

Bloom Filter (Bloom Filter) was proposed by Bloom in 1970. It is actually composed of a very long binary array and a series of hash algorithm mapping functions, which are used to determine whether an element exists in the set.
Bloom filters can be used to retrieve whether an element is in a collection. Its advantage is that space efficiency and query time are much better than ordinary algorithms. Its disadvantage is that it has a certain misrecognition rate and difficulty in deletion.
Assume there are 1 billion mobile phone numbers, and then determine whether a certain mobile phone number is in the list?
Is it possible with mysql?
Under normal circumstances, if the amount of data is not large, we can consider using mysql storage. Store all data in the database, and then query the database each time to determine whether it exists. However, if the amount of data is too large, exceeding tens of millions, the MySQL query efficiency will be very low, which will particularly consume performance.
Can HashSet be used?
We can put the data into HashSet and use the natural deduplication of HashSet. The query only needs to call the contains method, but the hashset is stored in the memory. If the amount of data is too large, the memory will be directly oom.
The insertion and query are efficient and take up less space, but the returned results are uncertain.
If an element is judged to exist, it may not actually exist. But if it is judged that an element does not exist, then it must not exist.
Bloom filter can add elements, but must not delete elements , which will increase the false positive rate.
A Bloom filter is actually a BIT array, which maps the corresponding hash through a series of hash algorithms, and then maps the hash corresponding to The array subscript position is changed to 1. When querying, a series of hash algorithms are performed on the data to obtain the subscript. The data is taken from the BIT array, such as . If it is 1, it means the data may exist. If it is 0, it means it definitely does not exist.
We know that the Bloom filter actually hashes the data, so no matter what algorithm is used, it is possible that the hashes generated by two different data are indeed the same, that is, we Commonly referred to as hash conflicts.
First insert a piece of data: Learn technology well
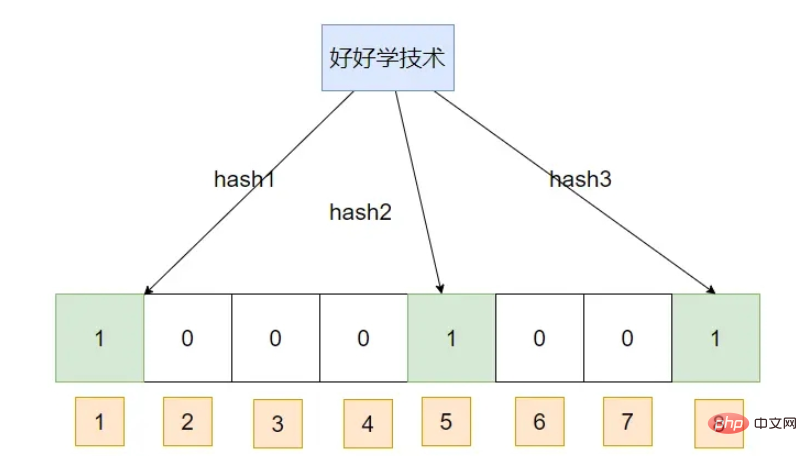
Insert a piece of data:
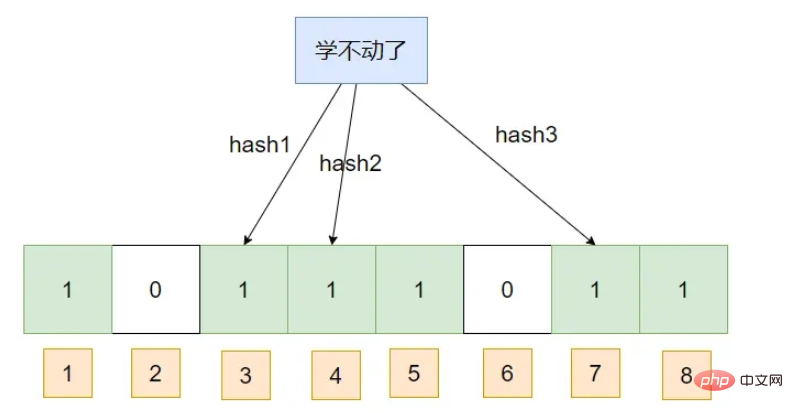
This If you query a piece of data, assuming that its hash subscript has been marked as 1, then the Bloom filter will think that it exists
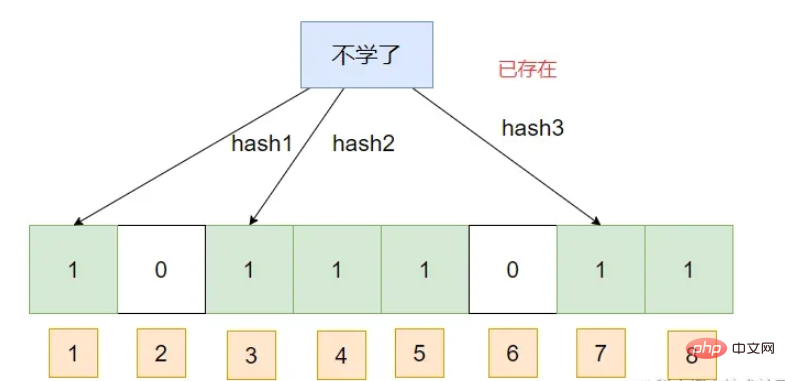
Cache penetration
package com.fandf.test.redis;
import java.util.BitSet;
/**
* java布隆过滤器
*
* @author fandongfeng
*/
public class MyBloomFilter {
/**
* 位数组大小
*/
private static final int DEFAULT_SIZE = 2 << 24;
/**
* 通过这个数组创建多个Hash函数
*/
private static final int[] SEEDS = new int[]{4, 8, 16, 32, 64, 128, 256};
/**
* 初始化位数组,数组中的元素只能是 0 或者 1
*/
private final BitSet bits = new BitSet(DEFAULT_SIZE);
/**
* Hash函数数组
*/
private final MyHash[] myHashes = new MyHash[SEEDS.length];
/**
* 初始化多个包含 Hash 函数的类数组,每个类中的 Hash 函数都不一样
*/
public MyBloomFilter() {
// 初始化多个不同的 Hash 函数
for (int i = 0; i < SEEDS.length; i++) {
myHashes[i] = new MyHash(DEFAULT_SIZE, SEEDS[i]);
}
}
/**
* 添加元素到位数组
*/
public void add(Object value) {
for (MyHash myHash : myHashes) {
bits.set(myHash.hash(value), true);
}
}
/**
* 判断指定元素是否存在于位数组
*/
public boolean contains(Object value) {
boolean result = true;
for (MyHash myHash : myHashes) {
result = result && bits.get(myHash.hash(value));
}
return result;
}
/**
* 自定义 Hash 函数
*/
private class MyHash {
private int cap;
private int seed;
MyHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
/**
* 计算 Hash 值
*/
int hash(Object obj) {
return (obj == null) ? 0 : Math.abs(seed * (cap - 1) & (obj.hashCode() ^ (obj.hashCode() >>> 16)));
}
}
public static void main(String[] args) {
String str = "好好学技术";
MyBloomFilter myBloomFilter = new MyBloomFilter();
System.out.println("str是否存在:" + myBloomFilter.contains(str));
myBloomFilter.add(str);
System.out.println("str是否存在:" + myBloomFilter.contains(str));
}
}Introducing dependencies
com.google.guava guava 31.1-jre
package com.fandf.test.redis;
import com.google.common.base.Charsets;
import com.google.common.hash.BloomFilter;
import com.google.common.hash.Funnels;
/**
* @author fandongfeng
*/
public class GuavaBloomFilter {
public static void main(String[] args) {
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),100000,0.01);
bloomFilter.put("好好学技术");
System.out.println(bloomFilter.mightContain("不好好学技术"));
System.out.println(bloomFilter.mightContain("好好学技术"));
}
} Introducing dependencies
cn.hutool hutool-all 5.8.3
package com.fandf.test.redis;
import cn.hutool.bloomfilter.BitMapBloomFilter;
import cn.hutool.bloomfilter.BloomFilterUtil;
/**
* @author fandongfeng
*/
public class HutoolBloomFilter {
public static void main(String[] args) {
BitMapBloomFilter bloomFilter = BloomFilterUtil.createBitMap(1000);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
}Introducing dependencies
org.redisson redisson 3.20.0
package com.fandf.test.redis;
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
/**
* Redisson 实现布隆过滤器
* @author fandongfeng
*/
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer().setAddress("redis://127.0.0.1:6379");
//构造Redisson
RedissonClient redisson = Redisson.create(config);
RBloomFilter bloomFilter = redisson.getBloomFilter("name");
//初始化布隆过滤器:预计元素为100000000L,误差率为1%
bloomFilter.tryInit(100000000L,0.01);
bloomFilter.add("好好学技术");
System.out.println(bloomFilter.contains("不好好学技术"));
System.out.println(bloomFilter.contains("好好学技术"));
}
} The above is the detailed content of How to implement bloom filter in Java?. For more information, please follow other related articles on the PHP Chinese website!