
Home > Article > Technology peripherals > Duxiaoman quota model based on counterfactual causal inference


Research paradigm currently has two main research directions:
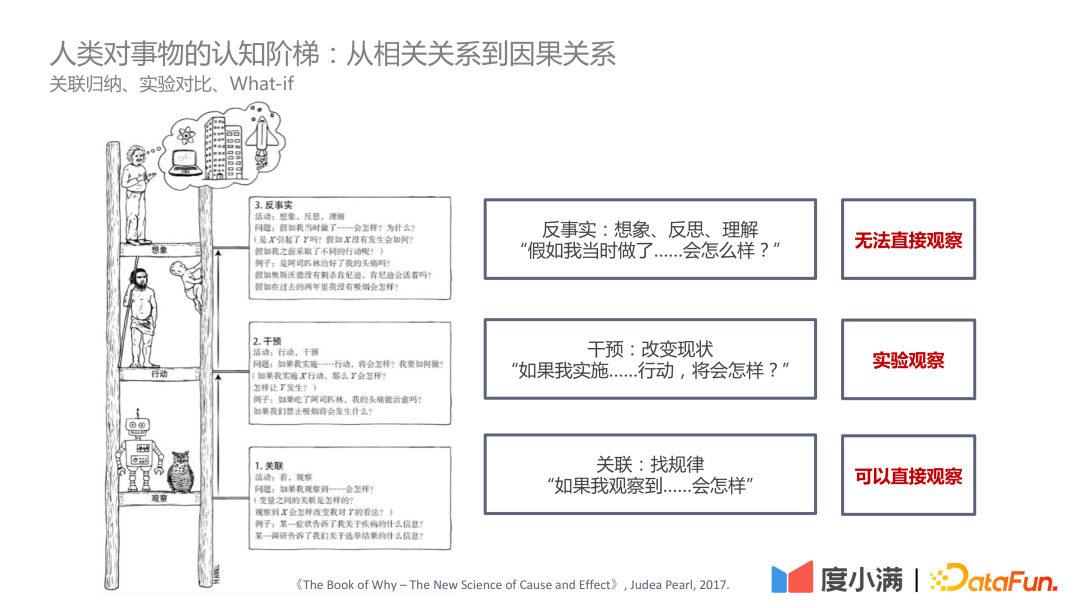
In "The Book of Why – The New Science of Cause and Effect" by Judea Pearl In this book, the cognitive ladder is positioned as three levels:
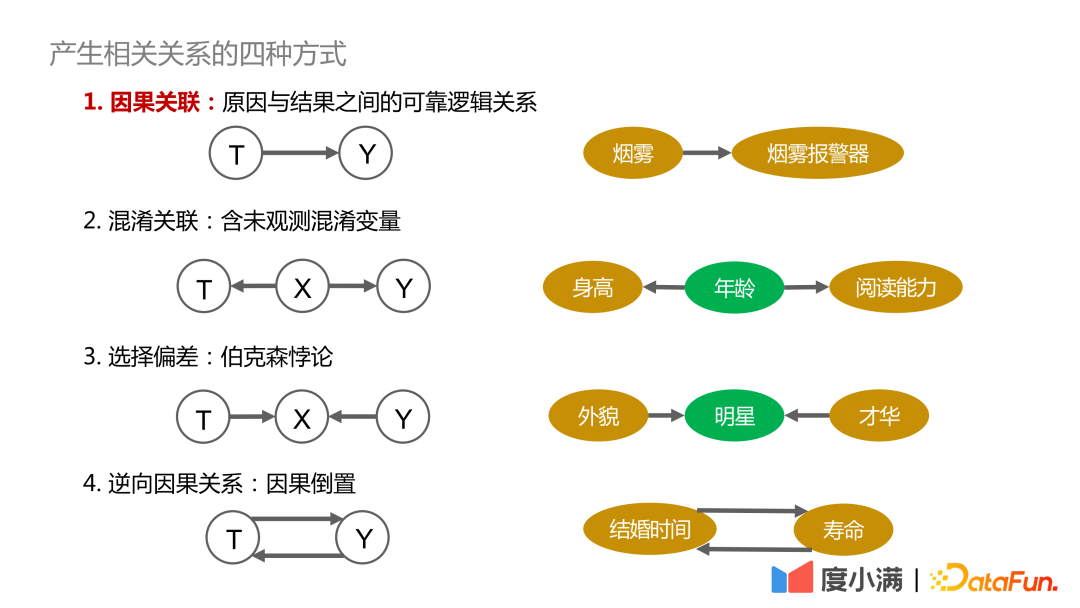
First explain the four ways to generate correlation:
1. Cause and effect Association: There is a reliable, traceable, and positively dependent relationship between the cause and the result. For example, smoke and smoke alarms are causally related;
2. Confused correlation: Contains confounding variables that cannot be directly observed, such as whether height and reading ability can be related, which need to be controlled The variable age is similar, thus drawing valid conclusions;
3. Selection bias: Essentially Berkson's Paradox, for example, if you explore the relationship between appearance and talent, if you only observe it among celebrities, you may come to the conclusion that appearance and talent cannot have both. If observed among all humans, there is no causal relationship between appearance and talent.
4. Reverse causation: That is, the inversion of cause and effect. For example, statistics show that the longer humans are married, the longer their life expectancy. the longer. But conversely, we cannot say: If you want to live longer, you must get married early.
How confounding factors affect the observation results, here are two cases to illustrate:
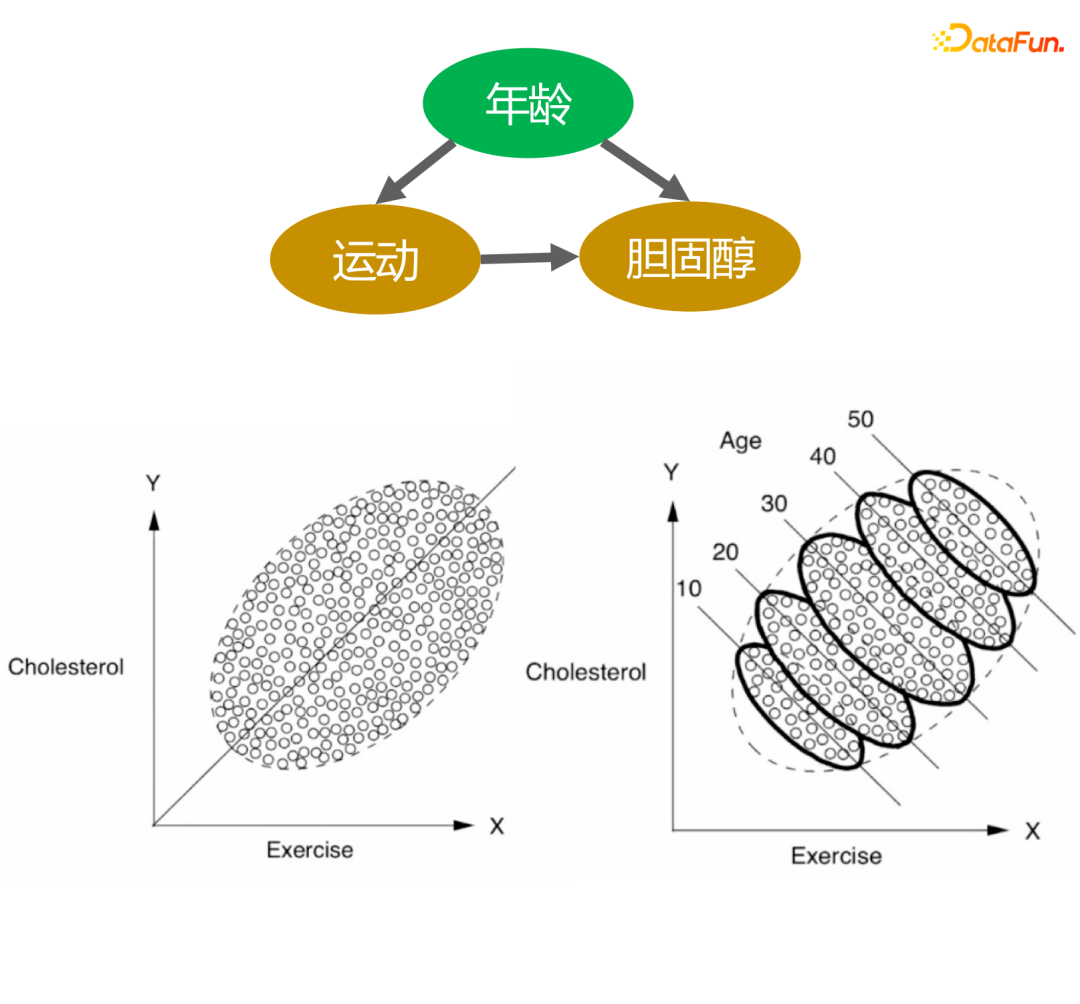
The above picture describes the relationship between exercise volume and cholesterol levels. From the picture on the left, we can conclude that the greater the amount of exercise, the higher the cholesterol level. However, when age stratification is added, under the same age stratification, the greater the amount of exercise, the lower the cholesterol level. In addition, as we age, cholesterol levels gradually increase, so this conclusion is consistent with our knowledge.
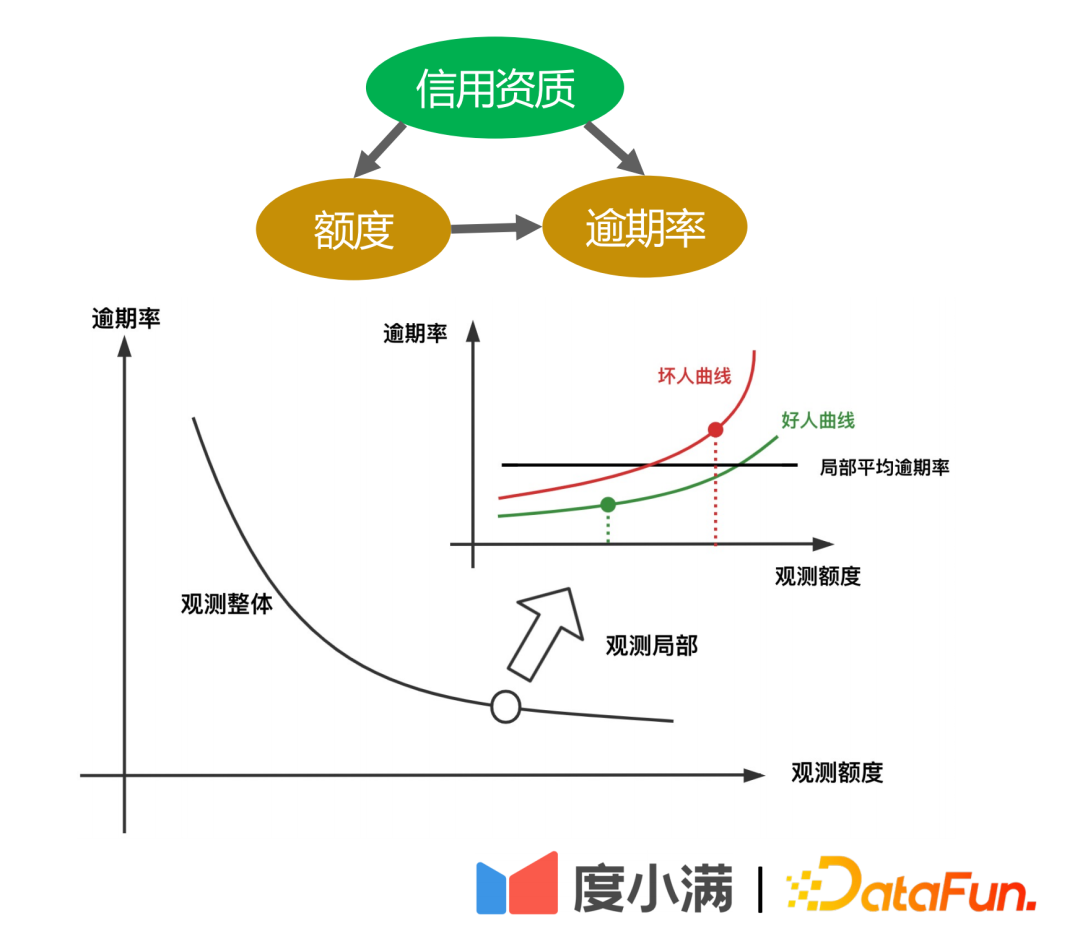
The second example is the credit scenario. It can be seen from historical statistics that the higher the given limit (the amount of money that can be borrowed), the lower the overdue rate. However, in the financial field, the borrower's credit qualification will first be judged based on his A card. If the credit qualification is better, the platform will grant a higher limit and the overall overdue rate will be very low. However, local random experiments show that for people with the same credit qualifications, there will be some people whose credit limit migration curve changes slowly, and there will also be some people whose credit limit migration risk is higher. That is, after the credit limit is increased, the risk increase will be larger. .
The above two cases illustrate that if confounding factors are ignored in modeling, wrong or even opposite conclusions may be obtained.
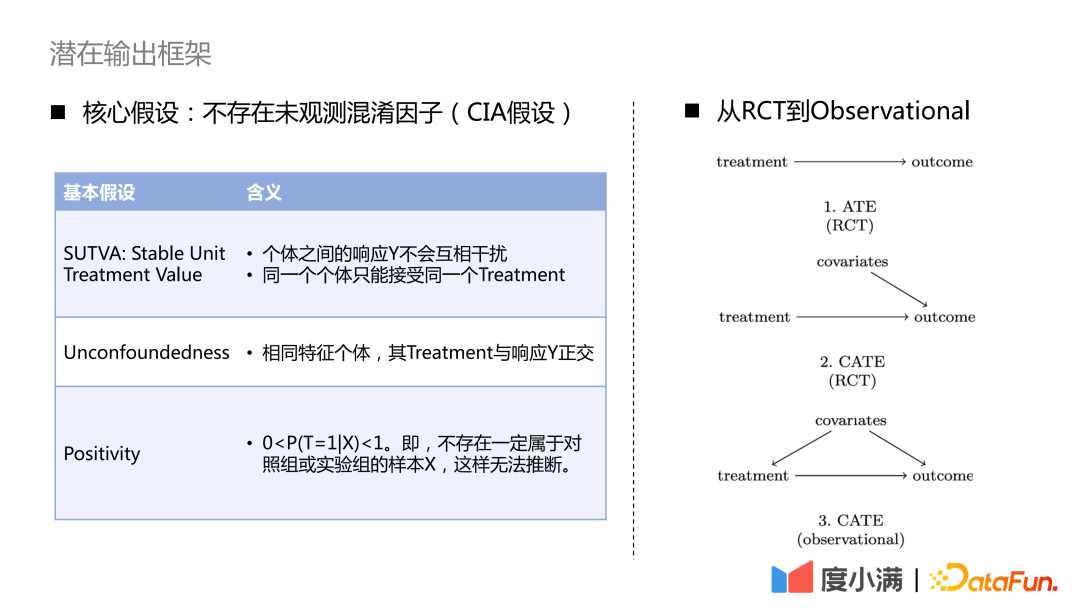
For the case of RCT samples, if you want to evaluate the ATE indicator, you can use group subtraction or DID (difference in difference). If you want to evaluate the CATE indicator, you can use uplift modeling. Common methods include meta-learner, double machine learning, causal forest, etc. There are three necessary assumptions to note here: SUTVA, Unconfoundedness and Positivity. The core assumption is that there are no unobserved confounding factors.
For the case of only observation samples, the causal relationship between treatment->outcome cannot be directly obtained. We need to use necessary means to cut off the backdoor from covariates to treatment. path. Common methods are instrumental variable methods and counterfactual representation learning. The instrumental variable method needs to peel off the details of the specific business and draw a cause-and-effect diagram of the business variables. Counterfactual representation learning relies on mature machine learning to match samples with similar covariates for causal evaluation.
Next, we will introduce the evolution of the framework of causal inference, and how to transition to causal representation learning step by step.
#Common Uplift Models include: Slearner, Tlearner, Xlearner.
#where Slearner treats the intervening variables as one-dimensional features. It should be noted that in common tree models, treatment is easily overwhelmed, resulting in smaller treatment effect estimates.
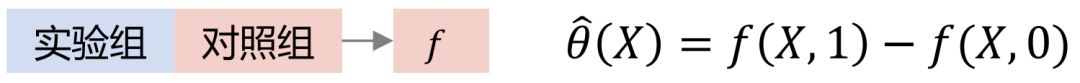
Tlearner discretizes the treatment, models the intervening variables in groups, builds a prediction model for each treatment, and then makes a difference . It is important to note that smaller sample sizes lead to higher estimated variances.
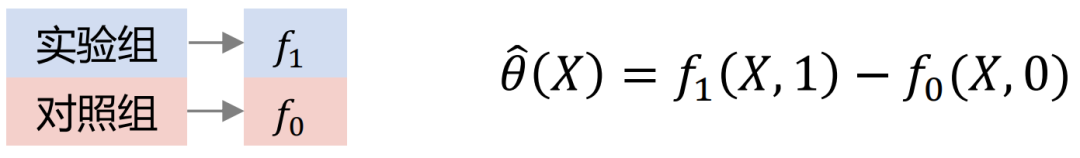
Xlearner group cross modeling, the experimental group and the control group are cross calculated and trained separately. This method combines the advantages of S/T-learner, but its disadvantage is that it introduces higher model structure errors and increases the difficulty of parameter adjustment.
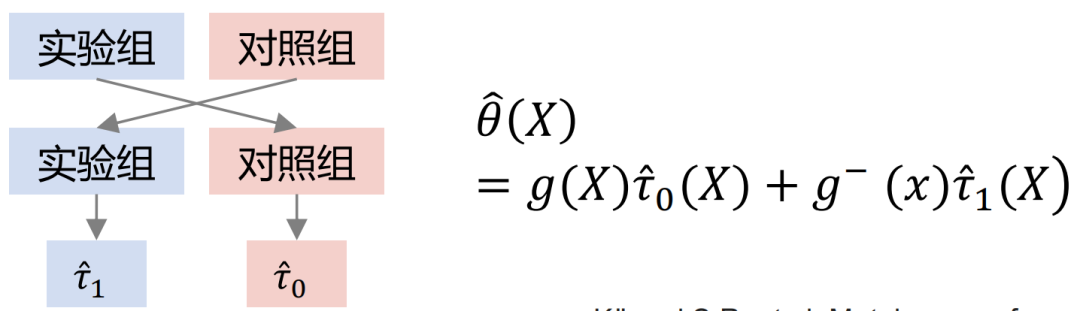
Comparison of three models:
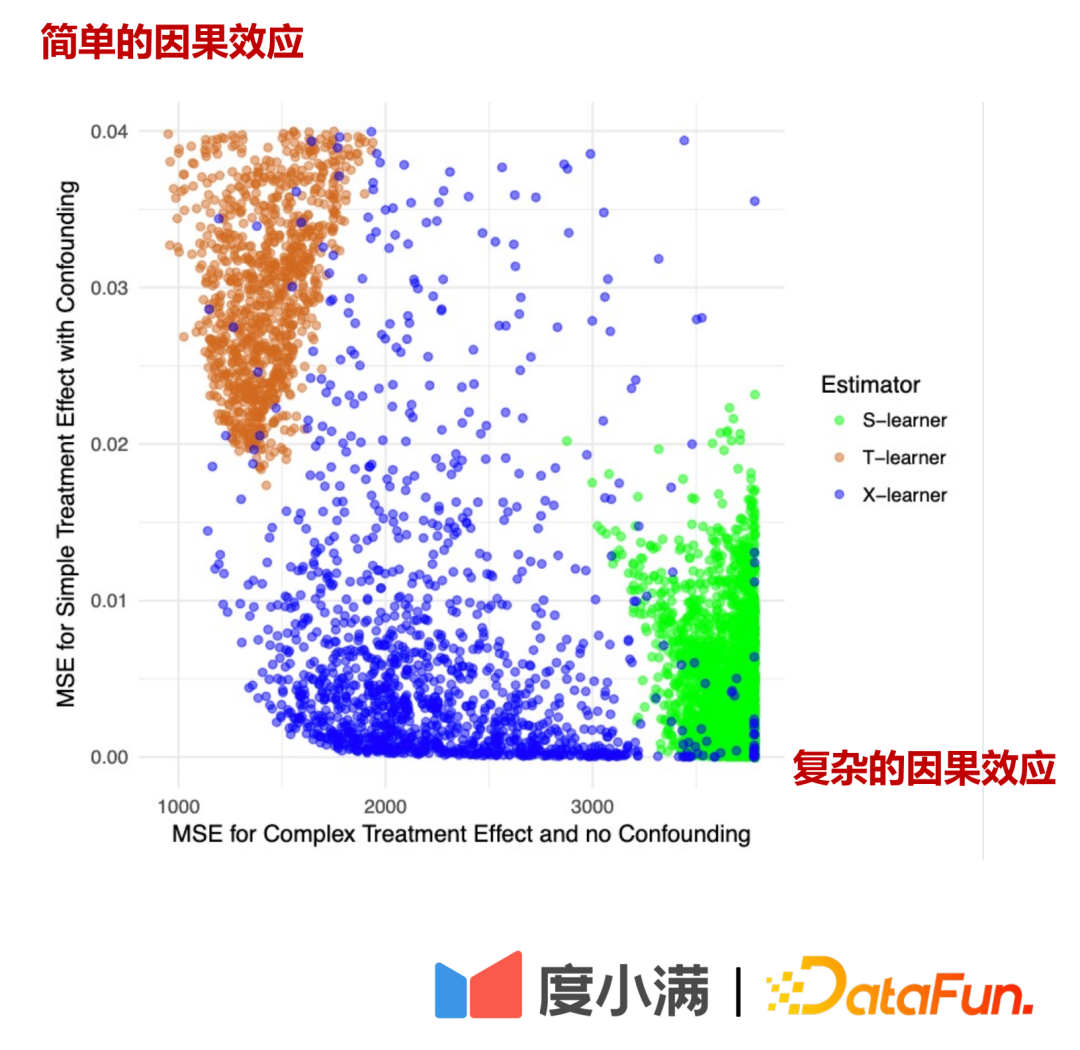
In the above figure, the horizontal axis is the complex causal effect and the estimation error of MSE. The vertical axis is the simple causal effect. The horizontal axis and the vertical axis represent two parts respectively. data. Green represents the error distribution of Slearner, brown represents the error distribution of Tlearner, and blue represents the error distribution of Xlearner.
Under random sample conditions, Xlearner is better for both complex causal effect estimation and simple causal effect estimation; Slearner performs relatively poorly for complex causal effect estimation, and is better for simple causal effect estimation. Excellent; Tlearner is the opposite of Slearner.
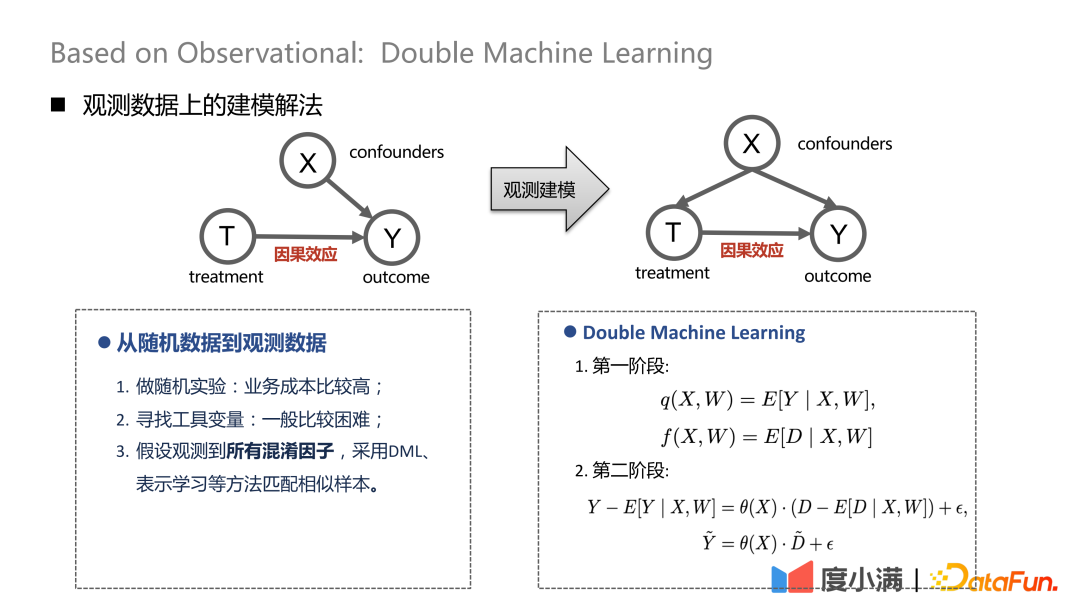
If there are random samples, the arrows from X to T can be removed. After transitioning to observational modeling, the arrows from X to T cannot be removed. Treatment and outcome will be affected by confounders at the same time. At this time, some depolarization processing can be performed. For example, DML (Double Machine Learning) method performs two-stage modeling. In the first stage, X here is the user's own representation characteristics, such as age, gender, etc. Confounding variables could include, for example, historical efforts to screen out specific groups of people. In the second stage, the error in the calculation result of the previous stage is modeled, here is the estimate of CATE.
There are three processing methods from random data to observed data:
(1) Conduct randomized experiments, but the business cost is high;
(2) Finding instrumental variables is generally difficult;
(3) Assuming that all confounding factors are observed, use DML, representation learning and other methods to match similar samples.
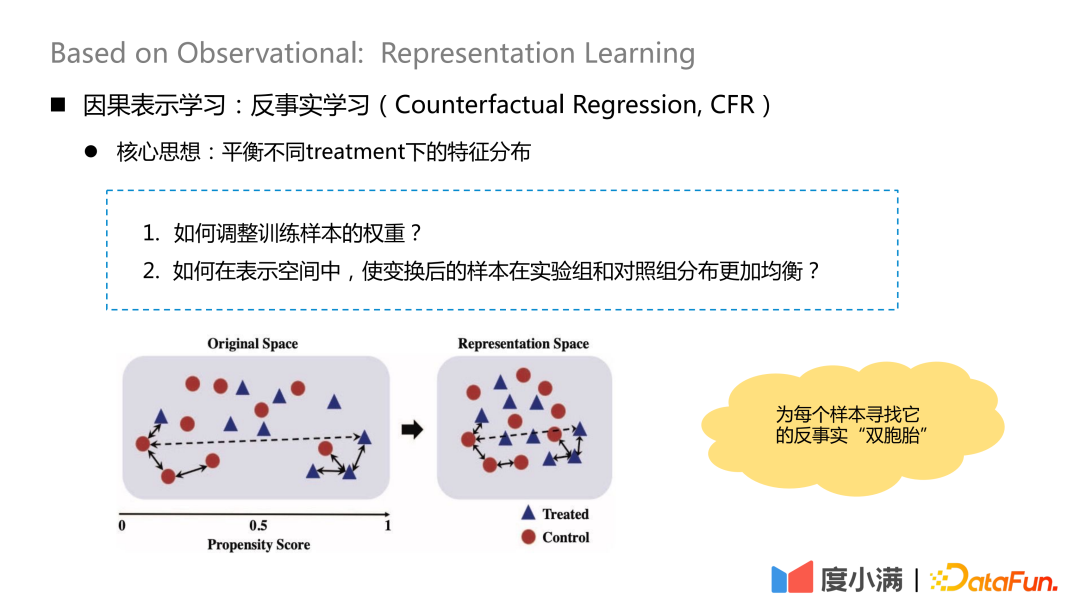
The core idea of counterfactual learning It is to balance the feature distribution under different treatments.
There are two core questions:
1. How to adjust the weight of training samples?
#2. How to make the transformed samples more evenly distributed in the experimental group and the control group in the representation space?
#The essential idea is to find its counterfactual "twin" for each sample after transformation mapping. After mapping, the distribution of X in the treatment group and control group is relatively similar.
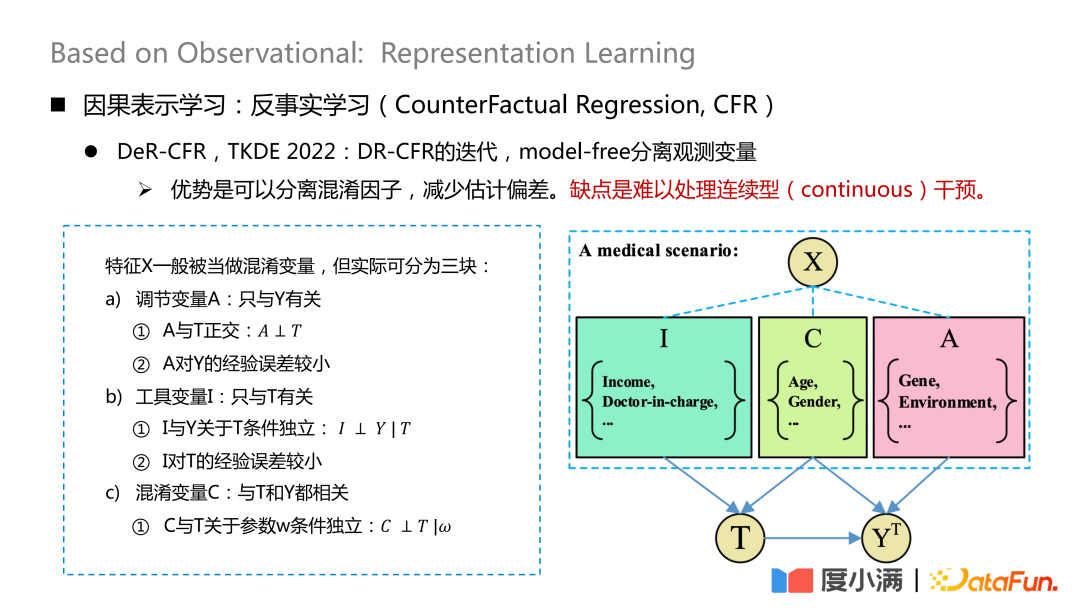
The more representative work is a paper published on TKDE 2022, which introduces the DeR-CFR Some work, this part is actually an iteration of the DR-CRF model, using a model-free method to separate observed variables.
# Divide the X variable into three pieces: adjustment variable A, instrumental variable I and confounding variable C. Then I, C, and A are used to adjust the weight of X under different treatments to achieve the purpose of causal modeling on the observed data.
#The advantage of this method is that it can separate confounding factors and reduce estimation bias. The disadvantage is that it is difficult to handle continuous interventions.
#The core of this network is how to separate the three types of variables A/I/C. The adjustment variable A is only related to Y, and it needs to be ensured that A and T are orthogonal, and the empirical error of A to Y is small; the instrumental variable I is only related to T, and it needs to satisfy the conditional independence of I and Y with respect to T, and the experience of I with respect to T The error is small; the confusion variable C is related to both T and Y, and w is the weight of the network. After giving the network weight, it is necessary to ensure that C and T are conditionally independent with respect to w. The orthogonality here can be achieved through general distance formulas, such as logloss or mse Euclidean distance and other constraints.
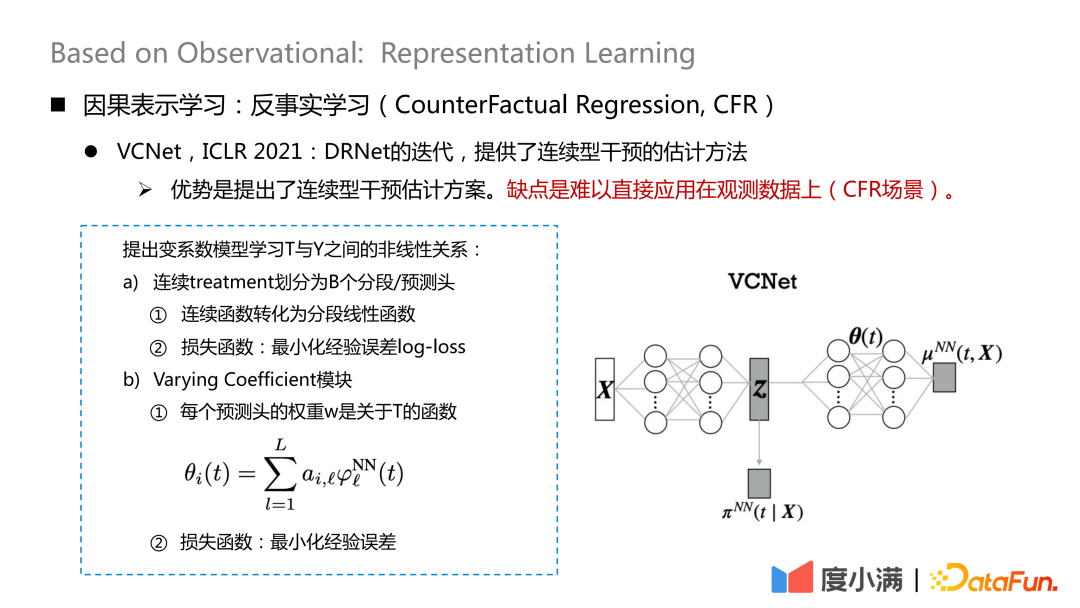
There are also some new paper studies on how to deal with continuous intervention. VCNet published on ICLR2021 provides an estimation method for continuous intervention. The disadvantage is that it is difficult to apply directly to observation data (CFR scenario).
Map The contributing variables are extracted from X. Here, the continuous treatment is divided into B segmentation/prediction heads, each continuous function is converted into a segmented linear function, and the empirical error log-loss is minimized, which is used to learn
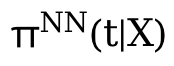
Then use the Z and θ(t) you have learned to learn. 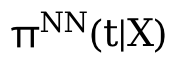
Finally, let’s introduce Du Xiaoman’s counterfactual The factual credit model mainly solves the problem of counterfactual estimation of continuous treatment on observation data.
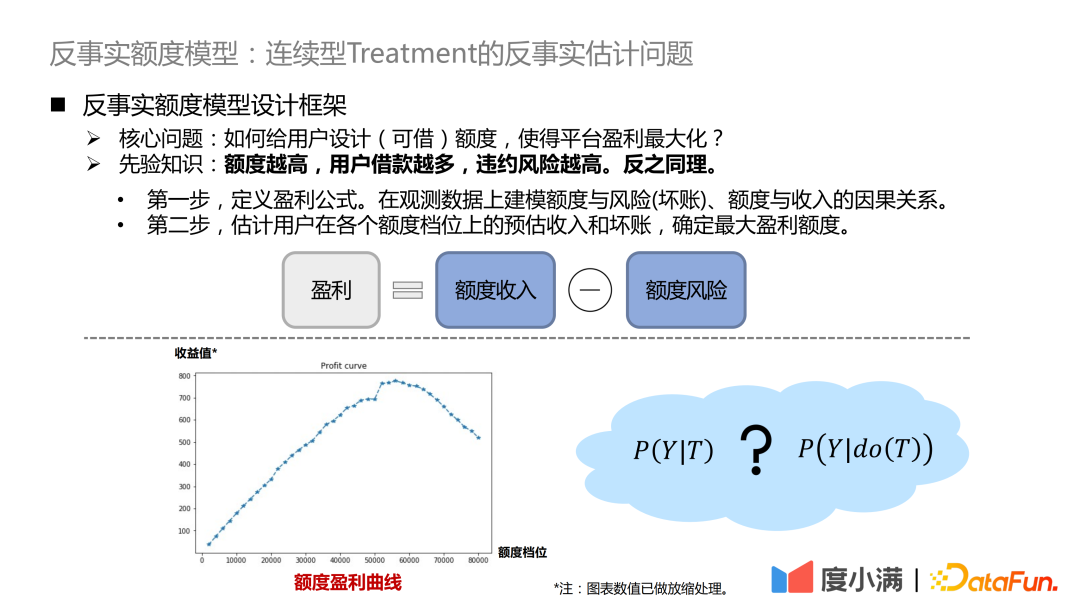
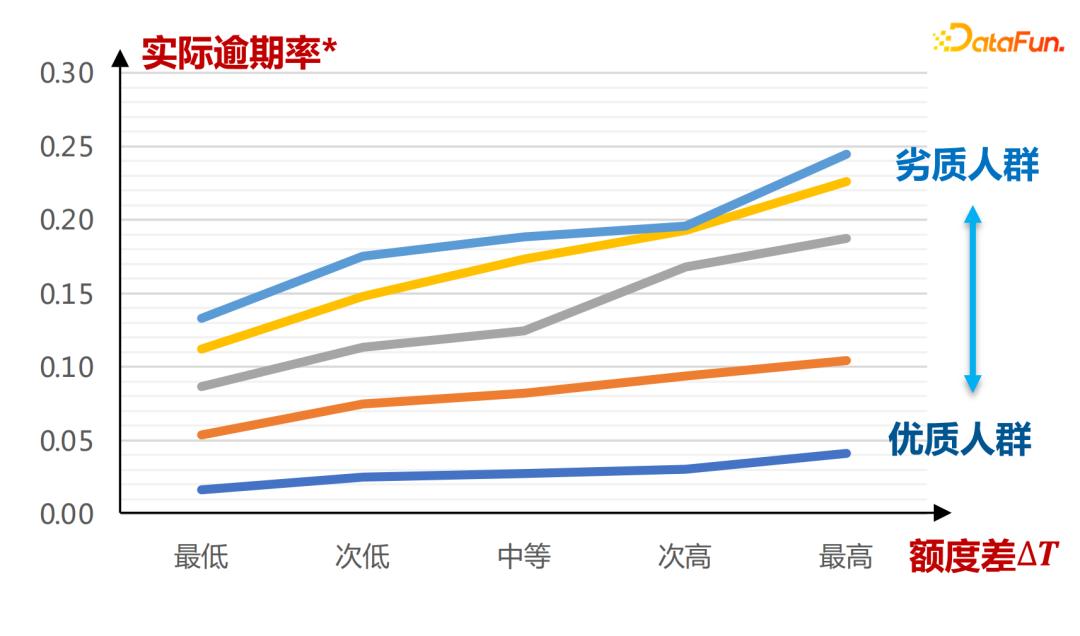
The core question is, how to design (borrowable) quotas for users to maximize platform profits? The a priori knowledge here is that the higher the limit, the more users borrow and the higher the default risk. Vice versa.
We expect each user to have a profit curve as shown in the figure above. At different quota levels, the income value is inversely Factual estimates.
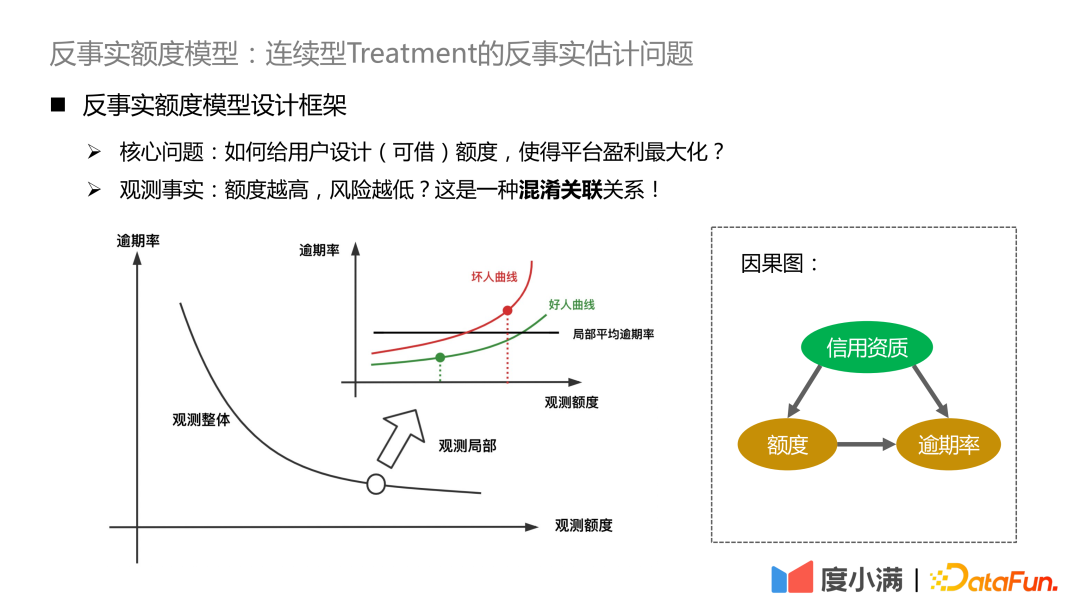
#If you see in the observation data that the higher the amount, the lower the risk, essentially due to the existence of confounding factors. The confounding factor in our scenario is credit qualifications. For people with good credit qualifications, the platform will grant a higher limit, and vice versa, the platform will grant a lower limit. The absolute risk of people with excellent credit qualifications is still significantly lower than that of people with low credit qualifications. If you improve your credit qualifications, you will see that the increase in the limit will bring about an increase in risk, and the high limit will exceed the user's own solvency.
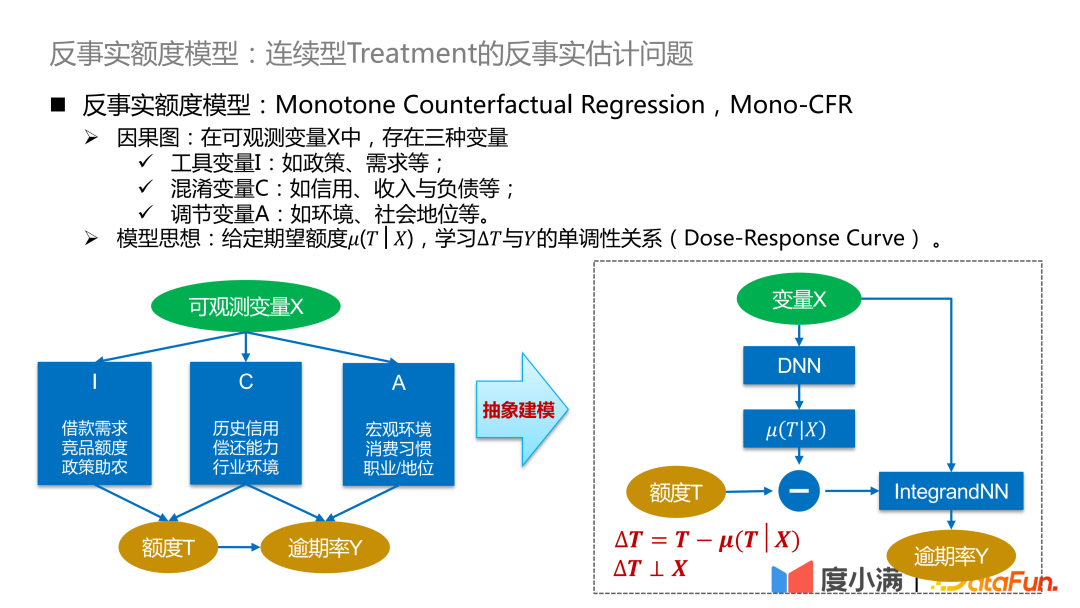
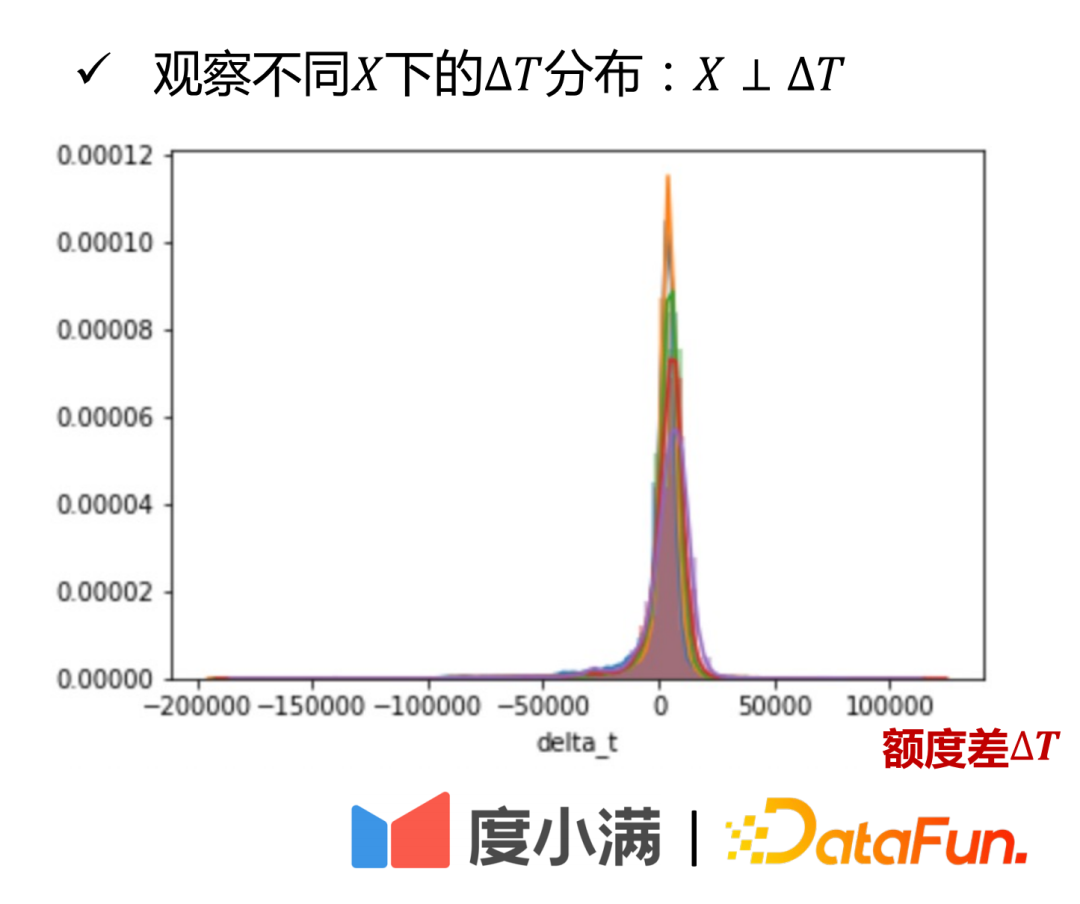
We begin to introduce the framework of the counterfactual quota model. Among the observable variables .
Model idea: Given the expected amount μ(T|X), learn the monotonic relationship between ΔT and Y (Dose-Response Curve) . The expected amount can be understood as the continuity tendency amount learned by the model, so that the relationship between the confounding variable C and the amount T can be disconnected and converted into the causal relationship learning between ΔT and Y, so as to compare the distribution of Y under ΔT Good characterization.
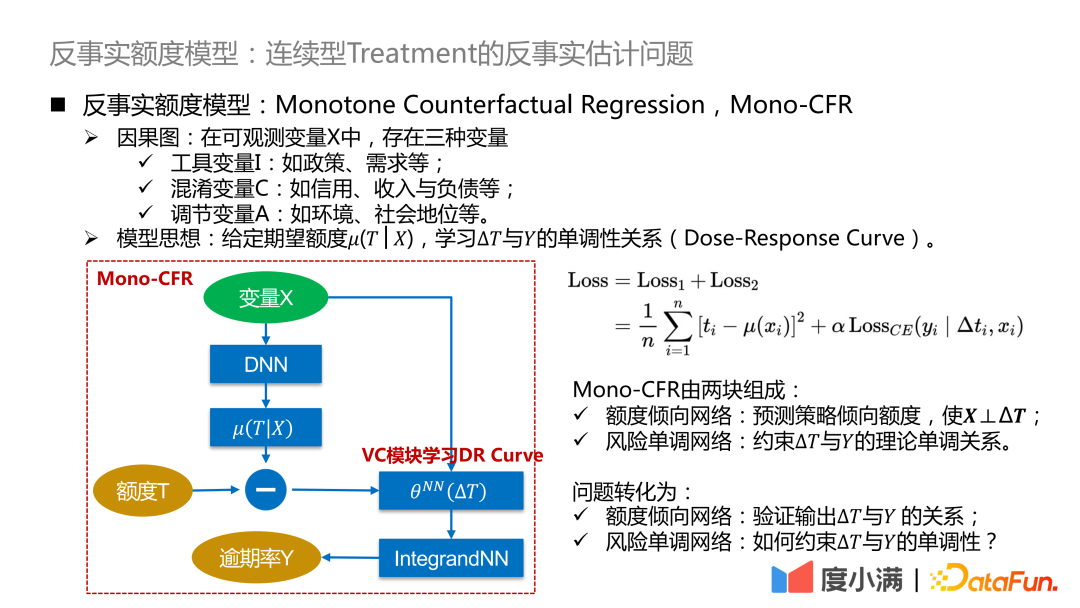
#Here we further refine the above abstract framework : Convert ΔT into a variable coefficient model, and then connect to the IntegrandNN network. The training error is divided into two parts:
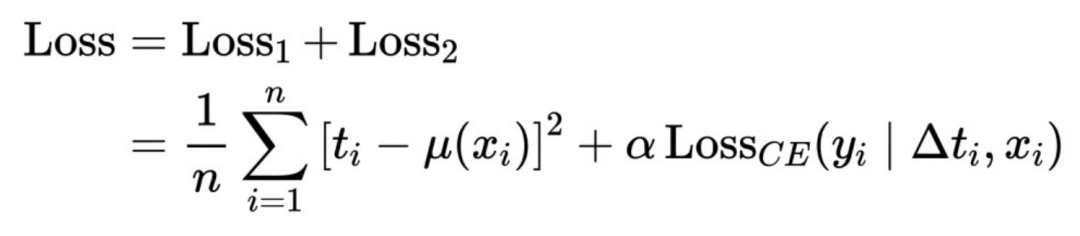
##The α here is a hyperparameter that measures the importance of risk.
Mono-CFR consists of two parts:
Function 1: Distill out the variables in X that are most relevant to T and minimize the empirical error.
# Function 2: Anchoring approximate samples on historical strategies.
Function 1: Apply independent monotonic constraints to weak coefficient variables.
#Function 2: Reduce estimation bias.
The problem is transformed into:
The actual amount tendency network input is as follows:
#From a theoretical perspective, it can also be rigorously proven. 
The second part is the implementation of risk monotonic network:

The mathematical expression of the ELU 1 function here is:
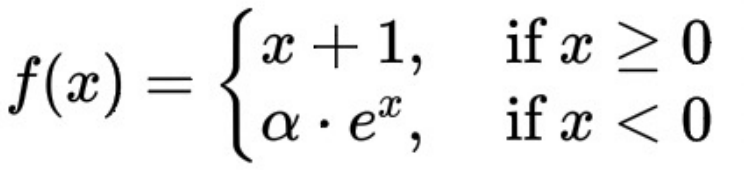
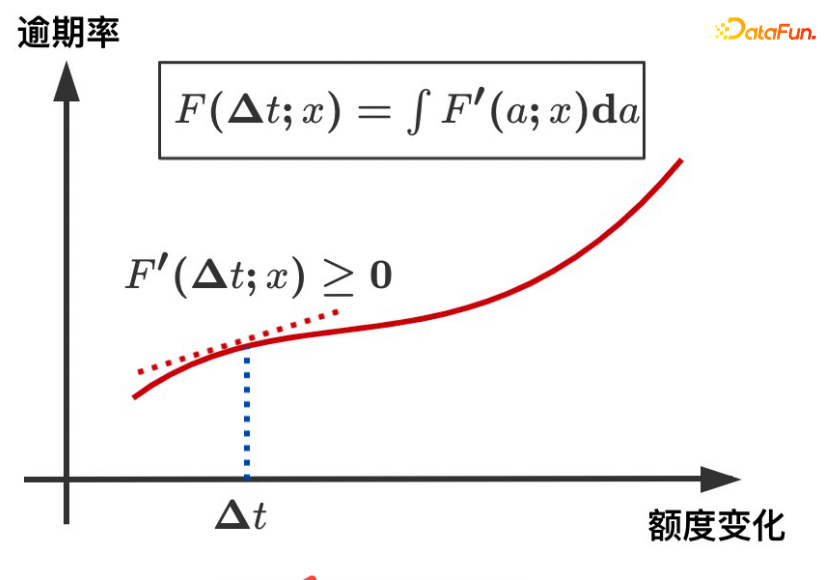
##ΔT and the overdue rate show a monotonic increasing trend, which is guaranteed by the derivative of the ELU 1 function being always greater than or equal to 0.
The following explains how the risk monotonic network can learn more accurately for weak coefficient variables:
Suppose there is such a formula:
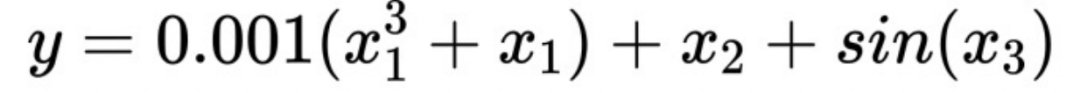
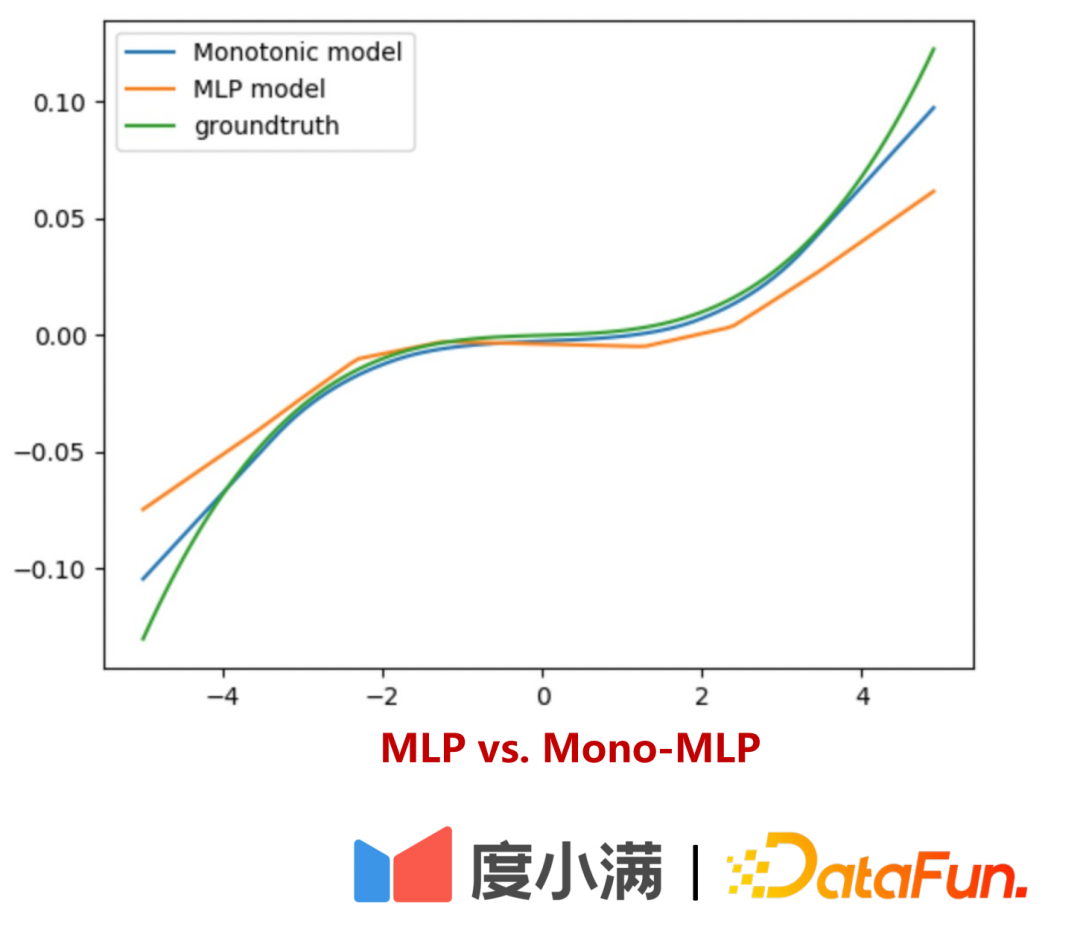
##You can see the # here ##x1 is a weak coefficient variable. When applying monotonicity to x1 After the sexual constraint, the estimation of the response Y is more accurate. Without such a separate constraint, the importance of x1 will be overwhelmed by x2, resulting in increased model bias.
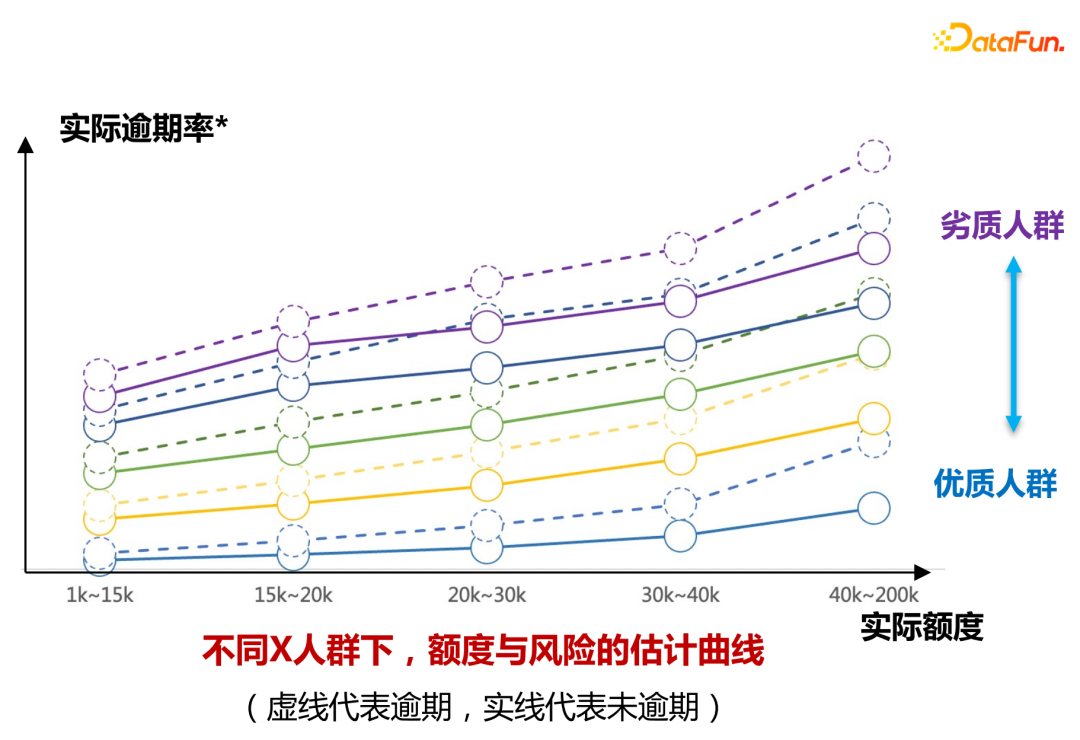
Under the condition that the quota increases by 30%, the overdue amount of users decreases by more than 20%, borrowing increases by 30%, and profitability increases by more than 30%.
Future model expectations:
Combine instrumental variables and adjustments in model-free form Variables are separated more clearly, allowing the model to perform better on risk transfer on inferior populations.
In actual business scenarios, Du Xiaoman’s model evolution iteration process is as follows:
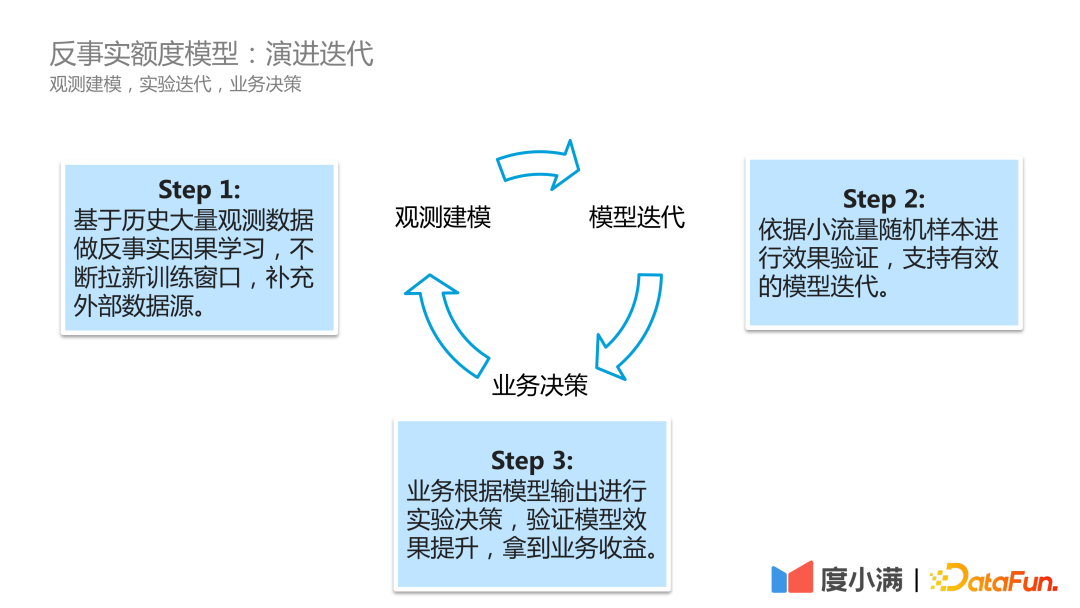
The first step is observation modeling, continuously scrolling historical observation data, doing counterfactual causal learning, and constantly opening new training windows. , supplemented by external data sources.
#The second step is model iteration. The effect is verified based on small traffic random samples to support effective model iteration.
#The third step is business decision-making. The business makes experimental decisions based on the model output to verify the model effect improvement and obtain business benefits.
The above is the detailed content of Duxiaoman quota model based on counterfactual causal inference. For more information, please follow other related articles on the PHP Chinese website!