Home > Article > Technology peripherals > Machine learning powers high-quality software engineering

Translator | Zhu Xianzhong
##Revised | Sun Shujuan
IntroductionGenerally speaking, Software testing tends to be relatively simple: every input => known output. However, throughout the history of software testing, you will find that many tests often remain at the level of guesswork. In other words, during testing, the developer imagines the user's operation process, estimates the possible load and analyzes the time it will take, then runs the test and compares the current results with the baseline answer. If we find that there is no regression, then the current build plan is considered correct; then, continue with subsequent testing. If there is a regression, return it. Most of the time, we already know the output, although it needs to be better defined - the boundaries of the regression are clear and not that fuzzy. In fact, this is where machine learning (ML) systems and predictive analytics come in – ending ambiguity.
After the test is completed, the performance engineer will not only look at the arithmetic mean and geometric mean of the results, they will also look at the relevant percentage data. For example, when the system is running, often 10% of the slowest requests are caused by system errors - this error will create a condition that always affects the speed of the program.
While we can manually correlate the attributes available in the data, ML may link the data attributes faster than you can. After identifying the conditions that cause 10% of bad requests, performance engineers can build test scenarios to reproduce the behavior. Running tests before and after a fix can help confirm that the fix has been corrected.

Figure 1: Overall Confidence in Performance Metrics
Performance of Machine Learning and Data ScienceMachine learning helps promote software development and makes the development technology more robust and better able to meet the needs of users in different fields and industries. We can expose causal patterns by feeding data from pipelines and environments into deep learning algorithms. Predictive analytics algorithms combined with performance engineering methods enable more efficient and faster throughput, gain insights into how end users use software in natural scenarios, and help developers reduce the likelihood of defective products being used in production environments . By identifying issues and their causes early on, you can correct them early in the development lifecycle and prevent impact on production. Overall, here are some ways you can leverage predictive analytics to improve application performance.
“Big Data” usually refers to a data set. Yes, it is a large data set, the speed increases quickly, and the content changes greatly. The analysis of such data requires specialized methods so that we can extract patterns and information from it. In recent years, improvements in storage, processors, process parallelism, and algorithm design have enabled systems to process large amounts of data in a reasonable amount of time, allowing for wider use of these methods. To obtain meaningful results, you must ensure data consistency.
For example, each project must use the same ranking system, so if one project uses 1 as a key value and another uses 5 - like people using "DEFCON 5 ” means “DEFCON 1”; then the values must be normalized before processing. Predictive algorithms consist of algorithms and the data they feed into, and software development generates vast amounts of data that, until recently, sat idle, waiting to be deleted. However, predictive analytics algorithms can process these files to ask and answer questions based on this data for patterns we cannot detect, such as: Are we wasting time testing unknowns? Scenario of use?
The other major component of predictive analytics is the algorithm; you need to choose or implement it carefully. Starting simple is crucial because models tend to become increasingly complex, increasingly sensitive to changes in input data, and potentially distort predictions. They can solve two types of problems: classification and regression (see Figure 2).
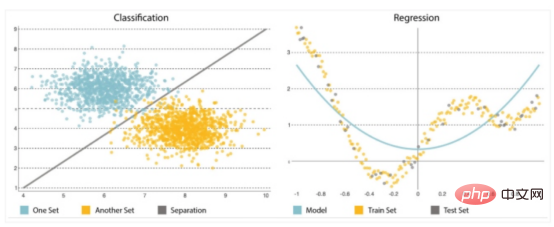
##Figure 2: Classification and Regression
Neural NetworkNeural networks learn by example and use historical and current data to predict future value. Their architecture allows them to identify complex relationships hidden in data, replicating the way our brains detect patterns. They consist of many layers that accept data, compute predictions and provide the output as a single prediction.
Decision TreeA decision tree is an analytical method that presents results in a series of "if/then" options to predict the potential risks of a specific option and earnings. It can solve all classification problems and answer complex questions.
As shown in Figure 3, a decision tree is similar to a top-down tree generated by an algorithm that recognizes various ways of splitting data into branch-like partitions to Explain future decisions and help identify decision paths.
If it takes more than three seconds to load, one branch in the tree might be a user who abandoned their cart. Below this, another branch may indicate whether they are female. A "yes" answer raises the stakes, as analysis shows women are more likely to make impulsive purchases, and this delay can lead to rumination.
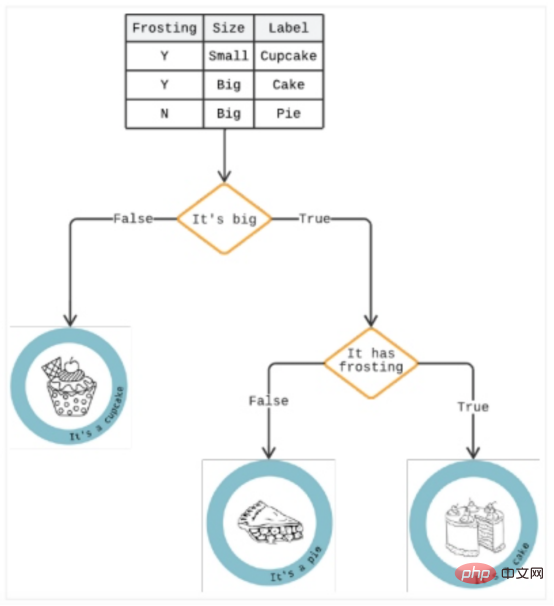
Figure 3: Decision tree example
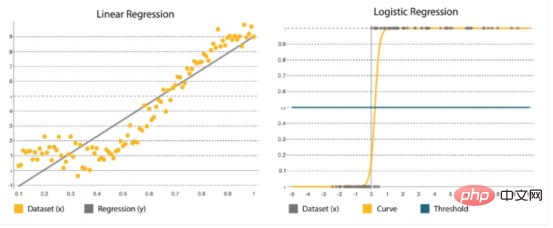
Linear and logistic regressionRegression It is one of the most popular statistical methods. This is critical when estimating numbers, such as how many additional resources we need to add to each service during the Black Friday sale. Many regression algorithms are designed to estimate relationships between variables and find key patterns in large and mixed data sets, as well as the relationships between them. It ranges from simple linear regression models (computing a straight line function that fits the data) to logistic regression (computing a curve) (Figure 4).
#Linear and Logistic RegressionOverall comparison | |
| ##Linear return
|
Logistic regression |
## is used to define values in a continuous range, such as the risk of user traffic spikes in the next few months. |
#This is a statistical method in which parameters are predicted based on old sets. It works best for binary classification: datasets where y=0 or 1, where 1 represents the default class . Its name comes from its conversion function ( is a logical function ) . |
It is expressed as y=a bx, where x is the input set used to determine the output y. The coefficients a and b are used to quantify the relationship between x and y, where a is the intercept and b is the slope of the line. |
It is represented by a logical function: where, β0 is the intercept, β1 is the rate. It uses training data to calculate coefficients that minimize the error between predicted and actual results. |
The goal is to fit the straight line closest to most points, reducing the distance or error between y and the straight line. |
# It forms an S-shaped curve where a threshold is applied to convert the probabilities into binary classifications. |
The above is the detailed content of Machine learning powers high-quality software engineering. For more information, please follow other related articles on the PHP Chinese website!