

강의 중급 11331
코스소개:"IT 네트워크 리눅스 로드밸런싱 자습 영상 튜토리얼"은 nagin 하에서 web, lvs, Linux에서 스크립트 연산을 수행하여 Linux 로드밸런싱을 주로 구현합니다.

강의 고급의 17634
코스소개:"Shangxuetang MySQL 비디오 튜토리얼"은 MySQL 데이터베이스 설치부터 사용까지의 과정을 소개하고, 각 링크의 구체적인 작동 방법을 자세히 소개합니다.

강의 고급의 11347
코스소개:"Band of Brothers 프런트엔드 예제 디스플레이 비디오 튜토리얼"은 HTML5 및 CSS3 기술의 예를 모든 사람에게 소개하여 모든 사람이 HTML5 및 CSS3 사용에 더욱 능숙해질 수 있도록 합니다.
문제 2003(HY000) 해결 방법: MySQL 서버 'db_mysql:3306'에 연결할 수 없습니다(111).
2023-09-05 11:18:47 0 1 825
2023-09-05 14:46:42 0 1 725
CSS 그리드: 하위 콘텐츠가 열 너비를 초과할 때 새 행 생성
2023-09-05 15:18:28 0 1 615
AND, OR 및 NOT 연산자를 사용한 PHP 전체 텍스트 검색 기능
2023-09-05 15:06:32 0 1 577
2023-09-05 15:34:44 0 1 1004

코스소개:확장 가능한 지도: 온라인 장거리 벡터화 HD 지도 구축을 위한 확장 가능한 지도 학습 논문을 읽으려면 다음 링크를 클릭하십시오: https://arxiv.org/pdf/2310.13378.pdf 코드 링크: https://github.com/jingy1yu /ScalableMap 저자는 우한대학교 출신입니다. 논문 아이디어: 이 논문은 차량 장착 카메라 센서를 사용하여 온라인 장거리 벡터화된 고정밀(HD) 지도를 구축하기 위한 새로운 엔드투엔드 프로세스를 제안합니다. 고정밀 지도의 벡터화된 표현은 폴리라인과 폴리곤을 사용하여 다운스트림 작업에서 널리 사용되는 지도 기능을 나타냅니다. 그러나 동적 표적 탐지를 참조하여 설계된 이전 솔루션은 선형 맵을 무시했습니다.
2023-10-31 논평 0 1246
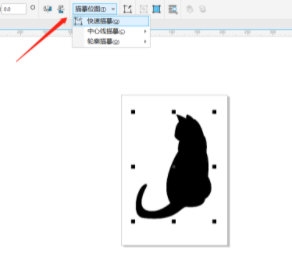
코스소개:CorelDRAW는 사용자가 다양하고 창의적인 그림과 텍스트를 디자인하는 데 도움이 되는 매우 사용하기 쉬운 그림 디자인 소프트웨어입니다. 오늘은 실루엣 텍스트를 만드는 방법을 살펴보겠습니다. 이러한 텍스트 효과는 대부분 작은 동물이나 식물의 실루엣으로 만들어지기 때문에 이런 종류의 벡터 자료를 준비해야 합니다. 구체적인 작업은 다음과 같습니다. 1. CorelDRAW 소프트웨어를 열고 벡터 자료를 대체합니다. 벡터 이미지가 아닌 경우 [Tracing Bitmap]을 클릭하여 변환합니다. 2. [Pen Tool]을 사용하여 원하는 부분에 동그라미를 칩니다. 3. 실루엣 재질과 그려진 곡선을 선택하고 교차를 클릭한 후 꼬리를 추출하고 단순화를 클릭하여 원본 재질에서 꼬리를 제거합니다.
2024-02-09 논평 0 1252

코스소개:이전에 작성됨: 저자의 개인적인 이해는 센서 데이터를 기반으로 벡터화된 고정밀 지도를 실시간으로 구성하는 것이 예측 및 계획과 같은 후속 작업에 중요하며 오프라인 고정밀의 열악한 실시간 성능을 효과적으로 보완할 수 있다는 것입니다. 지도. 딥러닝의 발전과 함께 온라인으로 벡터화된 고정밀 지도 구축이 점차 등장하고 있으며, HDMapNet, MapTR 등의 대표작들이 속속 등장하고 있습니다. 그러나 기존의 온라인 벡터화된 고정밀 지도 구성 방법에는 지도 요소의 기하학적 특성(요소의 모양, 수직, 평행 및 기타 기하학적 관계 포함)에 대한 탐색이 부족합니다. 벡터화된 고정밀 지도의 기하학적 특성 벡터화된 고정밀 지도는 도로의 요소를 고도로 추상화하고 각 지도 요소를 2차원 점 시퀀스로 나타냅니다. 도시 도로의 설계에는 보행자와 같은 특정 사양이 있습니다.
2023-12-15 논평 0 590

코스소개:IT하우스는 지난 주말 어도비 포토샵 베타 버전이 '제너러티브필(GenerativeFill)'이라는 AI 이미지 합성 툴을 출시했다고 1일 보도했다. 이 기능은 출시 이후 많은 네티즌들 사이에서 인기를 끌었다. 매우 창의적인 작품이 많이 생산되었습니다. "GenerativeFill" 기능은 "Adobe Firefly" 이미지 합성 모델을 사용합니다. 이 모델은 수백만 개의 Adobe 재질 이미지로부터 학습하여 주어진 이미지를 기반으로 합리적인 확장을 생성합니다. 사용자는 AI가 특정 장면을 생성하도록 안내하는 텍스트 프롬프트를 입력하여 더욱 환상적인 결과를 얻을 수도 있습니다. 예를 들어 일부 네티즌은 이 도구를 사용하여 Mike의
2023-06-04 논평 0 1114

코스소개:VisionTransformer(VIT)는 Google에서 제안하는 Transformer 기반의 이미지 분류 모델입니다. 기존 CNN 모델과 달리 VIT는 이미지를 시퀀스로 표현하고 이미지의 클래스 레이블을 예측하여 이미지 구조를 학습합니다. 이를 달성하기 위해 VIT는 입력 이미지를 여러 패치로 나누고 채널을 통해 각 패치의 픽셀을 연결한 다음 선형 투영을 수행하여 원하는 입력 크기를 얻습니다. 마지막으로 각 패치는 단일 벡터로 평면화되어 입력 시퀀스를 형성합니다. Transformer의 self-attention 메커니즘을 통해 VIT는 서로 다른 패치 간의 관계를 캡처하고 효과적인 특징 추출 및 분류 예측을 수행할 수 있습니다. 이 직렬화된 이미지 표현은
2024-01-23 논평 0 1395
