
Home > Article > Backend Development > Scrapy implements Sina Weibo crawler

This article mainly talks about using scrapy to implement Sina Weibo crawler. It has certain reference value. Interested friends can learn more and see You might as well try it yourself!
Recently, due to the completion of the project, a batch of data needs to be collected. Based on the principle of do-it-yourself, we collected the Weibo contents of nearly a hundred well-known celebrities from 14 to 18 years from Sina Weibo. Take a look at what the big guys usually post on Weibo~
1. First of all, the project is written in scrapy, which saves time and effort. Whoever uses it will know.
The collected website is weibo.com, which is the web page of Weibo. It's a little more troublesome, but the content is slightly more comprehensive compared to mobile segments and wap sites.
2. Before collecting, let’s first take a look at what obstacles Weibo has set up for us.
Since Weibo defaults to 302 jump to the login interface for users who have not logged in, so Weibo is collected Qian must make Weibo think that this collection was too lazy. They directly logged in manually and then saved the cookie to scrapy. When requesting, bring the cookie to visit, because the collection volume is not very large, it is estimated that it is only 100,000 items. about. Here we need to remind those who are new to scrapy that scrapy's cookies are in a form similar to json. It is not like pasting it directly on requests and using it. You need to convert the format. 
It’s probably like this, so you need to paste the cookie after logging in and convert it with the code. The code is as follows:
class transCookie:
def __init__(self, cookie):
self.cookie = cookie
def stringToDict(self):
itemDict = {}
items = self.cookie.split(';')
for item in items:
key = item.split('=')[0].replace(' ', '')
value = item.split('=')[1]
itemDict[key] = value
return itemDict
if __name__ == "__main__":
cookie = "你的cookie"
trans = transCookie(cookie)
print(trans.stringToDict()) I think one cookie is almost enough. Three cookies are saved. The simple way to store multiple cookies is to put multiple cookies directly in an array, and use the random function to randomly pick one out every time a request is made. Of course, this is only for the situation where a batch of data is collected and then withdrawn. , an account pool must be maintained on a large scale. Bring ua and cookie when requesting. As follows: 
Weibo distinguishes each user by oid. Let’s take Daniel Wu’s Weibo as an example. Search for Daniel Wu on the Weibo search interface, right-click on the homepage to view the source code of the web page. We can see: 
The oid here is the unique identifier of each user. The corresponding user's homepage address is https://weibo.com oid.
With the address, we can directly enter the Weibo interface to collect it and piece together the url address, for example:
https://weibo. com/wuyanzu?is_all=1&stat_date=201712#feedtop
This is Wu Yanzu’s Weibo in December 2017. It is not difficult to find that we only need to change the number after stat_date to get the corresponding Weibo address. For some users with a large amount of Weibo, the monthly Weibo may also involve loading js again. Of course, our cool male god Mr. Wu Yanzu will definitely not post so much. Let’s find another Weibo to compare. For large self-media, for example: 
, you can see that the remaining Weibo needs to be presented to users through js asynchronous loading. Open the browser developer mode, 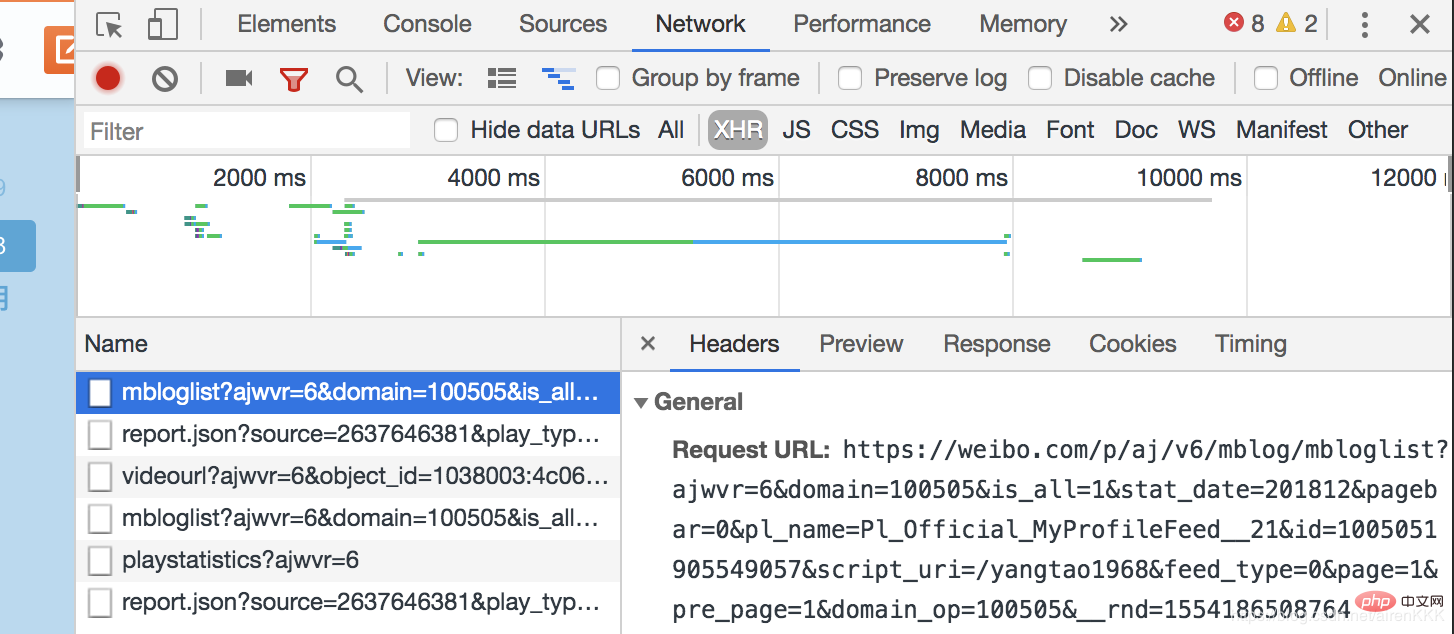

Comparing the pages loaded with js twice, we can easily find that the difference between Request_URL is only in pagebar and _rnd In terms of parameters, the first one represents the number of pages, and the second one is the encryption of time (it doesn’t matter if you don’t use it for testing), so we only need to construct the number of pages. Some Weibo posts with huge volume may still need to be turned over, the same principle applies.
class SpiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
nickname = scrapy.Field()
follow = scrapy.Field()
fan = scrapy.Field()
weibo_count = scrapy.Field()
authentication = scrapy.Field()
address = scrapy.Field()
graduated = scrapy.Field()
date = scrapy.Field()
content = scrapy.Field()
oid = scrapy.Field()设置需要爬取的字段nickname昵称,follow关注,fan粉丝,weibo_count微博数量,authentication认证信息,address地址,graduated毕业院校,有些微博不显示的默认设置为空,以及oid和博文内容及发布时间。
这里说一下内容的解析,还是吴彦祖微博,如果我们还是像之前一样直接用scrapy的解析规则去用xpath或者css选择器解析会发现明明结构找的正确却匹配不出数据,这就是微博坑的地方,点开源代码。我们发现:
微博的主题内容全是用script包裹起来的!!!这个问题当初也是困扰了博主很久,反复换着法子用css和xpath解析始终不出数据。
解决办法:正则匹配(无奈但有效)
至此,就可以愉快的进行采集了,附上运行截图:
输入导入mongodb:
相关教程:Python视频教程
The above is the detailed content of Scrapy implements Sina Weibo crawler. For more information, please follow other related articles on the PHP Chinese website!