

Home >Technology peripherals >AI >The Chinese Science Team launches the 'Thinking Chain Collection' to comprehensively evaluate the complex reasoning ability of large models

Large model capabilities are emerging, the bigger the parameter scale, the better?
However, a growing number of researchers claim that models smaller than 10B can also achieve comparable performance to GPT-3.5.
Is this really the case?
In the blog of OpenAI releasing GPT-4, it was mentioned:
In casual conversations, GPT-3.5 and GPT-4 The difference may be very subtle. Differences emerge when the complexity of the task reaches a sufficient threshold—GPT-4 is more reliable, more creative, and able to handle more nuanced instructions than GPT-3.5.
Google developers also made similar observations about the PaLM model. They found that the thinking chain reasoning ability of the large model was significantly stronger than that of the small model.
These observations indicate that the ability to perform complex tasks is the key to embodying the capabilities of large models.
Just like the old saying, models and programmers are the same, "Stop talking nonsense, show me the reasoning."

##Researchers from the University of Edinburgh, the University of Washington, and the Allen AI Institute believe that complex reasoning capabilities are the key to large models The basis for further development towards more intelligent tools in the future.
Basic text summarization ability, the execution of large models is indeed "killing a chicken with a bull's-eye".
The evaluation of these basic abilities seems to be somewhat unprofessional for studying the future development of large models.
Paper address: https://arxiv.org/pdf/2305.17306.pdf##Which company has the best large model reasoning capabilities? ?
That’s why researchers compiled a complex reasoning task list, Chain-of-Thought Hub, to measure the model’s performance in challenging reasoning tasks.Test items include mathematics (GSM8K)), science (MATH, theorem QA), symbols (BBH), knowledge (MMLU, C-Eval), and coding (HumanEval).
These test projects or data sets are all aimed at the complex reasoning capabilities of large models. There is no such thing as a simple task that anyone can answer accurately.
Researchers still use the chain of thought prompt (COT Prompt) method to evaluate the model’s reasoning ability.
For the test of reasoning ability, researchers only use the performance of the final answer as the only measurement criterion, and the intermediate reasoning steps are not used as the basis for judgment.
As shown in the figure below, the performance of current mainstream models on different reasoning tasks.
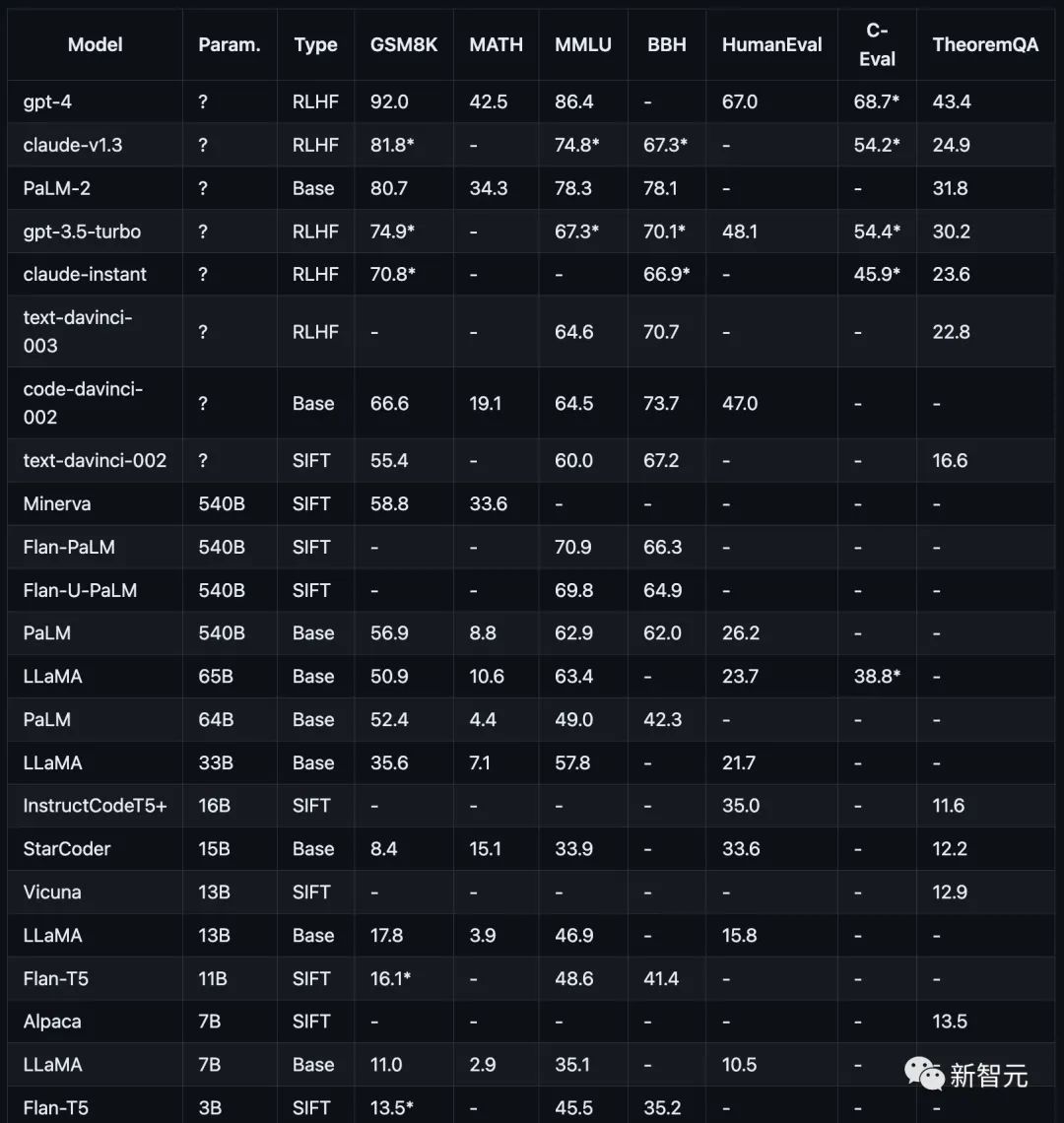
OpenAI GPT includes GPT-4 (currently the strongest), GPT3.5-Turbo ( Faster, but less powerful), text-davinci-003, text-davinci-002, and code-davinci-002 (important versions before Turbo).

Google PaLM, including PaLM, PaLM-2, and their instruction-adjusted versions (FLan-PaLM and Flan-UPaLM), strong base and instruction-adjusted models. 
Meta LLaMA, including 7B, 13B, 33B and 65B variants, is an important open source basic model.
GPT-4 significantly outperforms all other models on GSM8K and MMLU, while Claude is the only one comparable to the GPT series.
Smaller models such as FlanT5 11B and LLaMA 7B lag significantly behind.
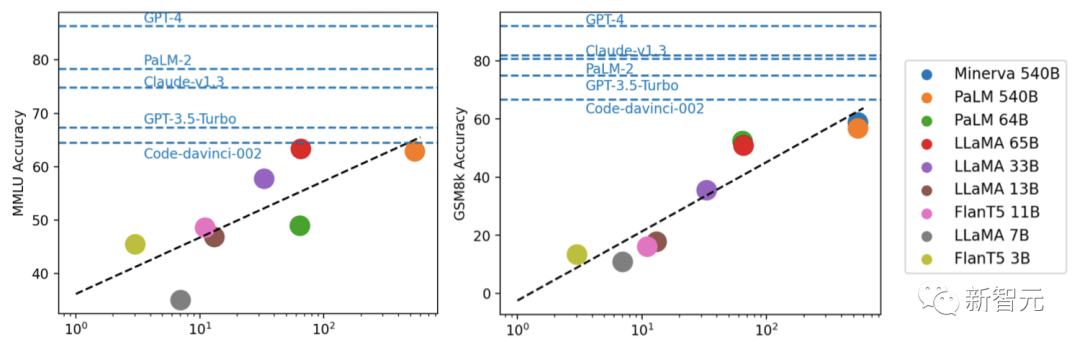
Through experiments, researchers found that model performance is usually related to scale, with a roughly logarithmic linear trend.
Models that do not disclose parameter scales generally perform better than models that disclose scale information.
In addition, the researchers pointed out that the open source community may still need to explore the "moat" regarding scale and RLHF for further improvement.
Fu Yao, the first author of the paper, concluded:
#1. There is an obvious difference between open source and closed gap.
2. Most of the top-ranked mainstream models are RLHF
3. LLaMA-65B is very close to code-davinci-002, GPT -3.5 basic model
4. Based on the above, the most promising direction is "Do RLHF on LLaMA 65B".

For this project, the author explains further optimization in the future:
In the future, more reasoning data sets including more carefully selected ones will be added, especially data sets that measure common sense reasoning and mathematical theorems.
and the ability to call external APIs.
More importantly, it is necessary to include more language models, such as instruction fine-tuning models based on LLaMA, such as Vicuna7 and other open source models.
You can also access the capabilities of models such as PaLM-2 through the API like Cohere 8.
In short, the author believes that this project can play a great role as a public welfare facility for evaluating and guiding the development of open source large language models.
The above is the detailed content of The Chinese Science Team launches the 'Thinking Chain Collection' to comprehensively evaluate the complex reasoning ability of large models. For more information, please follow other related articles on the PHP Chinese website!