 후보 데이터 세트에서 lru 필드 값이 가장 작은 데이터를 제거합니다.
사용 제안:
- 먼저 allkeys-lru 전략을 사용하세요. 이러한 방식으로 고전적인 캐싱 알고리즘인 LRU의 장점을 최대한 활용하여 가장 최근에 액세스한 데이터를 캐시에 유지하고 애플리케이션 액세스 성능을 향상시킬 수 있습니다. 비즈니스 데이터에서 핫 데이터와 콜드 데이터 사이에 뚜렷한 차이가 있는 경우 allkeys-lru 전략을 사용하는 것이 좋습니다.
- 비즈니스 애플리케이션의 데이터 액세스 빈도가 크게 다르지 않고 핫 데이터와 콜드 데이터의 명확한 구분이 없는 경우 allkeys-random 전략을 사용하고 제거된 데이터를 무작위로 선택하는 것이 좋습니다.
- 고정된 뉴스, 비디오 등 비즈니스에 고정된 데이터가 필요한 경우 휘발성-lru 전략을 사용할 수 있으며 이러한 고정된 데이터에 대한 만료 시간을 설정하지 마세요. 이런 방식으로 고정해야 하는 데이터는 절대 삭제되지 않으며, 다른 데이터는 만료 시 LRU 규칙에 따라 필터링됩니다.
삭제된 데이터를 처리하는 방법은 무엇인가요?
제거된 데이터가 선택되면 해당 데이터가 깨끗한 데이터인 경우 직접 삭제하고, 더티 데이터인 경우 데이터베이스에 다시 써야 합니다.
그렇다면 데이터 조각이 깨끗한지 더러운지 어떻게 판단할 수 있을까요?
- 클린 데이터와 더티 데이터의 차이점은 원래 백엔드 데이터베이스에서 읽었을 때의 값과 비교하여 수정되었는지 여부입니다. 정리된 데이터는 수정되지 않았으므로 백엔드 데이터베이스의 데이터도 최신 값입니다. 교체시 바로 삭제가 가능합니다.
- 더티 데이터는 수정되어 더 이상 백엔드 데이터베이스에 저장된 데이터와 일치하지 않는 데이터입니다. 이때 더티 데이터를 데이터베이스에 다시 쓰지 않으면 이 데이터의 최신 값이 손실되어 애플리케이션의 정상적인 사용에 영향을 미칩니다.
제거된 데이터가 더티 데이터인 경우에도 Redis는 해당 데이터를 데이터베이스에 다시 쓰지 않습니다. 따라서 Redis Cache를 사용할 때 데이터가 수정되면 데이터가 수정될 때 데이터베이스에 다시 작성해야 합니다. 그렇지 않으면 더티 데이터가 제거되면 Redis에 의해 삭제되며 데이터베이스에 최신 데이터가 없게 됩니다.
Redis는 어떻게 메모리를 최적화하나요?
1. 키 수 제어: Redis를 사용하여 많은 양의 데이터를 저장하는 경우 일반적으로 키 수가 많고 키가 너무 많으면 메모리도 많이 소모됩니다. Redis는 본질적으로 해시, 목록, 집합, zset 및 기타 구조와 같은 다양한 데이터 구조를 제공하는 데이터 구조 서버입니다. Redis를 사용할 때 오해하지 마세요. get/set 등의 API를 광범위하게 사용하고 Redis를 Memcached로 사용하세요. 동일한 데이터 콘텐츠를 저장하기 위해 Redis 데이터 구조를 사용하여 외부 키 수를 줄이는 것도 많은 메모리를 절약할 수 있습니다.
2. 키-값 개체를 줄입니다. Redis 메모리 사용량을 줄이는 가장 직접적인 방법은 키와 값의 길이를 줄이는 것입니다.
- 키 길이: 키를 디자인할 때 비즈니스가 충분히 설명되면 키 값은 짧을수록 좋습니다.
- 값 길이: 값 개체 축소는 더 복잡합니다. 일반적인 요구 사항은 비즈니스 개체를 바이너리 배열로 직렬화하여 Redis에 넣는 것입니다. 우선, 비즈니스 측면에서 비즈니스 객체를 간소화해야 하며, 유효하지 않은 데이터가 저장되지 않도록 불필요한 속성을 제거해야 합니다. 둘째, 직렬화 도구 선택 측면에서 바이트 배열 크기를 줄이기 위해 보다 효율적인 직렬화 도구를 선택해야 합니다.
3. 코딩 최적화. Redis는 string, list, hash, set, zet 등과 같은 외부 유형을 제공하지만 Redis 내부에는 다양한 유형에 대한 인코딩 개념이 있습니다. 소위 인코딩은 이를 구현하는 데 사용되는 특정 기본 데이터 구조를 나타냅니다. 다양한 인코딩은 메모리 사용량과 데이터 읽기 및 쓰기 효율성에 직접적인 영향을 미칩니다.
- 1. redisObject object
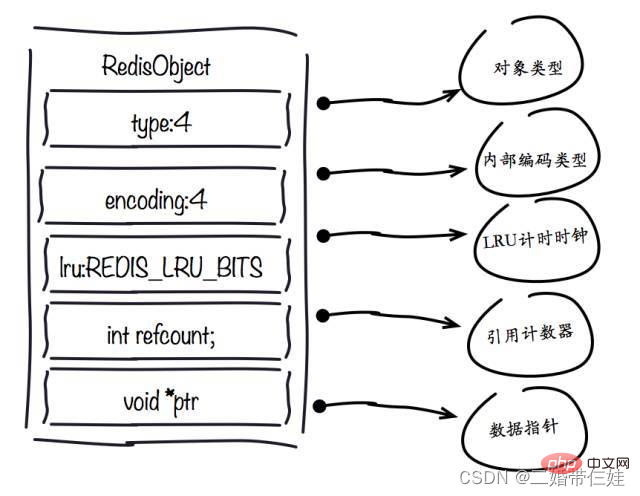
type field:
컬렉션 유형 데이터를 사용하세요. 일반적으로 많은 작은 Key-Value를 더 컴팩트한 방식으로 함께 저장할 수 있기 때문입니다. 가능한 한 해시를 사용하십시오. 해시 테이블(해시 테이블에 저장되는 숫자가 작다는 의미)은 매우 작은 메모리를 사용하므로 데이터 모델을 최대한 해시 테이블로 추상화해야 합니다. 예를 들어, 웹 시스템에 사용자 개체가 있는 경우 사용자의 이름, 성, 이메일, 비밀번호에 대해 별도의 키를 설정하지 말고, 대신 모든 사용자 정보를 해시 테이블에 저장하세요.
인코딩 필드:
다른 인코딩을 사용하면 메모리 사용량에 명백한 차이가 있습니다
lru field:
개발 팁: 스캔 + 개체 유휴 시간 명령을 사용하여 액세스되지 않은 키를 일괄 쿼리할 수 있습니다. 메모리 사용량을 줄이기 위해 오랫동안 접근하지 않은 키를 정리하세요.
refcount field:
객체가 정수이고 범위가 [0-9999]인 경우 Redis는 공유 객체를 사용하여 메모리를 절약할 수 있습니다.
ptr 필드 :
개발 팁: 동시 쓰기가 많은 시나리오에서는 redisObject 생성을 위한 메모리 할당 수를 줄이고 성능을 향상시키기 위해 조건이 허용하는 경우 문자열 길이를 39바이트 이내로 제어하는 것이 좋습니다.
- 2. 키-값 개체 줄이기
Redis 메모리 사용량을 줄이는 가장 직접적인 방법은 키와 값의 길이를 줄이는 것입니다.
일반 압축 알고리즘을 사용하여 json과 xml을 Redis에 저장하기 전에 압축하면 메모리 사용량을 줄일 수 있습니다
- 3. 공유 개체 풀
개체 공유 풀은 정수 개체 풀 [0-9999를 참조합니다. ] Redis가 내부적으로 관리합니다. 많은 수의 정수형 redisObject를 생성하려면 메모리 오버헤드가 발생합니다. 각 redisObject의 내부 구조는 최소 16바이트를 차지하며 이는 정수 자체의 공간 소비를 초과합니다. 따라서 Redis 메모리는 메모리 절약을 위해 정수 개체 풀 [0-9999]을 유지합니다. 정수 값 개체 외에도 list, hash, set, zset 내부 요소와 같은 다른 유형도 정수 개체 풀을 사용할 수 있습니다. 따라서 개발 시 요구사항 충족을 전제로 메모리 절약을 위해 정수 객체를 사용해 보세요.
maxmemory가 설정되고 휘발성-lru, allkeys-lru와 같은 LRU 관련 제거 전략이 활성화되면 Redis는 공유 개체 풀의 사용을 금지합니다.
maxmemory 및 LRU 제거 전략을 켠 후 객체 풀이 유효하지 않은 이유는 무엇입니까?
LRU 알고리즘은 각 객체의 가장 긴 미방문 데이터를 제거하기 위해 객체의 마지막 액세스 시간을 얻어야 합니다. redisObject 객체의 lru 필드에 저장됩니다. 객체 공유는 여러 참조가 동일한 redisObject를 공유한다는 의미이며, 이때 lru 필드도 공유되므로 각 객체의 마지막 액세스 시간을 얻을 수 없습니다. maxmemory가 설정되지 않은 경우 Redis는 메모리가 소진될 때까지 메모리 재활용을 트리거하지 않으므로 공유 개체 풀이 정상적으로 작동할 수 있습니다.
요약하자면, 공유 객체 풀은 maxmemory+LRU 전략과 충돌하므로 사용 시 주의가 필요합니다.
왜 정수 개체 풀만 있나요?
우선 정수 개체 풀은 재사용 가능성이 가장 높습니다. 둘째, 개체 공유의 핵심 작업은 동등성을 판단하는 것입니다. Redis가 정수 개체 풀만을 갖는 이유는 정수 비교 알고리즘의 시간 복잡도가 높기 때문입니다. O(1)이며 개체 풀 낭비를 방지하기 위해 정수 10,000만 유지됩니다. 문자열의 동등성을 판단하면 시간 복잡도는 O(n)이 되며, 특히 긴 문자열은 성능을 더 많이 소비합니다(부동 소수점 숫자는 문자열을 사용하여 Redis 내부에 저장됩니다). 해시, 리스트 등과 같은 보다 복잡한 데이터 구조의 경우 동등성 판단에는 O(n2)가 필요합니다. 단일 스레드 Redis의 경우 이러한 오버헤드는 분명히 비합리적이므로 Redis는 정수 공유 개체 풀만 유지합니다.
- 4. 문자열 최적화
Redis는 기본 C 언어의 문자열 유형을 사용하지 않고 SDS라고 하는 내부 단순 동적 문자열을 사용하여 자체 문자열 구조를 구현합니다.
문자열 구조:
- 특징:
O(1) 시간 복잡도 획득: 문자열 길이, 사용된 길이, 사용되지 않은 길이.
바이트 배열을 저장하는 데 사용할 수 있으며 안전한 바이너리 데이터 저장을 지원합니다.
메모리 재할당 횟수를 줄이기 위해 공간 사전 할당 메커니즘을 내부적으로 구현합니다.
지연 삭제 메커니즘, 문자열 축소 후 공간은 해제되지 않으며 사전 할당된 공간으로 예약됩니다.
사전 할당 메커니즘:
- 개발 팁: 추가 및 설정 범위와 같은 빈번한 문자열 수정 작업을 줄이십시오. 대신 사전 할당으로 인한 메모리 낭비 및 메모리 조각화를 줄이기 위해 set을 직접 사용하여 문자열을 수정하십시오.
문자열 재구성: 해시 유형을 기반으로 한 보조 인코딩 방법입니다.
- 보조 인코딩을 사용하는 방법은 무엇인가요?
보조 인코딩 방법에 사용되는 ID 길이는 특정합니다.
문제가 있습니다. 해시 유형의 기본 구조가 설정 값보다 작으면 압축된 목록이 사용되고, 설정 값보다 크면 해시 테이블이 사용됩니다.
압축 목록에서 해시 테이블로 변환되면 해시 유형은 항상 해시 테이블에 저장되며 압축 목록으로 다시 변환되지 않습니다.
메모리 공간 절약 측면에서 해시 테이블은 압축된 목록만큼 효율적이지 않습니다. 압축된 목록의 컴팩트한 메모리 레이아웃을 최대한 활용하려면 일반적으로 해시에 저장되는 요소 수를 제어해야 합니다.
- 5. 인코딩 최적화
ziplist로 인코딩된 해시 유형은 여전히 해시테이블로 인코딩된 세트보다 많은 메모리를 절약합니다.
- 6. 키 개수 조절
개발 팁: ziplist+hash를 사용해 키를 최적화한 후 타임아웃 삭제 기능을 사용하려면 개발자가 각 객체가 기록되는 시간을 저장한 다음, 예약된 작업을 통해 hscan을 사용하십시오. 명령을 사용하여 데이터를 스캔하고 해시에서 시간 초과된 데이터 항목을 찾아서 삭제하십시오.
Redis의 메모리가 부족할 때 가장 먼저 고려해야 할 사항은 수평 확장을 위한 머신을 추가하는 것이 아니라 먼저 메모리를 최적화하는 것입니다. 병목 현상이 발생하면 수평 확장을 고려하세요. 클러스터링 솔루션의 경우에도 클러스터링 후 불필요한 리소스 낭비와 관리 비용을 방지하려면 수직 수준 최적화가 똑같이 중요합니다.
추천 학습: Redis 튜토리얼



