

处理的是一个.js文件,中间包含大量insert命令和update命令。一个命令占一行。
文件大小为222M.
错误信息如下: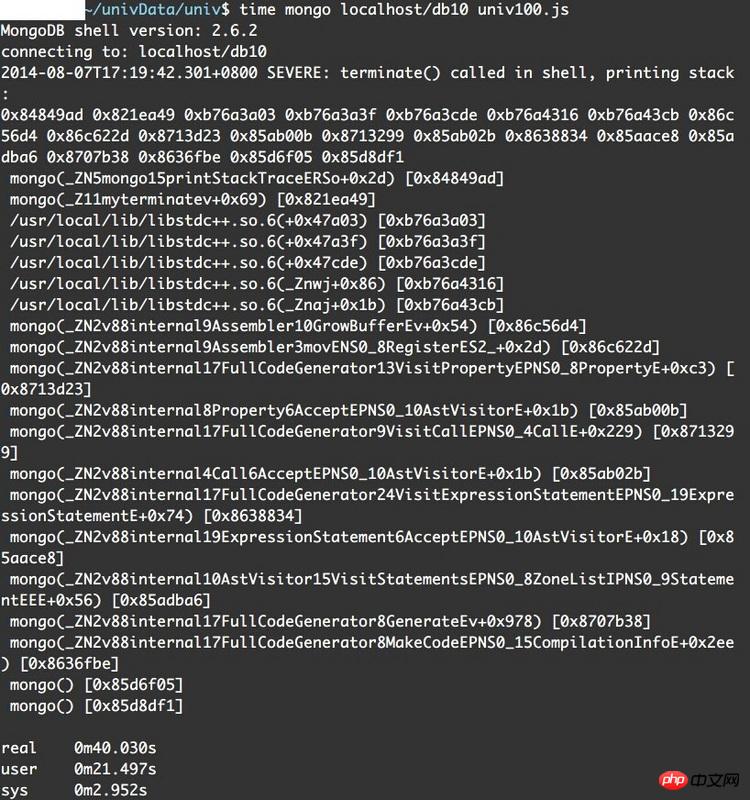
我猜测可能是因为单条命令太长的缘故,但是用mongo直接处理.js文件按理说不会有这样的问题才对吧
系统是debian 32位,版本2.6.32-5-386
在stackoverflow和segmentfault找,也只看到有人遇到堆栈信息中是_ZN5开头的。
在64位mongodb上运行成功了。
但是64位加载2.3G文件的时候又有错误,好在这次有明确信息了。
拆成200多M的文件就能处理了。
很奇怪,我在mongodb文档中没看到说有这种限制啊
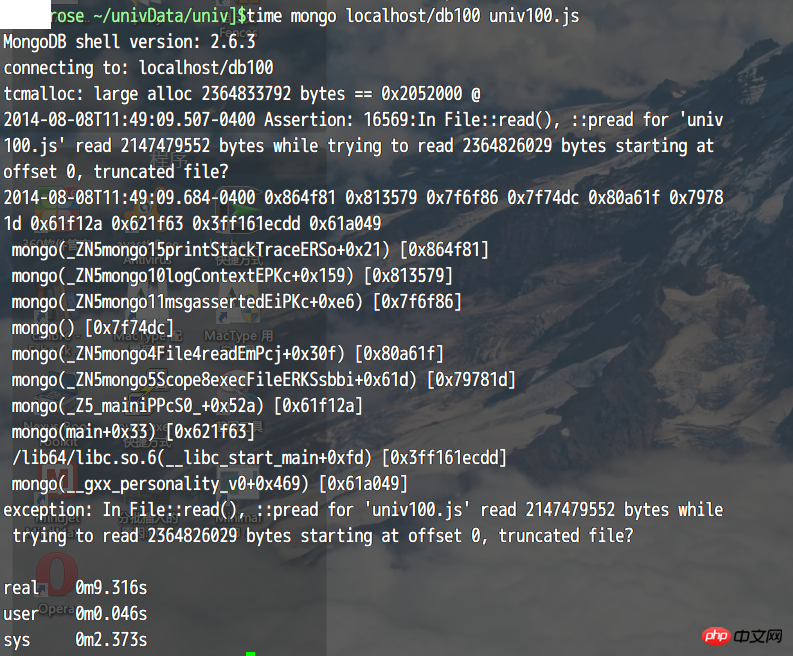
connecting to: localhost/test
tcmalloc: large alloc 2364833792 bytes == 0x2658000 @
2014-08-19T21:49:28.069-0400 Assertion: 16569:In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
2014-08-19T21:49:28.164-0400 0x864f81 0x813579 0x7f6f86 0x7f74dc 0x80a61f 0x79781d 0x61f12a 0x621f63 0x3ff161ecdd 0x61a049
mongo(_ZN5mongo15printStackTraceERSo+0x21) [0x864f81]
mongo(_ZN5mongo10logContextEPKc+0x159) [0x813579]
mongo(_ZN5mongo11msgassertedEiPKc+0xe6) [0x7f6f86]
mongo() [0x7f74dc]
mongo(_ZN5mongo4File4readEmPcj+0x30f) [0x80a61f]
mongo(_ZN5mongo5Scope8execFileERKSsbbi+0x61d) [0x79781d]
mongo(_Z5_mainiPPcS0_+0x52a) [0x61f12a]
mongo(main+0x33) [0x621f63]
/lib64/libc.so.6(__libc_start_main+0xfd) [0x3ff161ecdd]
mongo(__gxx_personality_v0+0x469) [0x61a049]
exception: In File::read(), ::pread for 'univ100-100.js' read 2147479552 bytes while trying to read 2364826029 bytes starting at offset 0, truncated file?
real 0m7.922s
user 0m0.045s
sys 0m2.477s




























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




신고해 주셔서 진심으로 감사드립니다.
우선 스택 추적은 gcc에 의해 mangleed되고 demangler를 사용하여 역으로 볼 수 있습니다.
서버가 셸과 마찬가지로 2.6.3이라고 가정하면 셸은 전체 스크립트 파일을 메모리로 읽어온 다음 32의 2.3G 파일에 문제가 있다고 설명할 수 있습니다. - 비트 머신. 하지만 64비트 컴퓨터에서는 문제가 발생하지 않습니다.
두 가지 질문이 있습니다.
1. 32비트 운영 체제와 호환되도록 JS 파일 크기는 2G로 제한되어야 합니다. 현재 로직은 맞지만 상한값이 너무 커서 설명과 일치하지 않습니다.
2. 파일을 읽을 때 시스템은 항상 한 번의
pread호출로 읽힌다고 보장할 수 없으므로 파일이 끝나거나 오류가 발생할 때까지 file.cpp에서 여러 번 읽는 것이 가장 좋습니다.문제가 명확해졌기를 바랍니다. 임시 해결책은 이전에 했던 작업을 수행하고 파일을 더 작은 조각으로 나누는 것입니다. 발생한 문제를 영어로 간단히 설명하면서 이 문제를 Jira에 제출할 수 있다면 좋을 것입니다. 커널 엔지니어는 향후 개발에서 이를 개선할 예정이며 Jira에서 이 문제를 추적할 수도 있습니다. 불편하시다면 제가 대신 제출해 드리겠습니다.
더 좋은 방법은 Jira에 보고서를 제출한 후 Github에서 MongoDB 코드를 포크하고 수정한 다음 끌어오기 요청을 제출하는 것입니다. 커널 엔지니어가 코드를 검토하고 최종적으로 코드 베이스에 병합합니다. 이 문제는 상대적으로 드물고, 상대적으로 독립적이며, 상대적으로 명확하기 때문에 작은 작업을 완료한 후 Pull Request를 제출하는 것이 매우 적합합니다. 그러면 전 세계 MongoDB 사용자들이 당신이 작성한 코드를 실행하고 있습니다. 중국에는 MongoDB 사용자가 많기 때문에 MongoDB 커뮤니티에 기여할 수 있는 능력이 있다고 생각합니다. 더 궁금한 점이 있으면 알려주시기 바랍니다.
P.S. 2.3G 스크립트가 왜 필요한지 궁금합니다. 무엇을 하려는지 알려주시면 더 우아한 솔루션이 있을 수 있습니다.