



回复内容:
谢邀。我又来安利xpath了,放弃正则表达式吧少年。
//span[@class="pro-title"]/text()
(?<=>).*?(?=<)
如果实际情况中有许多不同的“<>”对,就请自行填充前后向断言的内容
你应该看看汉字编码,网页的编码很可能是GBK,然而python是用的utf8,所以绝对匹配不了


怒答,看到不懂正则的还瞎BB,为你感到悲哀!上图!
---------------代码区----------------
# coding:utf-8
import re
x='Apple iPhone 5s (A1530) 16GB 金色 移动联通4G手机 '
xre=r'()(.+)( )'
z=re.search(xre,x).group(2)
print z
----------输出区-----------------------
C:\Python27\python.exe D:/PycharmProjects/爬虫/test.py
Apple iPhone 5s (A1530) 16GB 金色 移动联通4G手机
进程已结束,退出代码0
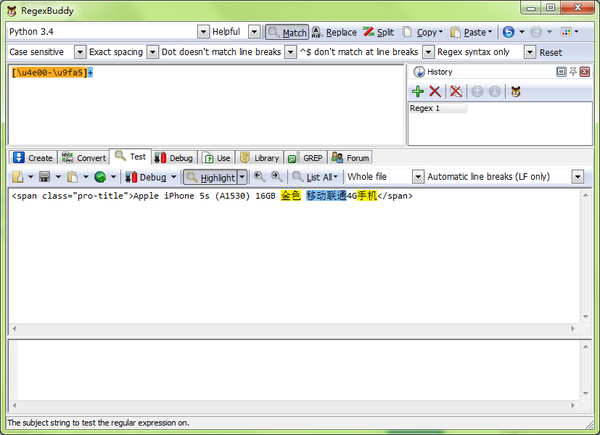
先用靓汤或正则找到这个节点,再用上面的字符组匹配。
假设这个节点只有一个,用法如下:
import re
import requests as req
from bs4 import BeautifulSoup
url = 'xxx'
html = req.get(url).text
bs = BeautifulSoup(html)
span = bs.find_all('span', 'pro-title')
'''
span = re.findall('[^<]+ ', html)
s = span[0]
m = re.findall('[\u4e00-\u9fa5]+', s)
'''
s = str(span)
m = re.findall('[\u4e00-\u9fa5]+', s)
print(m)

相关文章推荐
• 一文搞定Python列表、字典、元组和集合• Python详细解析之容器、可迭代对象、迭代器以及生成器• Python数据结构与算法学习之双端队列• 带你搞懂Python反序列化• python实例详解之xpath解析
jquery 基础视频教程
jQuery 很容易学习,希望通过我们的《jquery 基础视频教程》可以帮助大家来更好的学习jQuery。 jQuery 是一个 JavaScript 库,简化了 JavaScript 编程。
jQuery教程51811次播放

javascript三级联动视频教程
《javascript三级联动视频教程》介绍了javascript开发的三级联动功能,该功能在日常使用中还是经常能用的到的一个。
JavaScript教程30776次播放

独孤九贱(3)_JavaScript视频教程
javascript是运行在浏览器上的脚本语言,连续多年,被评为全球最受欢迎的编程语言。是前端开发必备三大法器中,最具杀伤力。如果前端开发是降龙十八掌,好么javascript就是第18掌:亢龙有悔。没有它,你的前端生涯是不完整的。《php.cn独孤九贱(3)-JavaScript视频教程》课程特色:php中文网原创幽默段子系列课程,以恶搞,段子为主题风格的php视频教程!轻松的教学风格,简短的教学模式,让同学们在不知不觉中,学会了javascript知识。
JavaScript教程120904次播放

独孤九贱(6)_jQuery视频教程
jQuery是一个快速、简洁的JavaScript框架。设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。它封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互。 核心特性可以总结为:具有独特的链式语法和短小清晰的多功能接口;具有高效灵活的css选择器,并且可对CSS选择器进行扩展;拥有便捷的插件扩展机制和丰富的插件。兼容各种主流浏览器,如IE 6.0+、FF 1.5+、Safari 2.0+、Opera 9.0+等,是全球最流行的前端开发框架之一。PHP中文网根据最新版本,独家录制jQuery最新视频教程,回馈PHP中文网的新老用户。
jQuery教程99985次播放

传智播客JavaScript面向对象完成贪吃蛇游戏视频教程
《传智播客JavaScript面向对象完成贪吃蛇游戏视频教程》介绍了关于JavaScript面向对象的知识,利用面向对象的编程思想去完成贪吃蛇游戏。
JavaScript教程4143次播放














