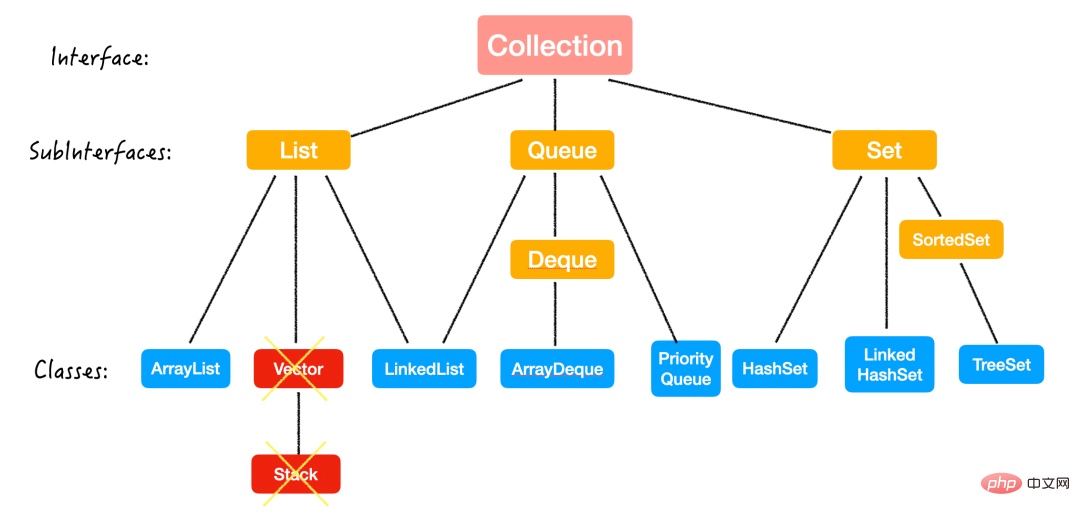
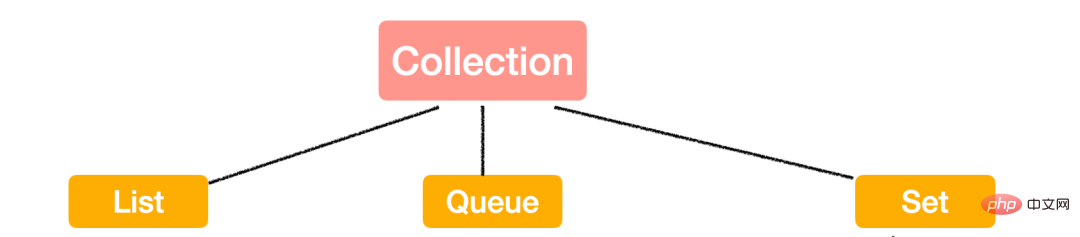
Java-Sammlungen, auch Container genannt, bestehen hauptsächlich aus Abgeleitet von zwei Hauptschnittstellen (Interface): 两大接口 (Interface) 派生出来的: Collection 和 MapWie der Name schon sagt, Container dienen der Speicherung von Daten.
Dann ist der Unterschied zwischen diesen beiden Schnittstellen:
Collection speichert ein einzelnes Element;
Map speichert Schlüssel-Wert-Paare.
Das heißt, Singles werden in der Sammlung und Paare in der Karte platziert. (Also, wo gehören Sie hin?
Beim Erlernen dieser Sammlungsframeworks gibt es meiner Meinung nach vier Ziele:
Klare die Entsprechung zwischen jeder Schnittstelle und Klasse;
Seien Sie mit häufig verwendeten APIs für jede Schnittstelle vertraut und Klasse;
Seien Sie in der Lage, geeignete Datenstrukturen auszuwählen und die Vor- und Nachteile für verschiedene Szenarien zu analysieren.
Lernen Sie das Design von Quellcode und können Sie Interviews beantworten Auf HashMap wurde bereits sehr ausführlich darüber gesprochen, daher werde ich in diesem Artikel nicht auf Details eingehen. Wenn Sie diesen Artikel noch nicht gelesen haben, gehen Sie bitte zum offiziellen Konto und antworten Sie auf „HashMap
“. " um den Artikel zu lesen~
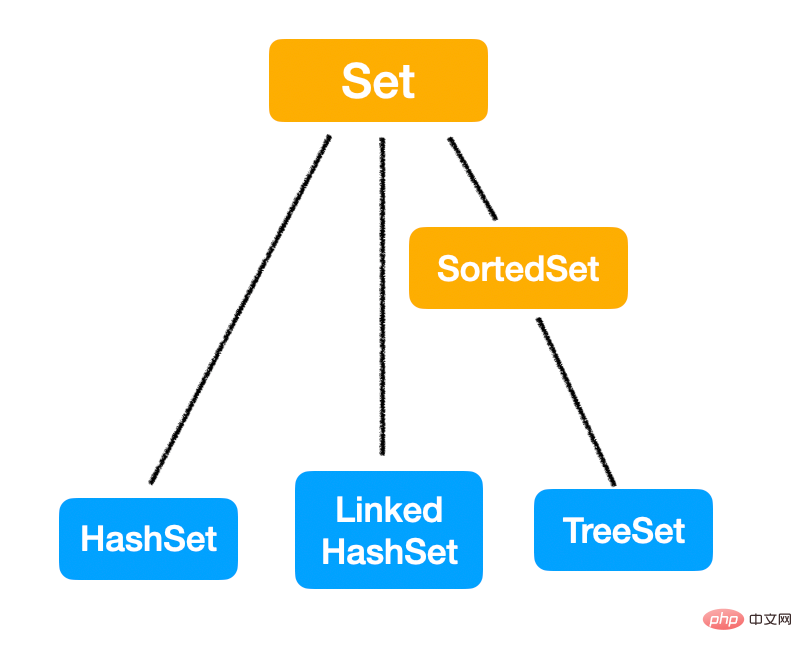
Sammlung
Schauen wir uns zuerst die Sammlung der obersten Ebene an.
Collection definiert auch viele Methoden, die auch in verschiedene Unterschnittstellen und Implementierungsklassen vererbt werden. Die Verwendung dieser APIs ist auch ein häufiger Test in der täglichen Arbeit und in Interviews, also werfen wir zunächst einen Blick auf diese Methoden.
Der Operationssatz besteht aus nichts anderem als den vier Kategorien „Hinzufügen, Löschen, Ändern und Überprüfen“, auch genannt CRUD:
Erstellen, Lesen, Aktualisieren und Löschen.
Dann unterteile ich diese APIs auch in diese vier Kategorien:
.
Funktion
Methode
add
add()/addAll()
delete
remove()/removeAll()
verändern
Nicht verfügbar in der Sammlungsschnittstelle
Check
contains()/containsAll()
Others
isEmpty()/size()/toArray()
Sehen Sie es sich unten im Detail an:
Hinzugefügt:
boolean add(E e);
add() Der übergebene Datentyp muss Object sein, sodass beim Schreiben des Basisdatentyps das automatische Boxen und automatische Entpacken durchgeführt wird Box-Unboxing. add() 方法传入的数据类型必须是 Object,所以当写入基本数据类型的时候,会做自动装箱 auto-boxing 和自动拆箱 unboxing。
还有另外一个方法 addAll(),可以把另一个集合里的元素加到此集合中。
boolean addAll(Collection<? extends E> c);
删:
boolean remove(Object o);
remove()是删除的指定元素。
那和 addAll() 对应的, 自然就有removeAll()
Es gibt eine andere Methode
boolean removeAll(Collection<?> c);
Löschen:
boolean contains(Object o);
remove() ist das angegebene Element, das gelöscht wird. 🎜🎜NaheremoveAll() soll alle Elemente in Satz B löschen. 🎜
boolean containsAll(Collection<?> c);
🎜🎜🎜Änderung: 🎜🎜🎜🎜Es gibt keine direkte Operation zum Ändern von Elementen in der Sammlungsoberfläche. Durch Löschen und Hinzufügen kann die Änderung jedoch abgeschlossen werden! 🎜
查:
查下集合中有没有某个特定的元素:
boolean contains(Object o);
查集合 A 是否包含了集合 B:
boolean containsAll(Collection<?> c);
还有一些对集合整体的操作:
判断集合是否为空:
boolean isEmpty();
集合的大小:
int size();
把集合转成数组:
Object[] toArray();
以上就是 Collection 中常用的 API 了。
在接口里都定义好了,子类不要也得要。
当然子类也会做一些自己的实现,这样就有了不同的数据结构。
那我们一个个来看。
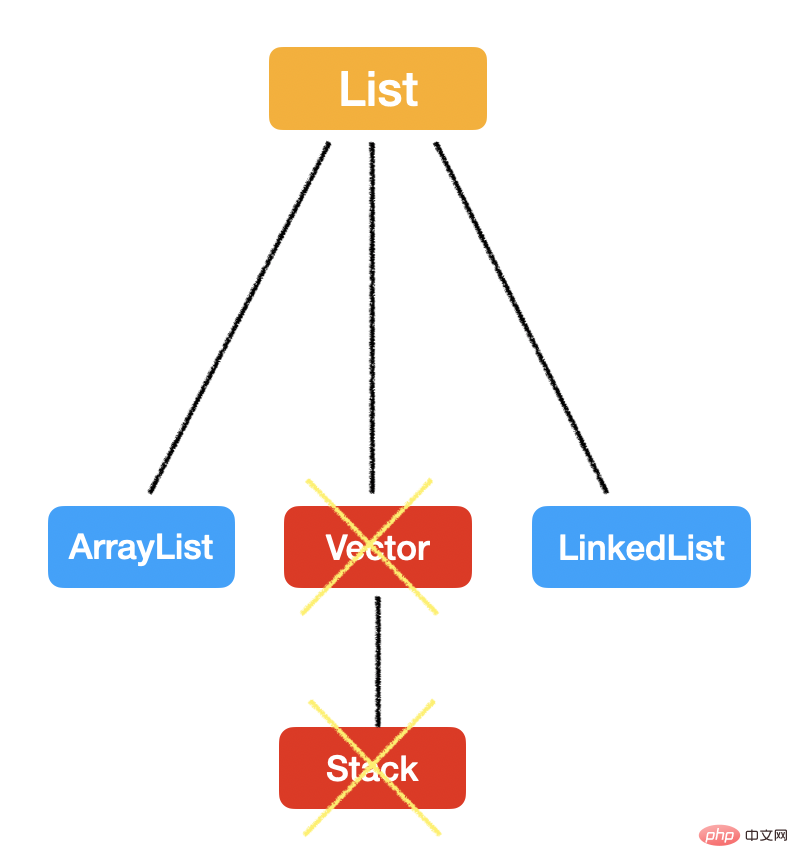
List
List 最大的特点就是:有序,可重复。
看官网说的:
An ordered collection (also known as a sequence).
Unlike sets, lists typically allow duplicate elements.
Dieses Mal habe ich auch die Eigenschaften von Set erwähnt. Es ist das völlige Gegenteil von Set. 无序,不重复
List kann auf zwei Arten implementiert werden: LinkedList und ArrayList. Die in Interviews am häufigsten gestellte Frage ist, wie man zwischen diesen beiden Datenstrukturen wählt. Für diese Art von Auswahlproblem:
Überlegen Sie zunächst, ob die Datenstruktur die erforderlichen Funktionen erfüllen kann. Wenn sie abgeschlossen werden kann, überlegen Sie zweitens, welche effizienter ist. (Alles ist so.
Schauen wir uns speziell die APIs dieser beiden Klassen und ihre zeitliche Komplexität an:
Funktion
Methode
ArrayList
LinkedList
add
add(E e)
O(1)
O(1)
erhöhen
add(int Index, E E) E e)
O(n)
O(n)
change
set(int index, E e)
O(1)
O(n)
check
get (int index)
O(1)
O(n)
Ein paar Erklärungen:
add(E e) fügt dem Ende Elemente hinzu. Obwohl ArrayList erweitert werden kann, beträgt die amortisierte Zeitkomplexität immer noch O(1). add(E e) 是在尾巴上加元素,虽然 ArrayList 可能会有扩容的情况出现,但是均摊复杂度(amortized time complexity)还是 O(1) 的。
add(int index, E e)是在特定的位置上加元素,LinkedList 需要先找到这个位置,再加上这个元素,虽然单纯的「加」这个动作是 O(1) 的,但是要找到这个位置还是 O(n) 的。(这个有的人就认为是 O(1),和面试官解释清楚就行了,拒绝扛精。
remove(int index) dient zum Entfernen des Elements an diesem Index, sodass
ArrayList dieses Element findet ist O(1), aber nach dem Entfernen müssen nachfolgende Elemente um eine Position nach vorne verschoben werden, sodass die amortisierte Komplexität O(n) ist;
LinkedList muss auch zuerst den Index finden, und dieser Prozess ist O(n). ), also ist das Ganze auch O(n)
remove(E e) ist das erste von Remove gesehene Element, dann muss
ArrayList dieses Element zuerst finden. Dieser Prozess ist O(n) und wird dann verschoben Nach der Division muss man sich um eine Position nach vorne bewegen, also O(n), und die Summe ist immer noch O(n); entfernt, dieser Prozess ist O(1) und die Summe ist O(n).Was ist der Grund für den Unterschied in der Zeitkomplexität? mit einem Array.
Der größte Unterschied zwischen Arrays und verknüpften Listen besteht darin, dass
auf Arrays zufällig zugegriffen werden kann (wahlfreier Zugriff).
Diese Funktion ermöglicht es, die Zahl an jeder Position im Array in O(1)-Zeit durch Subskription abzurufen. Dies ist jedoch mit der verknüpften Liste nicht möglich und sie kann nur einzeln von der durchlaufen werden Anfang.
🎜Das heißt, in Bezug auf die beiden Funktionen „Änderung und Abfrage“ ist ArrayList sehr effizient, da auf das Array zufällig zugegriffen werden kann. 🎜
Was ist mit „Hinzufügen und Löschen“?
Wenn die Zeit zum Suchen dieses Elements nicht berücksichtigt wird,
Aufgrund der physischen Kontinuität des Arrays ist es beim Hinzufügen oder Löschen von Elementen am Ende in Ordnung, aber an anderen Stellen werden nachfolgende Elemente verschoben, sodass die Die Effizienz ist geringer; und verknüpfte Listen können leicht vom nächsten Element getrennt werden, neue Elemente direkt einfügen oder alte Elemente entfernen.
Aber tatsächlich muss man die Zeit berücksichtigen, um die Elemente zu finden. . . Und wenn es am Ende betrieben wird, ist ArrayList schneller, wenn die Datenmenge groß ist.
So:
Change und Select ArrayList; Es wird empfohlen, ArrayList zu wählen, da der Overhead geringer ist oder die Speichernutzung effizienter ist.
Vector
Als letzten Wissenspunkt über List sprechen wir über Vector. Dies ist auch ein altersaufschlussreicher Beitrag, der von allen großen Jungs verwendet wird. Dann erbt Vector wie ArrayList auch von java.util.AbstractList, und die unterste Ebene wird ebenfalls mithilfe von Arrays implementiert.
Aber es ist jetzt veraltet, weil ... es zu viel synchronisiert hinzufügt! Jeder Vorteil hat seinen Preis: Die geringe Effizienz kann in manchen Systemen leicht zu einem Engpass werden. Deshalb übertragen wir diese Aufgabe nicht mehr auf die Ebene der Datenstruktur ==
Die häufige Frage im Vorstellungsgespräch: Was ist der Unterschied zwischen Vector und ArrayList? Die bloße Beantwortung dieser Frage ist nicht sehr umfassend.
Werfen wir einen Blick auf die am häufigsten bewerteten Antworten zum Thema Stapelüberlauf:
Das erste ist das gerade erwähnte Thread-Sicherheitsproblem;
Das zweite ist der Unterschied darin, wie viel beim Erweitern erweitert werden soll.
Dazu müssen Sie sich den Quellcode ansehen:
Dies ist eine Erweiterungsimplementierung von ArrayList. Diese arithmetische Rechtsverschiebung
dient dazu, die Binärzahl dieser Zahl um eins nach rechts zu verschieben das ganz linke
Komplementzeichenbit , aber weil Es gibt keine negative Zahl in der Kapazität, also addieren wir immer noch 0.
Der Effekt der Verschiebung um eine Position nach rechts besteht darin, durch 2 zu dividieren, dann ist die neue definierte Kapazität
1,5 Mal
der ursprünglichen Kapazität. Schauen wir uns noch einmal Vector an:
Da das Kapazitätsinkrement normalerweise nicht von uns definiert wird, wird es standardmäßig zweimal erweitert.
Wenn Sie diese beiden Punkte beantworten, wird es Ihnen auf jeden Fall gut gehen.
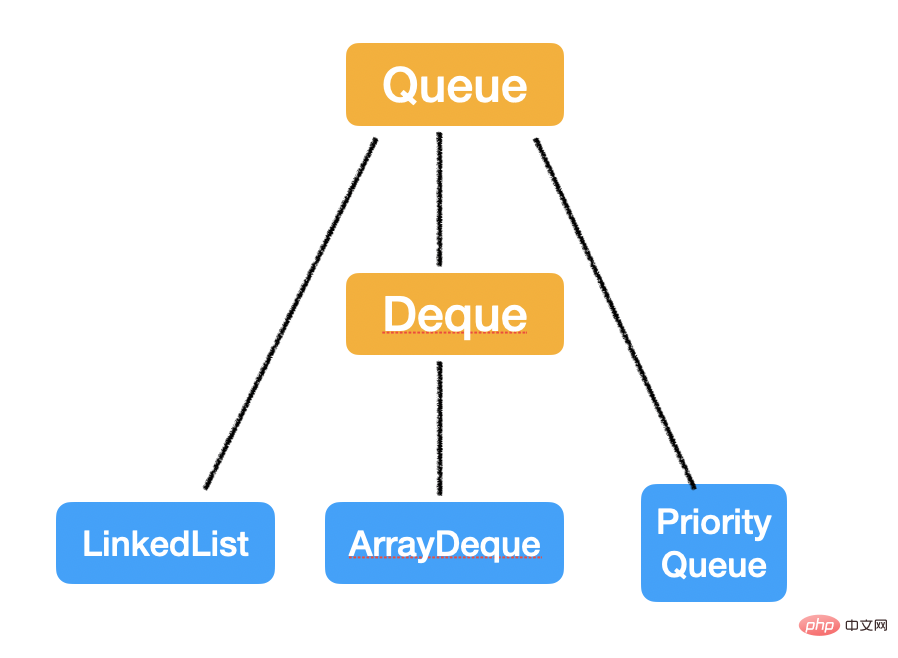
Queue & Deque
Queue ist eine lineare Datenstruktur, die an einem Ende eingeht und am anderen Ende ausgeht, während Deque an beiden Enden ein- und ausgehen kann.
Warteschlange
Die Warteschlangenschnittstelle in Java ist im Allgemeinen etwas verwirrend. Die Semantik von Warteschlangen lautet „First in first out“ (FIFO). Hier gibt es jedoch eine Ausnahme: PriorityQueue, auch Heap genannt, wird nicht in der Reihenfolge der Eintrittszeit ausgegeben, sondern gemäß der angegebenen Priorität. Die Berechnung erfolgt nicht nach O (1). Zeitkomplexität Es ist etwas kompliziert, daher werden wir es später in einem separaten Artikel besprechen.
Die Warteschlangenmethode
offizielle Website
[1] wurde zusammengefasst. Sie verfügt über zwei Sätze von APIs und die Grundfunktionen sind die gleichen, aber:
Eine Gruppe löst eine Ausnahme aus.
Die andere Gruppe gibt einen Sonderwert zurück.
Funktion
Ausnahme auslösen
Rückgabewert
Hinzufügen
hinzufügen(e)
Angebot(e)
Löschen
remove()
poll()
Look
element()
peek()
Warum wird eine Ausnahme ausgelöst?
Wenn die Warteschlange beispielsweise leer ist, löst remove() eine Ausnahme aus, poll() gibt jedoch null zurück; element() gibt eine Ausnahme zurück und peek() gibt einfach null zurück.
Wie kommt es, dass add(e) eine Ausnahme auslöst?
Einige Warteschlangen haben Kapazitätsgrenzen, wie z. B. BlockingQueue Wenn sie ihre maximale Kapazität erreicht hat und nicht erweitert wird, wird eine Ausnahme ausgelöst. Bei offer(e) wird jedoch false zurückgegeben.
Also Wie wählt man? :
Wenn Sie es verwenden möchten, verwenden Sie zunächst den gleichen Satz von APIs, und die Vorder- und Rückseite sollten vereinheitlicht werden.
Zweitens je nach Bedarf. Wenn Sie es zum Auslösen von Ausnahmen benötigen, verwenden Sie das, das Ausnahmen auslöst. Bei Algorithmusproblemen wird es jedoch grundsätzlich nicht verwendet. Wählen Sie daher einfach das aus, das spezielle Werte zurückgibt.
Deque
Deque kann von beiden Enden betreten und verlassen werden. Natürlich gibt es Operationen für die erste Seite und Operationen für die letzte Seite. Dann gibt es zwei Gruppen an jedem Ende eine Ausnahme und die andere Gruppe Sonderwert zurückgeben:
Funktion
Ausnahme auslösen
Rückgabewert
add
addFirst(e)/ addLast(e)
offerFirst(e)/ offerLast (e)
Delete
removeFirst()/ removeLast()
pollFirst()/ pollLast()
Look
getFirst()/ getLast()
peekFirst()/ peekLast()
Das Gleiche gilt für die Verwendung. Wenn Sie es verwenden möchten, verwenden Sie dieselbe Gruppe.
Diese APIs von Queue und Deque haben eine Zeitkomplexität von O(1). Genauer gesagt handelt es sich um eine amortisierte Zeitkomplexität.
Implementierungsklassen
Es gibt drei Implementierungsklassen:
Also
Wenn Sie die Semantik von „normale Warteschlange – First In First Out“ implementieren möchten, verwenden Sie LinkedList oder ArrayDeque To erreichen;
Wenn Sie die Semantik von „Prioritätswarteschlange“ implementieren möchten, verwenden Sie PriorityQueue;
Wenn Sie die Semantik von „Stack“ implementieren möchten.
Schauen wir uns einen nach dem anderen an.
Beim Implementieren einer gemeinsamen Warteschlange: Wie wähle ich zwischen LinkedList oder ArrayDeque?
Werfen wir einen Blick auf die hoch bewertete Antwort auf StackOverflow[2]:
Zusammenfassend wird empfohlen, ArrayDeque aufgrund seiner hohen Effizienz zu verwenden, während LinkedList anderen zusätzlichen Overhead verursacht (über Kopf).
Was sind die Unterschiede zwischen ArrayDeque und LinkedList?
Immer noch bei der gleichen Frage, das ist meiner Meinung nach die beste Zusammenfassung:
ArrayDeque ist ein erweiterbares Array, LinkedList ist eine verknüpfte Listenstruktur;
ArrayDeque kann keine Nullwerte speichern, aber LinkedList kann;
ArrayDeque ist beim Ausführen der Additions- und Löschvorgänge am Anfang und Ende effizienter, LinkedList entfernt jedoch nur ein Element in der Mitte, wenn es entfernt werden soll und das Element gefunden wurde ( 1);
ArrayDeque ist hinsichtlich der Speichernutzung effizienter.
Solange Sie also keine Nullwerte speichern müssen, wählen Sie ArrayDeque!
Wenn Sie dann ein sehr erfahrener Interviewer fragt, unter welchen Umständen sollten Sie sich für die Verwendung von LinkedList entscheiden?
Der Wert wird auf dem Schlüssel in der Karte platziert, und ein PRESENT wird auf dem Wert platziert. Es handelt sich um ein statisches Objekt, das einem Platzhalter entspricht, und jeder Schlüssel zeigt auf dieses Objekt.
Das spezifische Implementierungsprinzip, Hinzufügen, Löschen, Ändern, Überprüfenvier Operationen sowie Hash-Konflikt, hashCode()/equals() und andere Probleme wurden alle im HashMap-Artikel besprochen , hier werde ich nicht auf Details eingehen. Freunde, die es nicht gelesen haben, können auf „HashMap“ im Hintergrund des offiziellen Kontos antworten, um den Artikel zu erhalten Gehen Sie noch einmal auf das Bild vom Anfang zurück. Ist es klar? Wie wäre es mit einigen?
Es gibt tatsächlich viele Inhalte unter jeder Datenstruktur, wie z. B. PriorityQueue. Dieser Artikel geht nicht auf Details ein, da dieser Typ lange brauchen wird, um darüber zu sprechen. . Wenn Sie den Artikel gut finden, ist das Like am Ende des Artikels wieder da. Denken Sie daran, mir „Gefällt mir“ und „Lesen“ zu geben~Zuletzt haben mir viele Leser Fragen zur Kommunikation gestellt Gruppe, weil ich darüber nachdenke, ich habe einen Jetlag und es ist schwer damit umzugehen, also habe ich es noch nicht gemacht.
Aber jetzt habe ich einen professionellen Administrator gefunden, der es mit mir verwaltet, daher ist „Sister Qi's Secret Base“ in Vorbereitung und ich werde einige große Namen im In- und Ausland einladen, mitzumachen, um Ihnen eine andere Perspektive zu bieten. Dann soll Mitte bis Anfang Juli die erste Austauschgruppe eröffnet werden. Ich werde dann Einladungen im Freundeskreis verschicken, also bleibt dran!
Das obige ist der detaillierte Inhalt vonEs reicht aus, diesen Artikel über das Java Collection Framework zu lesen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
Stellungnahme:
Dieser Artikel ist reproduziert unter:Java学习指南. Bei Verstößen wenden Sie sich bitte an admin@php.cn löschen


 Dies ist eine Erweiterungsimplementierung von ArrayList. Diese
Dies ist eine Erweiterungsimplementierung von ArrayList. Diese 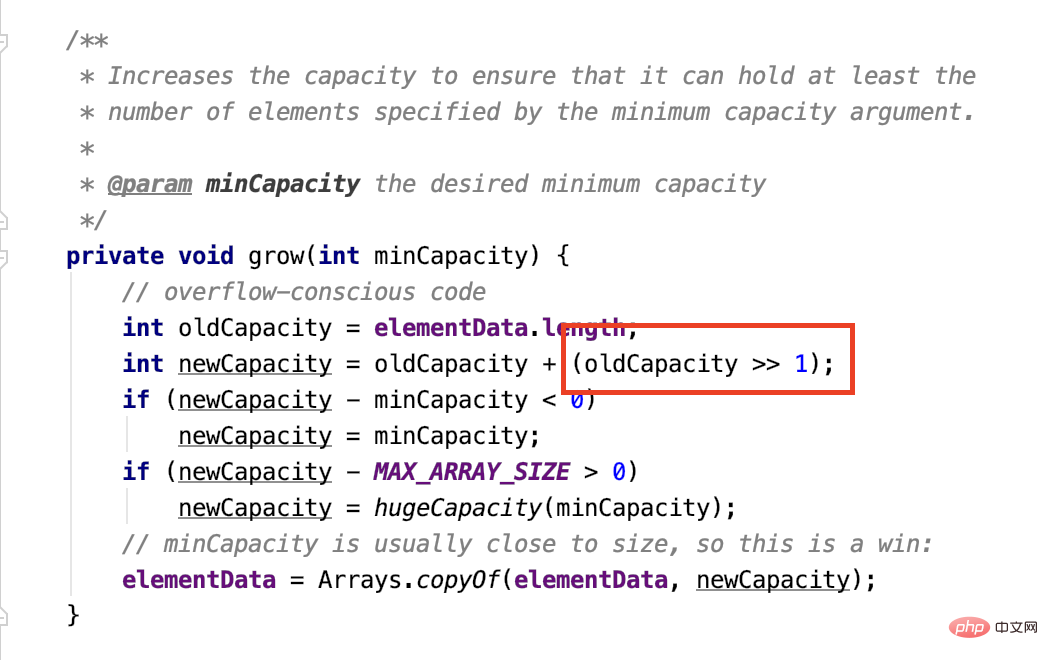 Schauen wir uns noch einmal Vector an:
Schauen wir uns noch einmal Vector an: