

Maison >développement back-end >Tutoriel Python >Charger des données dans Neo4j

Dans le blog précédent, nous avons vu comment installer et configurer neo4j localement avec 2 plugins APOC et Graph Data Science Library - GDS. Dans ce blog, je vais prendre un ensemble de données sur les jouets (produits dans un site Web de commerce électronique) et le stocker dans Neo4j.
Avant de commencer à charger les données, si dans votre cas d'utilisation vous disposez d'énormes données, assurez-vous qu'une quantité suffisante de mémoire est allouée à neo4j. Pour ce faire :



Les graphiques ont deux nœuds et relations de composants principaux, créons d'abord les nœuds et établissons ensuite les relations.
Les données que j'utilise sont présentes ici - data
Utilisez le fichier conditions.txt présent ici pour créer un environnement virtuel python - exigences.txt
Définissons diverses fonctions pour transmettre des données.
Importation des bibliothèques nécessaires
import pandas as pd from neo4j import GraphDatabase from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
import pandas as pd
from neo4j import GraphDatabase
from openai import OpenAI
client = OpenAI(api_key="")
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def get_embedding(text):
"""
Used to generate embeddings using OpenAI embeddings model
:param text: str - text that needs to be converted to embeddings
:return: embedding
"""
model = "text-embedding-3-small"
text = text.replace("\n", " ")
return client.embeddings.create(input=[text], model=model).data[0].embedding
def create_category(product_data_df):
"""
Used to generate queries for creating category nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for category
"""
cat_query = """CREATE (a:Category {name: '%s', embedding: %s})"""
distinct_category = product_data_df['Category'].unique()
query_list = []
for category in distinct_category:
embedding = get_embedding(category)
query_list.append(cat_query % (category, embedding))
return query_list
def create_product(product_data_df):
"""
Used to generate queries for creating product nodes in neo4j
:param product_data_df: pandas dataframe - data
:return: query_list: list - list containing all create node queries for product
"""
product_query = """CREATE (a:Product {name: '%s', description: '%s', price: %d, warranty_period: %d,
available_stock: %d, review_rating: %f, product_release_date: date('%s'), embedding: %s})"""
query_list = []
for idx, row in product_data_df.iterrows():
embedding = get_embedding(row['Product Name'] + " - " + row['Description'])
query_list.append(product_query % (row['Product Name'], row['Description'], int(row['Price (INR)']),
int(row['Warranty Period (Years)']), int(row['Stock']),
float(row['Review Rating']), str(row['Product Release Date']), embedding))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CREATE CATEGORY
query_list = create_category(product_data_df)
execute_bulk_query(query_list)
# CREATE PRODUCT
query_list = create_product(product_data_df)
execute_bulk_query(query_list)
from neo4j import GraphDatabase
import pandas as pd
product_data_df = pd.read_csv('../data/product_data.csv')
def preprocessing(df, columns_to_replace):
"""
Used to preprocess certain column in dataframe
:param df: pandas dataframe - data
:param columns_to_replace: list - column name list
:return: df: pandas dataframe - processed data
"""
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'s", "s"))
df[columns_to_replace] = df[columns_to_replace].apply(lambda col: col.str.replace("'", ""))
return df
def create_category_food_relationship_query(product_data_df):
"""
Used to create relationship between category and products
:param product_data_df: dataframe - data
:return: query_list: list - cypher queries
"""
query = """MATCH (c:Category {name: '%s'}), (p:Product {name: '%s'}) CREATE (c)-[:CATEGORY_CONTAINS_PRODUCT]->(p)"""
query_list = []
for idx, row in product_data_df.iterrows():
query_list.append(query % (row['Category'], row['Product Name']))
return query_list
def execute_bulk_query(query_list):
"""
Executes queries is a list one by one
:param query_list: list - list of cypher queries
:return: None
"""
url = "bolt://localhost:7687"
auth = ("neo4j", "neo4j@123")
with GraphDatabase.driver(url, auth=auth) as driver:
with driver.session() as session:
for query in query_list:
try:
session.run(query)
except Exception as error:
print(f"Error in executing query - {query}, Error - {error}")
# PREPROCESSING
product_data_df = preprocessing(product_data_df, ['Product Name', 'Description'])
# CATEGORY - FOOD RELATIONSHIP
query_list = create_category_food_relationship_query(product_data_df)
execute_bulk_query(query_list)
Passez la souris sur l'icône ouvrir et cliquez sur navigateur neo4j pour visualiser les nœuds que nous avons créés.
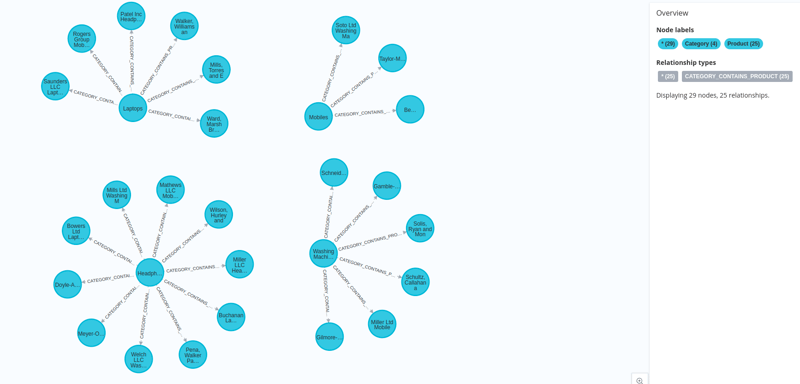
Et nos données sont chargées dans neo4j avec leurs intégrations.
Dans les prochains blogs, nous verrons comment créer un moteur de requête graphique en utilisant Python et utiliser les données récupérées pour effectuer une génération augmentée.
J'espère que cela vous aidera... À bientôt !!!
LinkedIn - https://www.linkedin.com/in/praveenr2998/
Github - https://github.com/praveenr2998/Creating-Lightweight-RAG-Systems-With-Graphs/tree/main/push_data_to_db
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!