
Home > Article > Backend Development > Python web crawler--about simple simulated login

Today’s article mainly introduces about Python web crawler-about simple simulated login, which has certain reference value. Now I share it with everyone. Friends in need can refer to
and get the web page The information is different. If you want to simulate login, you need to send some information to the server, such as account number, password, etc.
Simulating login to a website is roughly divided into the following steps:
1. First find the hidden information of the login website and copy its contents Save first (since the website I logged in here does not have additional information, there is no information filtering and saving here)
2. Submit the information
3. Obtain the information after login
Give me the source code first
# -*- coding: utf-8 -*-
import requests
def login():
session = requests.session()
# res = session.get('http://my.its.csu.edu.cn/').content
login_data = {
'userName': '3903150327',
'passWord': '136510',
'enter': 'true'
}
session.post('http://my.its.csu.edu.cn//', data=login_data)
res = session.get('http://my.its.csu.edu.cn/Home/Default')
print(res.text)
login()
##1. Filter to get hidden information
Enter the developer tools (press F12), find the Network, log in manually, and find the first request. There will be a data segment at the bottom of the Header. This Just the information needed to log in. If you want to modify the hidden informationGet the Html content of the web page firstres = session.get('http://my.its.csu.edu.cn/').content
Then filter the content through regular expressions
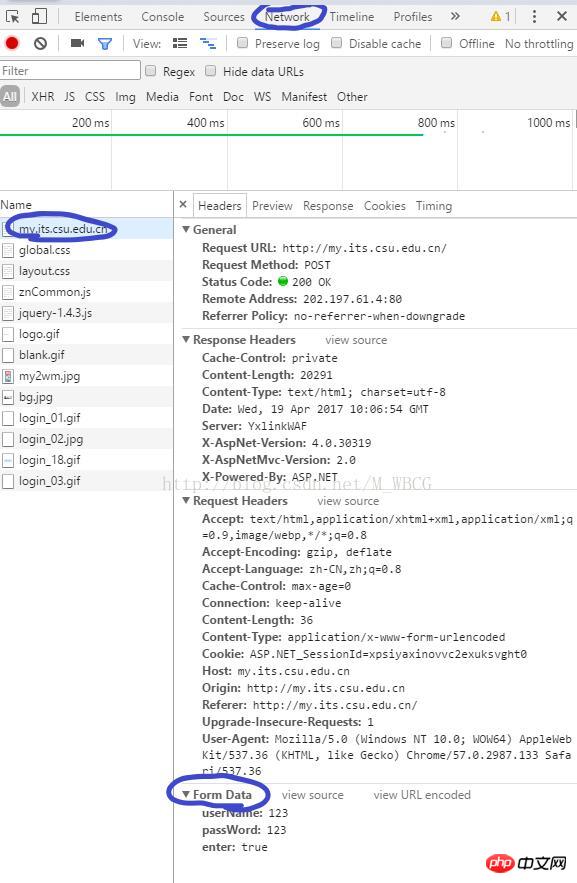
2. Submit the information
Find the action and method required to submit the form in the source codeUsesession.post('http://my.its.csu.edu.cn/(这里就是提交的action)', data=login_data)
This method submits information
3. Obtain information after login
After the information is submitted, the simulated login is successfulThen you can get the login informationres = session.get('http://my.its.csu.edu.cn/Home/Default').content
Related recommendations:
Instance of Python crawler grabbing proxy IP and checking availability
Python crawler browser identification library
The above is the detailed content of Python web crawler--about simple simulated login. For more information, please follow other related articles on the PHP Chinese website!