

结构数据是这样的:
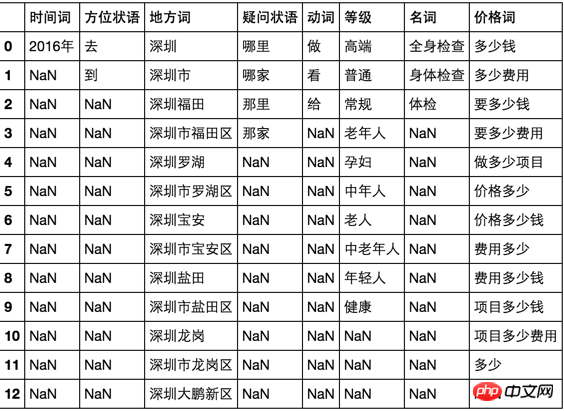
要求按照这样的公式:组合一: 时间词+地方词+动词+等级+名词+价格词;
比如
2016年深圳大鹏新区给健康全身检查要多少钱
就是按照这样的公式组合出来的关键词
那么有什么办法用最短的办法来实现,我下面是我的算法,用pandas的算法:
for times in df[df["时间词"].notnull()]["时间词"]: for area in df[df["地方词"].notnull()]["地方词"]: for dong in df[df["动词"].notnull()]["动词"]: for leave in df[df["等级"].notnull()]["等级"]: for name in df[df["名词"].notnull()]["名词"]: for price in df[df["价格词"].notnull()]["价格词"]: data = (times+area+dong+leave+name+price)但是这样的代码太不优雅,而且封装成函数太难~
我想要的效果是这样的:
比如:
我写一个公式
cols = ["时间词","地方词","动词","等级","名词","价格词"] #或则是 cols = ["地方词","动词","等级","名词","价格词"]然后把这个列表传入一个函数中,就可以得出我上面的效果~
这个要如何实现?
补充一下,如果看不懂提问的人可以这样理解这个题目
我有3个列表:
a = ["1","2","3","4","5"] b = ["a","b","c"] c = ["A","B"]我要这样的组合: a中的每个元素和b,c中的每个元素都进行组合
这个一个很简单的多重循环就可以解决:
for A in a: for B in b: for C in c: print (A+B+C)这当然很简单,但是假如我有10000个这样的列表要重组?
难不成要手工复制黏贴每个循环10000次?这显然不太现实
在python中有没有比较好的函数或是比较好的方法来实现这个东西?
Taku的解答.完全符合需求附上我修改后的代码
import itertools def zuhe(cols): b = pd.Series() for col in cols: b = b.append(pd.Series({col:list(df[df[col].notnull()][col])})) for x in itertools.product(*(b.values)): print (x) zuhe(cols = ["时间词","地方词","动词"])只需要传入需要组合的列表词,就可以得到结果!!



























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




itertools를 사용해 보세요
으아악ㅋㅋㅋ 사실 데카르트 곱을 구하는 게 문제입니다
키워드 정리와 검색 활용법을 배워야 합니다
바퀴 재발명을 수행하겠습니다:
반복을 사용한 버전:
으아악재귀 버전:
으아악테스트:
으아악결과:
으아악인생은 짧다, 똑같은 짓은 하지마세요...
내가 답변한 질문: Python-QA
全排列生成算法과 유사재귀 또는 재귀를 사용할 수 있습니다
재귀는 구현하기가 상대적으로 간단하지만, 재귀는 좀 더 번거롭습니다
목록 생성이 가능한가요?
으아악재귀를 작성하는 것은 실제로 가능하지만 dfs 깊이 우선 검색을 작성하는 방법을 모르십니까?