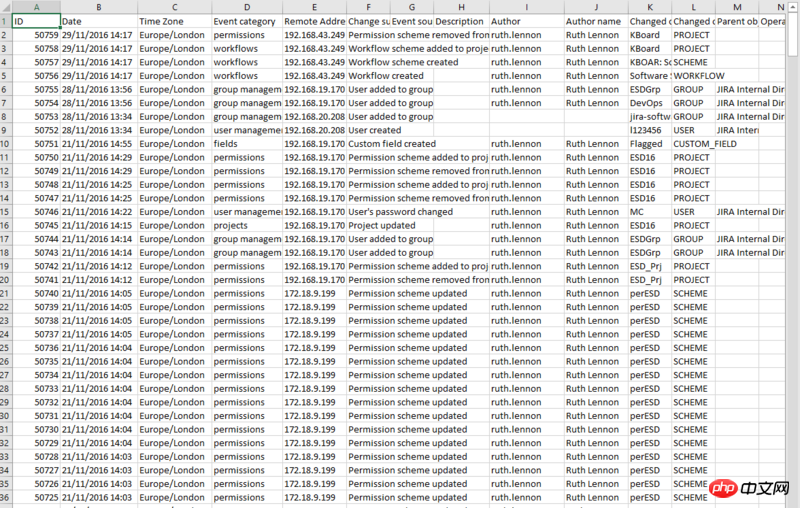
import csv,re with open('xxx.csv','rb') as rf: reader = csv.reader(rf) with open('xxx_new.csv','wb') as wf: writer = csv.writer(wf) headers = reader.next() writer.writerow(headers) for row in reader: t = re.split('\W+',row[1]) # row[1]为Date字段,被拆为['1', '11', '2016', '14', '17'] if int(t[1]) == 11: # 假设你想要11月数据 writer.writerow(row)





























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




使用re.split拆分Date字段
你说timeseries,是用pandas么?
如果是pandas,其实还是蛮简单的。假设datefrmae的名字是df
首先确保Date那列转换为DatetimeIndex,这个可以用df['newdate']=pd.DatetimeIndex(df['date'])完成
然后就是筛选了df[df['newdate'].dt.month==9]就能筛选出所有9月的数据了,