




脚本的主要工作是模拟了浏览器登录,解析“已买到的宝贝”页面以获得指定的订单及宝贝信息。
使用方法见代码或执行命令加参数-h,另外需要BeautifulSoup4支持,BeautifulSoup的官方项目列表页:https://www.crummy.com/software/BeautifulSoup/bs4/download/
首先来说一下代码使用方法:
python taobao.py -u USERNAME -p PASSWORD -s START-DATE -e END-DATE --verbose
所有参数均可选,如:
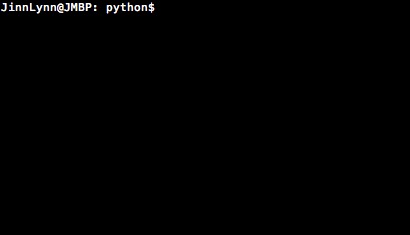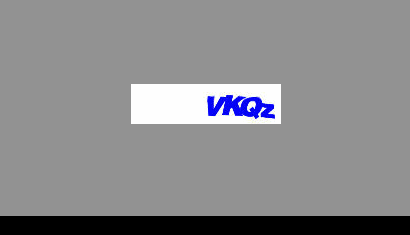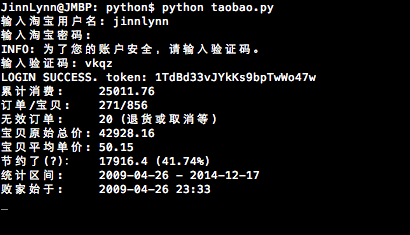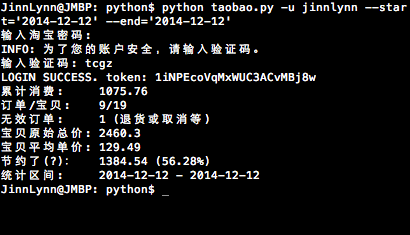
python taobao.py -u jinnlynn
统计用户jinnlynn所有订单的情况
python taobao.py -s 2014-12-12 -e 2014-12-12
统计用户(用户名在命令执行时会要求输入)在2014-12-12当天的订单情况
python taobao.py --verbose
这样就可以统计并输出订单明细。
好了,说了这么多我们就来看代码吧:
from __future__ import unicode_literals, print_function, absolute_import, division
import urllib
import urllib2
import urlparse
import cookielib
import re
import sys
import os
import json
import subprocess
import argparse
import platform
from getpass import getpass
from datetime import datetime
from pprint import pprint
try:
from bs4 import BeautifulSoup
except ImportError:
sys.exit('BeautifulSoup4 missing.')
__version__ = '1.0.0'
__author__ = 'JinnLynn'
__copyright__ = 'Copyright (c) 2014 JinnLynn'
__license__ = 'The MIT License'
HEADERS = {
'x-requestted-with' : 'XMLHttpRequest',
'Accept-Language' : 'zh-cn',
'Accept-Encoding' : 'gzip, deflate',
'ContentType' : 'application/x-www-form-urlencoded; chartset=UTF-8',
'Cache-Control' : 'no-cache',
'User-Agent' :'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/40.0.2214.38 Safari/537.36',
'Connection' : 'Keep-Alive'
}
DEFAULT_POST_DATA = {
'TPL_username' : '', #用户名
'TPL_password' : '', #密码
'TPL_checkcode' : '',
'need_check_code' : 'false',
'callback' : '0', # 有值返回JSON
}
# 无效订单状态
INVALID_ORDER_STATES = [
'CREATE_CLOSED_OF_TAOBAO', # 取消
'TRADE_CLOSED', # 订单关闭
]
LOGIN_URL = 'https://login.taobao.com/member/login.jhtml'
RAW_IMPUT_ENCODING = 'gbk' if platform.system() == 'Windows' else 'utf-8'
def _request(url, data, method='POST'):
if data:
data = urllib.urlencode(data)
if method == 'GET':
if data:
url = '{}?{}'.format(url, data)
data = None
# print(url)
# print(data)
req = urllib2.Request(url, data, HEADERS)
return urllib2.urlopen(req)
def stdout_cr(msg=''):
sys.stdout.write('\r{:10}'.format(' '))
sys.stdout.write('\r{}'.format(msg))
sys.stdout.flush()
def get(url, data=None):
return _request(url, data, method='GET')
def post(url, data=None):
return _request(url, data, method='POST')
def login_post(data):
login_data = DEFAULT_POST_DATA
login_data.update(data)
res = post(LOGIN_URL, login_data)
return json.load(res, encoding='gbk')
def login(usr, pwd):
data = {
'TPL_username' : usr.encode('utf-8' if platform.system() == 'Windows' else 'GB18030'),
'TPL_password' : pwd
}
# 1. 尝试登录
ret = login_post(data)
while not ret.get('state', False):
code = ret.get('data', {}).get('code', 0)
if code == 3425 or code == 1000:
print('INFO: {}'.format(ret.get('message')))
check_code = checkcode(ret.get('data', {}).get('ccurl'))
data.update({'TPL_checkcode' : check_code, 'need_check_code' : 'true'})
ret = login_post(data)
else:
sys.exit('ERROR. code: {}, message:{}'.format(code, ret.get('message', '')))
token = ret.get('data', {}).get('token')
print('LOGIN SUCCESS. token: {}'.format(token))
# 2. 重定向
# 2.1 st值
res = get('https://passport.alipay.com/mini_apply_st.js', {
'site' : '0',
'token' : token,
'callback' : 'stCallback4'})
content = res.read()
st = re.search(r'"st":"(\S*)"( |})', content).group(1)
# 2.1 重定向
get('http://login.taobao.com/member/vst.htm',
{'st' : st, 'TPL_uesrname' : usr.encode('GB18030')})
def checkcode(url):
filename, _ = urllib.urlretrieve(url)
if not filename.endswith('.jpg'):
old_fn = filename
filename = '{}.jpg'.format(filename)
os.rename(old_fn, filename)
if platform.system() == 'Darwin':
# mac 下直接preview打开
subprocess.call(['open', filename])
elif platform.system() == 'Windows':
# windows 执行文件用默认程序打开
subprocess.call(filename, shell=True)
else:
# 其它系统 输出文件名
print('打开该文件获取验证码: {}'.format(filename))
return raw_input('输入验证码: '.encode(RAW_IMPUT_ENCODING))
def parse_bought_list(start_date=None, end_date=None):
url = 'http://buyer.trade.taobao.com/trade/itemlist/list_bought_items.htm'
# 运费险 增值服务 分段支付(定金,尾款)
extra_service = ['freight-info', 'service-info', 'stage-item']
stdout_cr('working... {:.0%}'.format(0))
# 1. 解析第一页
res = urllib2.urlopen(url)
soup = BeautifulSoup(res.read().decode('gbk'))
# 2. 获取页数相关
page_jump = soup.find('span', id='J_JumpTo')
jump_url = page_jump.attrs['data-url']
url_parts = urlparse.urlparse(jump_url)
query_data = dict(urlparse.parse_qsl(url_parts.query))
total_pages = int(query_data['tPage'])
# 解析
orders = []
cur_page = 1
out_date = False
errors = []
while True:
bought_items = soup.find_all('tbody', attrs={'data-orderid' : True})
# pprint(len(bought_items))
count = 0
for item in bought_items:
count += 1
# pprint('{}.{}'.format(cur_page, count))
try:
info = {}
# 订单在页面上的位置 页数.排序号
info['pos'] = '{}.{}'.format(cur_page, count)
info['orderid'] = item.attrs['data-orderid']
info['status'] = item.attrs['data-status']
# 店铺
node = item.select('tr.order-hd a.shopname')
if not node:
# 店铺不存在,可能是赠送彩票订单,忽略
# print('ignore')
continue
info['shop_name'] = node[0].attrs['title'].strip()
info['shop_url'] = node[0].attrs['href']
# 日期
node = item.select('tr.order-hd span.dealtime')[0]
info['date'] = datetime.strptime(node.attrs['title'], '%Y-%m-%d %H:%M')
if end_date and info['date'].toordinal() > end_date.toordinal():
continue
if start_date and info['date'].toordinal() < start_date.toordinal():
out_date = True
break
# 宝贝
baobei = []
node = item.find_all('tr', class_='order-bd')
# pprint(len(node))
for n in node:
try:
bb = {}
if [True for ex in extra_service if ex in n.attrs['class']]:
# 额外服务处理
# print('额外服务处理')
name_node = n.find('td', class_='baobei')
# 宝贝地址
bb['name'] = name_node.text.strip()
bb['url'] = ''
bb['spec'] = ''
# 宝贝快照
bb['snapshot'] = ''
# 宝贝价格
bb['price'] = 0.0
# 宝贝数量
bb['quantity'] = 1
bb['is_goods'] = False
try:
bb['url'] = name_node.find('a').attrs['href']
bb['price'] = float(n.find('td', class_='price').text)
except:
pass
else:
name_node = n.select('p.baobei-name a')
# 宝贝地址
bb['name'] = name_node[0].text.strip()
bb['url'] = name_node[0].attrs['href']
# 宝贝快照
bb['snapshot'] = ''
if len(name_node) > 1:
bb['snapshot'] = name_node[1].attrs['href']
# 宝贝规格
bb['spec'] = n.select('.spec')[0].text.strip()
# 宝贝价格
bb['price'] = float(n.find('td', class_='price').attrs['title'])
# 宝贝数量
bb['quantity'] = int(n.find('td', class_='quantity').attrs['title'])
bb['is_goods'] = True
baobei.append(bb)
# 尝试获取实付款
# 实付款所在的节点可能跨越多个tr的td
amount_node = n.select('td.amount em.real-price')
if amount_node:
info['amount'] = float(amount_node[0].text)
except Exception as e:
errors.append({
'type' : 'baobei',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(n),
'error' : '{}'.format(e)
})
except Exception as e:
errors.append({
'type' : 'order',
'id' : '{}.{}'.format(cur_page, count),
'node' : '{}'.format(item),
'error' : '{}'.format(e)
})
info['baobei'] = baobei
orders.append(info)
stdout_cr('working... {:.0%}'.format(cur_page / total_pages))
# 下一页
cur_page += 1
if cur_page > total_pages or out_date:
break
query_data.update({'pageNum' : cur_page})
page_url = '{}?{}'.format(url, urllib.urlencode(query_data))
res = urllib2.urlopen(page_url)
soup = BeautifulSoup(res.read().decode('gbk'))
stdout_cr()
if errors:
print('INFO. 有错误发生,统计结果可能不准确。')
# pprint(errors)
return orders
def output(orders, start_date, end_date):
amount = 0.0
org_amount = 0
baobei_count = 0
order_count = 0
invaild_order_count = 0
for order in orders:
if order['status'] in INVALID_ORDER_STATES:
invaild_order_count += 1
continue
amount += order['amount']
order_count += 1
for baobei in order.get('baobei', []):
if not baobei['is_goods']:
continue
org_amount += baobei['price'] * baobei['quantity']
baobei_count += baobei['quantity']
print('{:<9} {}'.format('累计消费:', amount))
print('{:<9} {}/{}'.format('订单/宝贝:', order_count, baobei_count))
if invaild_order_count:
print('{:<9} {} (退货或取消等, 不在上述订单之内)'.format('无效订单:', invaild_order_count))
print('{:<7} {}'.format('宝贝原始总价:', org_amount))
print('{:<7} {:.2f}'.format('宝贝平均单价:', 0 if baobei_count == 0 else org_amount / baobei_count))
print('{:<9} {} ({:.2%})'.format('节约了(?):',
org_amount - amount,
0 if org_amount == 0 else (org_amount - amount) / org_amount))
from_date = start_date if start_date else orders[-1]['date']
to_date = end_date if end_date else datetime.now()
print('{:<9} {:%Y-%m-%d} - {:%Y-%m-%d}'.format('统计区间:', from_date, to_date))
if not start_date:
print('{:<9} {:%Y-%m-%d %H:%M}'.format('败家始于:', orders[-1]['date']))
def ouput_orders(orders):
print('所有订单:')
if not orders:
print(' --')
return
for order in orders:
print(' {:-^20}'.format('-'))
print(' * 订单号: {orderid} 实付款: {amount} 店铺: {shop_name} 时间: {date:%Y-%m-%d %H:%M}'.format(**order))
for bb in order['baobei']:
if not bb['is_goods']:
continue
print(' - {name}'.format(**bb))
if bb['spec']:
print(' {spec}'.format(**bb))
print(' {price} X {quantity}'.format(**bb))
def main():
parser = argparse.ArgumentParser(
prog='python {}'.format(__file__)
)
parser.add_argument('-u', '--username', help='淘宝用户名')
parser.add_argument('-p', '--password', help='淘宝密码')
parser.add_argument('-s', '--start', help='起始时间,可选, 格式如: 2014-11-11')
parser.add_argument('-e', '--end', help='结束时间,可选, 格式如: 2014-11-11')
parser.add_argument('--verbose', action='store_true', default=False, help='订单详细输出')
parser.add_argument('-v', '--version', action='version',
version='v{}'.format(__version__), help='版本号')
args = parser.parse_args()
usr = args.username
if not usr:
usr = raw_input('输入淘宝用户名: '.encode(RAW_IMPUT_ENCODING))
usr = usr.decode('utf-8') # 中文输入问题
pwd = args.password
if not pwd:
if platform.system() == 'Windows':
# Windows下中文输出有问题
pwd = getpass()
else:
pwd = getpass('输入淘宝密码: '.encode('utf-8'))
pwd = pwd.decode('utf-8')
verbose = args.verbose
start_date = None
if args.start:
try:
start_date = datetime.strptime(args.start, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
end_date = None
if args.end:
try:
end_date = datetime.strptime(args.end, '%Y-%m-%d')
except Exception as e:
sys.exit('ERROR. {}'.format(e))
if start_date and end_date and start_date > end_date:
sys.exit('ERROR, 结束日期必须晚于或等于开始日期')
cj_file = './{}.tmp'.format(usr)
cj = cookielib.LWPCookieJar()
try:
cj.load(cj_file)
except:
pass
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj), urllib2.HTTPHandler)
urllib2.install_opener(opener)
login(usr, pwd)
try:
cj.save(cj_file)
except:
pass
orders = parse_bought_list(start_date, end_date)
output(orders, start_date, end_date)
# 输出订单明细
if verbose:
ouput_orders(orders)
if __name__ == '__main__':
main()

相关文章推荐
• 【活动】充值PHP中文网VIP即送云服务器• 深入了解python中的代码缩进规则• Python随机森林模型实例详解• 一文掌握Python返回函数、闭包、装饰器、偏函数• Python可视化总结之matplotlib.pyplot基本参数详解• python能代替JavaScript吗
独孤九贱(3)_JavaScript视频教程
javascript是运行在浏览器上的脚本语言,连续多年,被评为全球最受欢迎的编程语言。是前端开发必备三大法器中,最具杀伤力。如果前端开发是降龙十八掌,好么javascript就是第18掌:亢龙有悔。没有它,你的前端生涯是不完整的。《php.cn独孤九贱(3)-JavaScript视频教程》课程特色:php中文网原创幽默段子系列课程,以恶搞,段子为主题风格的php视频教程!轻松的教学风格,简短的教学模式,让同学们在不知不觉中,学会了javascript知识。
JavaScript教程128032次播放

独孤九贱(6)_jQuery视频教程
jQuery是一个快速、简洁的JavaScript框架。设计的宗旨是“write Less,Do More”,即倡导写更少的代码,做更多的事情。它封装JavaScript常用的功能代码,提供一种简便的JavaScript设计模式,优化HTML文档操作、事件处理、动画设计和Ajax交互。 核心特性可以总结为:具有独特的链式语法和短小清晰的多功能接口;具有高效灵活的css选择器,并且可对CSS选择器进行扩展;拥有便捷的插件扩展机制和丰富的插件。兼容各种主流浏览器,如IE 6.0+、FF 1.5+、Safari 2.0+、Opera 9.0+等,是全球最流行的前端开发框架之一。PHP中文网根据最新版本,独家录制jQuery最新视频教程,回馈PHP中文网的新老用户。
jQuery教程105826次播放

jQuery与Ajax基础与实战
jQuery是最流行的JS函数库,封装了许多实用的功能,其中最引人入胜的就是Ajax。 jQuery中的Ajax操作,语法简单,操作方便,使Ajax从未如此轻松,前端人员从此不再为与服务器异步交互而发愁,本套课程,精选了最常用的几个方法,从基本的语法到每个参数,再到具体实例进行了全面的讲解。
AJAX教程6552次播放

Git教程(60分钟全程无废话版)
Git 是一个开源的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目。 Git 是 Linus Torvalds 为了帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。 Git 与常用的版本控制工具 CVS, Subversion 等不同,它采用了分布式版本库的方式,不必服务器端软件支持
JavaScript教程5665次播放













