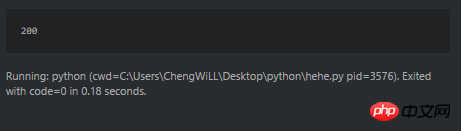
import urllib2 opener = urllib2.build_opener() html = None response = None response = opener.open('http://www.sxxrcs.com/was5/web/') html = response.code print html
比如这个爬虫,输出状态码是200。
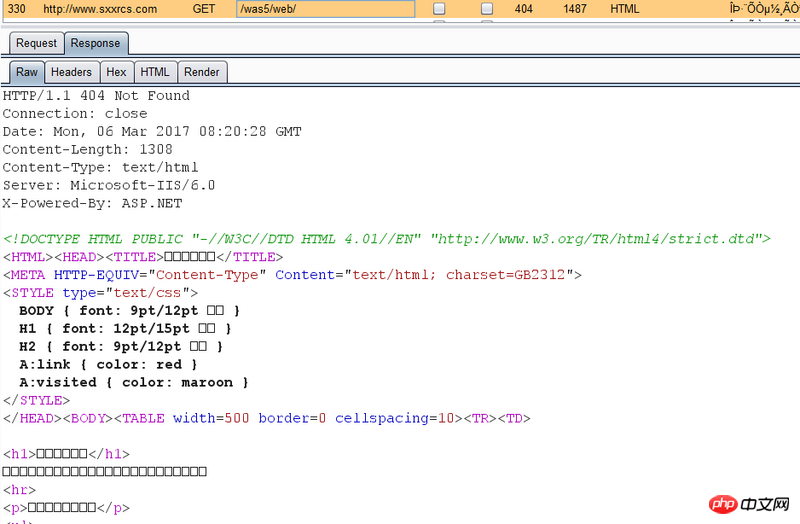
可是直接访问http://www.sxxrcs.com/was5/web/是404,抓包响应的也是404,请问这是为什么?
人生最曼妙的风景,竟是内心的淡定与从容!
요청 사용
200이 정상이고, 요청이 편리하고 빠릅니다.

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




요청 사용
으아악200이 정상이고, 요청이 편리하고 빠릅니다.