

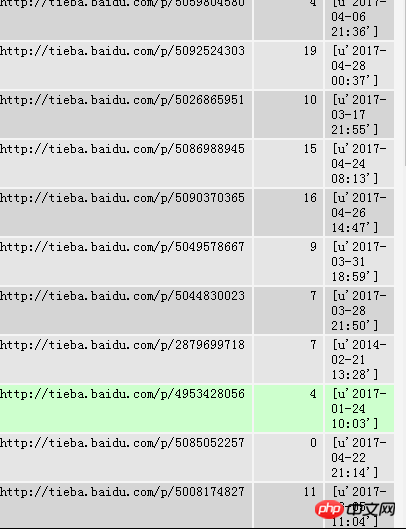
Python scrapy는 Baidu Tieba를 수집하여 mysql에 저장합니다. 저장데이터가 엉망이네요. 바이두티에바 게시시간에 맞춰서 저장하는 방법이 있나요?
사진:
 < /p>
< /p>
다음 열은 회차입니다. 제가 모은 메시지를 바이두 티에바의 포스터에 올렸던 때입니다. 창고에 들어가 보니 이번에는 매우 혼란 스러웠습니다. 오늘과 어제가 있습니다. 전달. . . .
Baidu Tieba 게시물의 시간순을 데이터베이스에 저장하려는 경우.
이를 달성하려면 어떤 아이디어가 필요합니까?















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




방법이 없을까요? 캡처된 정렬되지 않은 데이터를 모두 캐시하고 정렬한 다음 데이터베이스에 기록하지 않는 한, 데이터베이스에는 이미 데이터를 검색하는 기능이 있습니다. 포스터는 왜 기록 순서에 집착합니까?
order by시간 값을 문자열에서 시간 값으로 변환하고 정렬합니다