웹사이트: https://www.nvshens.com/g/22377/. 브라우저에서 직접 웹사이트를 연 후 이미지를 마우스 오른쪽 버튼으로 클릭하여 다운로드하세요. 그러면 내 크롤러에서 직접 요청한 이미지가 차단되었습니다. 그런 다음 헤더를 변경하고 IP 프록시를 설정했지만 여전히 작동하지 않았습니다. 하지만 패킷 캡처를 보면 동적으로 로드된 데이터가 아닙니다! ! ! 답변해주세요 ==
ringa_lee
여자가 꽤 예쁘네요. 실제로 마우스 오른쪽 버튼을 클릭하면 열 수 있지만 새로고침하면 핫링크된 사진이 됩니다. 일반적으로 핫링크를 방지하기 위해 서버는 요청 헤더의 Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Referer가 변경되었는지 확인합니다.
Referer
사진을 얻을 때 패킷을 캡처하여 매개 변수를 놓쳤습니까?
저는 웹사이트의 내용을 보고 있었는데 공식 내용이라는 사실을 거의 잊어버릴 뻔했습니다. 요청하신 모든 정보를 팔로우하실 수 있습니다
그럼 한번 해보세요
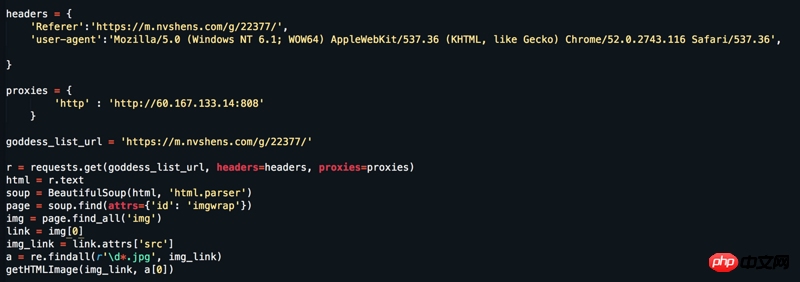
Referer 이 웹사이트의 디자인에 따르면 각 페이지는 단일 Referer를 사용하는 대신 인간인 척하는 행동에 더 부합해야 합니다.다음은 모든 사진을 캡처하기 위해 실행할 수 있는 완전한 코드입니다. 18페이지

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




여자가 꽤 예쁘네요.

으아악실제로 마우스 오른쪽 버튼을 클릭하면 열 수 있지만 새로고침하면 핫링크된 사진이 됩니다. 일반적으로 핫링크를 방지하기 위해 서버는 요청 헤더의
Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Referer가 변경되었는지 확인합니다.사진을 얻을 때 패킷을 캡처하여 매개 변수를 놓쳤습니까?
저는 웹사이트의 내용을 보고 있었는데 공식 내용이라는 사실을 거의 잊어버릴 뻔했습니다.
요청하신 모든 정보를 팔로우하실 수 있습니다
그럼 한번 해보세요
Referer 이 웹사이트의 디자인에 따르면 각 페이지는 단일 Referer를 사용하는 대신 인간인 척하는 행동에 더 부합해야 합니다.
으아악다음은 모든 사진을 캡처하기 위해 실행할 수 있는 완전한 코드입니다. 18페이지