
Home > Article > Web Front-end > Detailed explanation of examples of using JavaScript to convert Chinese characters to Pinyin

1. The current situation of converting Chinese characters to Pinyin
First of all, it should be said that there is a strong demand for converting Chinese characters to Pinyin, such as sorting/filtering contacts by Pinyin letters; such as destinations ( Typical such as ticket purchase)
Classified by pinyin first letter, etc. But the solution to this requirement, but I haven’t heard of any clever implementation (especially on the browser side), probably requires a huge dictionary.
Specific to JavaScript, check github and npm. The better libraries for converting Chinese characters to pinyin include pinyin
and pinyinjs. You can see that both of them come with huge dictionaries.
These dictionaries often weigh tens or hundreds of KB (some even several MB). It still takes some courage to use them on the browser side. So when we encounter the need to convert Chinese characters to Pinyin, it is not surprising that our first reaction is to reject the request (or implement it on the server side).
Now, if I tell you that you can convert Chinese characters to Pinyin in 300 lines of code on the browser side, is it unbelievable?
2. Starting from the Android 4.2.2 contact code
Again emphasize this blog - using the Android source code, Easily convert Chinese characters to Pinyin.
Today I would like to share with you a solution for converting Chinese characters into Pinyin extracted from the Android system source code. With just one class and more than 560 lines of code, you can easily realize the function of converting Chinese characters into Pinyin without any other third party. rely.
Has this broken your thinking pattern: Is there any powerful algorithm that can abandon the dictionary?
After reading the blog for the first time, I was a little disappointed. There was no algorithm analysis. It just introduced the hundreds of lines of code discovered from the Android code. The second time I read the code with the idea of porting it to JavaScript, I finally understood the principle, so I started the journey of porting.
3. Teach you step by step how to convert Chinese characters to Pinyin with 300 lines of JavaScript code
First, let’s get straight to the core: why converting Chinese characters to Pinyin requires a huge dictionary of thinking Settlement?
Because the arrangement of Chinese characters has nothing to do with pinyin, for example, in the Chinese character range \u4E00-\u9FFF, the former may be ha, and the latter may be ze. There is no way to associate the unicode of Chinese characters with pinyin, so we can only There is a huge dictionary that records the pinyin of every Chinese character (or commonly used Chinese character).
However, suppose we can sort all Chinese characters by pinyin, such as 'A','AI','AN','ANG','AO','BA',...,'ZUI',' ZUN','ZUO' sorting, then we only need to remember the first Chinese character of each Chinese character queue with the same pinyin. Then, the required dictionary will be very small (just cover all pinyin, the number of pinyin itself is not large).
Now, the difficulty is to sort the Chinese characters by pinyin. Fortunately, the ICU/localization related API provides this sorting API (if there were no convenient sorting/comparison methods, this article may not appear).
So, this is why 300 lines can be used to convert Chinese characters to Pinyin: Intl.CollatorAPI: Intl.Collator internally implements localization-related string sorting. We can basically sort all Chinese characters according to Pinyin through Intl.Collator.prototype.compare.
Boundary Chinese character table: records the sorted boundary points. Each Chinese character in this Chinese character table is the first Chinese character in a set of Chinese characters with the same pinyin after sorting (Eachunihansisthefirstonewithinsamepinyinwhencollatoriszh_CN).
Speaking of this, there may still be something that is not clearly explained, so I will directly upload a piece of code:

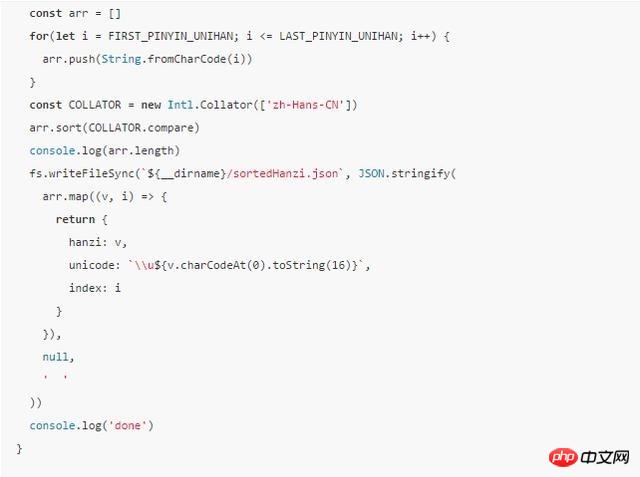
For interested students You can execute the script.js above node--icu-data-dir=node_modules/full-icu to have a look, and then see if you get a Chinese character table basically sorted by pinyin.
Here are a few points to note:
I bolded "Basic" again because the list of Chinese characters we got is not completely sorted according to Pinyin. There are occasionally some Chinese characters with other Pinyin inserted in the middle. This should be paid extra attention to when making the boundary table.
The table obtained in the above script is the sorting of all Chinese characters. Some of them are different from the table of HanziToPinyin.java in the Android code, so the table of HanziToPinyin.java needs to be updated. (The biggest pitfall and workload in switching from Java to JavaScript: correcting the boundary table)
I believe everyone has seen the core code: constCOLLATOR=newIntl.Collator(['zh-Hans-CN']), Intl.Collator
(The locale specified here is China zh-Hans-CN) is the key to sorting Chinese characters by pinyin. It is an Internationalization API that sorts strings in locale-specific order.
Please first npmifull-icu when executing the script. This dependency will automatically install the missing Chinese support and prompt how to specify the ICU data file to execute the script.
1.ICUICU stands for InternationalComponentsforUnicode, which provides Unicode and internationalization support for applications.
ICUisamature,widelyusedsetofC/C++andJavalibrariesprovidingUnicodeandGlobalizationsupportforsoftwareapplications.ICUiswidelyportableandgivesapplicationsthesameresultsonallplatformsandbetweenC/C++andJavasoftware.
And ICU provides localized string comparison services (UnicodeCollationAlgorithm+locally specific comparison rules):
Collation:Comparestringsaccordingtotheconvention sandstandardsofaparticularlanguage,regionorcountry. ICU'scollationisbasedontheUnicodeCollationAlgorithmpluslocale-specificcomparisonrulesfromtheCommonLocaleDataRepository,acomprehensivesourceforthistypeofdata.
On modern browsers, generally ICU has built-in support for the user's local language, and we can use it directly.
But for node.js, usually, ICU only contains a subset (usually English), so we need to add support for Chinese ourselves. Generally speaking, you can install full-icu
through npminstallfull-icu to install missing Chinese support. (See node--icu-data-dir=node_modules/full-icu above).
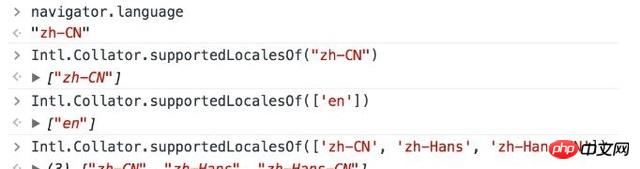
2.IntlAPI The previous section should basically explain the knowledge related to internationalization/localization. Here we will add the use of built-in API. How to check whether the user language and Runtime support this language? Intl.Collator.supportedLocalesOf(array|string)
Returns an array containing locales that are supported (without falling back to the default locale). The parameter can be an array or a string, which is the locales you want to test ( That is BCP47languagetag).
Construct the Collator object and sort the string
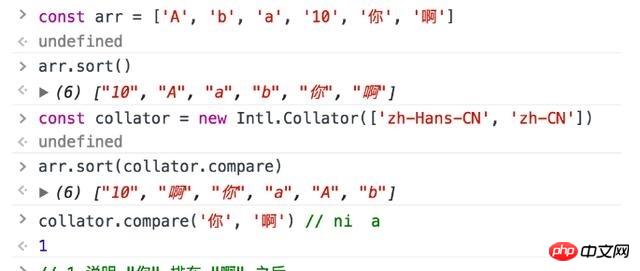
through Intl.Collator.prototype. compare, we can sort strings in the order specified by the language. In Chinese, this sorting happens to be mostly in pinyin order, 'A', 'AI', 'AN', 'ANG', 'AO', 'BA', 'BAI', 'BAN' ,'BANG','BAO','BEI','BEN','BENG','BI','BIAN','BIAO','BIE','BIN','BING','BO',' BU','CA','CAI','CAN',...
, this is the key to converting Chinese characters to Pinyin as we mentioned above.
4. Boundary table correction
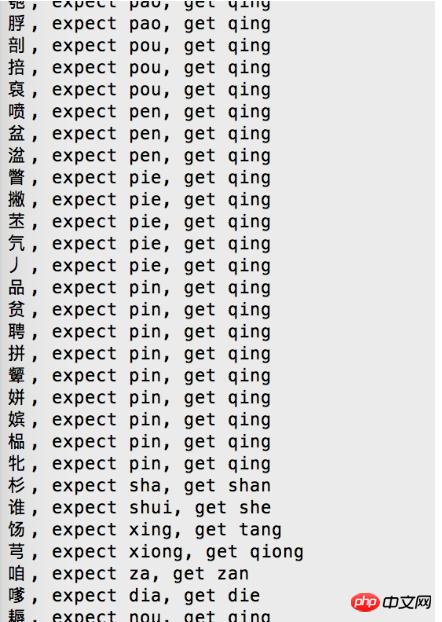
Obviously, there is a problem with this boundary table and needs to be corrected.
We can see that most of the Chinese characters have been converted into qing. It can be seen that there is a problem with the Chinese character corresponding to the pinyin of qing.
Found this Chinese character, it is '\u72c5'/'狅', plus one character before and after, ['\u4eb2','\u72c5','\u828e']/["情","狅", "芎"]
.
Search, '\u72c5'/'狅' can be read as qing, but now it is read as kuang, which should be the cause of the error.
According to the initial sorting list of all Chinese characters, the first Chinese character of qing is '\u9751'/'靑'.
After the change, only 104 failed conversions.

【Related recommendations】
1. Javascript Free Video Tutorial
2. Share 15 A commonly used js regular expression
3. Detailed example of implementing search toolbar through javascript
4. About async and await in Javascript Detailed introduction to the usage
5. Sharing the 12 most practical skills in JavaScript
The above is the detailed content of Detailed explanation of examples of using JavaScript to convert Chinese characters to Pinyin. For more information, please follow other related articles on the PHP Chinese website!