
이 사이트는 학술 및 기술 콘텐츠를 담은 칼럼을 게시합니다. 최근 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
비디오 이해의 새로운 영역을 탐험해보세요. Mamba 모델은 컴퓨터 비전 연구의 새로운 트렌드를 선도합니다! 전통적인 아키텍처의 한계가 깨졌습니다. 상태 공간 모델 Mamba는 긴 시퀀스 처리에서 고유한 이점을 통해 비디오 이해 분야에 혁신적인 변화를 가져왔습니다. 난징대학교, 상하이 인공지능연구소, 푸단대학교, 저장대학교 연구팀이 획기적인 연구 결과를 발표했습니다. 그들은 비디오 모델링에서 Mamba의 다양한 역할을 종합적으로 살펴보고, 14가지 모델/모듈을 위한 Video Mamba 제품군을 제안하고, 12가지 비디오 이해 작업에 대한 심층 평가를 수행합니다. 결과는 매우 흥미로웠습니다. Mamba는 비디오 관련 작업과 비디오 언어 작업 모두에서 강력한 잠재력을 보여 효율성과 성능의 이상적인 균형을 달성했습니다. 이는 기술적 도약일 뿐만 아니라 향후 영상이해 연구에 대한 강력한 추진력이기도 하다. 
- 논문 제목: Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
- 논문 링크: https://arxiv.org/abs/2403.09626
- 코드 링크: https ://github.com/OpenGVLab/video-mamba-suite
오늘날 빠르게 발전하는 컴퓨터 비전 분야에서 비디오 이해 기술은 산업 발전의 핵심 원동력 중 하나가 되었습니다. 많은 연구자들은 비디오 콘텐츠에 대한 심층적인 분석을 달성하기 위해 다양한 딥 러닝 아키텍처를 탐색하고 최적화하는 데 전념하고 있습니다. 초기 순환 신경망(RNN)과 3차원 컨벌루션 신경망(3D CNN)부터 현재 큰 기대를 받고 있는 Transformer 모델에 이르기까지 각각의 기술적 도약은 비디오 데이터에 대한 우리의 이해와 적용 범위를 크게 넓혔습니다. 특히 Transformer 모델은 타겟 탐지, 이미지 분할, 멀티모달 질문 응답을 포함하되 이에 국한되지 않는 탁월한 성능으로 비디오 이해의 여러 분야에서 놀라운 성과를 거두었습니다. 그러나 비디오 데이터의 고유한 매우 긴 시퀀스 특성에 직면하여 Transformer 모델은 고유한 한계도 노출합니다. 즉, 계산 복잡성의 2차 증가로 인해 매우 긴 비디오 시퀀스를 직접 모델링하는 것이 매우 어려워집니다. 이러한 맥락에서 Mamba로 대표되는 상태 공간 모델 아키텍처는 선형 계산 복잡성의 장점을 통해 Transformer의 기초가 되는 긴 시퀀스 데이터를 처리할 수 있는 강력한 잠재력을 보여줍니다. 모델은 대체 가능성을 제공합니다. 그럼에도 불구하고, 비디오 이해 분야에서 상태 공간 모델 아키텍처의 현재 적용에는 여전히 몇 가지 제한 사항이 있습니다. 첫째, 주로 분류 및 검색과 같은 전역 비디오 이해 작업에 중점을 두고, 둘째, 직접적인 시공간 모델링 방법을 주로 탐구합니다. 그러나 보다 다양한 모델링 방법에 대한 탐구는 아직 미흡한 실정이다. 이러한 한계를 극복하고 영상 이해 분야에서 Mamba 모델의 잠재력을 종합적으로 평가하기 위해 연구팀은 video-mamba-suite(Video Mamba Suite)를 신중하게 구축했습니다. 이 제품군은 일련의 심층적인 실험과 분석을 통해 비디오 이해에 있어 Mamba의 다양한 역할과 잠재적인 이점을 탐구하고 기존 연구를 보완하는 것을 목표로 합니다. 연구팀은 Mamba 모델의 적용을 4가지 역할로 나누어 이에 따라 14개의 모델/모듈을 포함하는 비디오 Mamba 제품군을 구축했습니다. 12가지 비디오 이해 작업에 대한 종합적인 평가를 거친 실험 결과는 비디오 및 비디오 언어 작업 처리에서 Mamba의 엄청난 잠재력을 보여줄 뿐만 아니라 효율성과 성능 간의 탁월한 균형을 보여줍니다. 저자는 이 작업이 비디오 이해 분야의 향후 연구를 위한 참고 자료와 통찰력을 제공하기를 기대합니다. 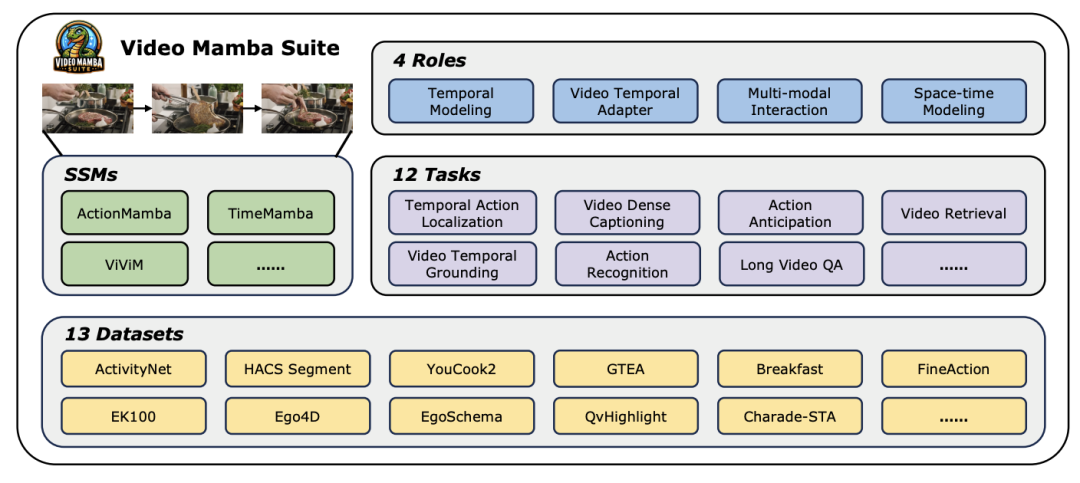
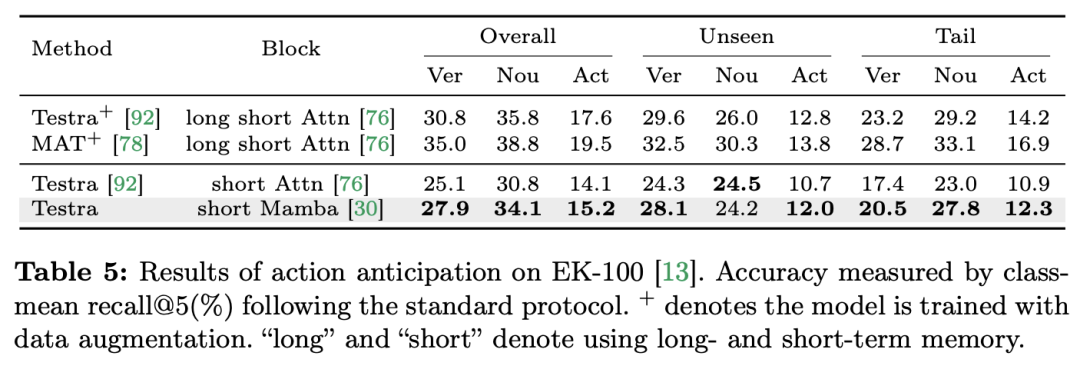
비디오 이해는 컴퓨터 비전 연구의 기본 문제이며, 그 핵심은 비디오의 시공간 역학을 포착하고 이를 사용하여 활동의 성격과 진화를 식별하고 추론하는 것입니다. 프로세스. 현재 영상이해를 위한 건축물 탐색은 크게 세 가지 방향으로 나누어진다. 첫 번째, 프레임 기반 특징 인코딩 방법은 순환 네트워크(예: GRU 및 LSTM)를 통해 시간 종속성을 모델링하지만, 이 분할된 시공간 모델링 방법은 결합된 시공간 정보를 캡처하기 어렵습니다. 둘째, 3차원 컨볼루션 커널을 사용하면 컨볼루션 신경망의 공간적 상관관계와 시간적 상관관계를 동시에 고려할 수 있습니다. 언어 및 이미지 분야에서 Transformer 모델의 큰 성공과 함께 비디오 Transformer 모델은 비디오 이해 분야에서도 상당한 발전을 이루며 RNN 및 3D-CNN 이상의 기능을 입증했습니다. Video Transformer는 비디오를 일련의 토큰으로 캡슐화하고 어텐션 메커니즘을 사용하여 전역 컨텍스트 상호 작용 및 데이터 종속 동적 계산을 구현함으로써 비디오의 시간 또는 시공간 정보를 통합된 방식으로 처리합니다. 그러나 긴 비디오를 처리할 때 Video Transformer의 제한된 계산 효율성으로 인해 속도와 성능 간의 균형을 유지하는 일부 변형 모델이 등장했습니다. 최근에는 자연어 처리(NLP) 분야에서 상태 공간 모델(SSM)이 장점을 보여주었습니다. 최신 SSM은 선형 시간 복잡성을 유지하면서 긴 시퀀스를 모델링하는 강력한 표현 기능을 보여줍니다. 이는 선택 메커니즘으로 인해 전체 컨텍스트를 저장할 필요가 없기 때문입니다. 특히 Mamba 모델은 시변 매개변수를 SSM에 통합하고 효율적인 훈련 및 추론을 달성하기 위해 하드웨어 인식 알고리즘을 제안합니다. Mamba의 탁월한 확장 성능은 Transformer의 유망한 대안이 될 수 있음을 보여줍니다. 동시에 Mamba의 높은 성능과 효율성은 비디오 이해 작업에 매우 적합합니다. 이미지/비디오 모델링에 Mamba를 적용하려는 초기 시도가 있었지만 비디오 이해에 대한 효과는 여전히 불분명합니다. 비디오 이해에 있어 Mamba의 잠재력에 대한 포괄적인 연구가 부족하기 때문에 다양한 비디오 관련 작업에서 Mamba의 역량을 더 자세히 탐구하는 것이 제한됩니다. 위의 문제에 대응하여 연구팀은 영상 이해 분야에서 Mamba의 잠재력을 탐색했습니다. 그들의 연구 목표는 Mamba가 이 분야에서 Transformers의 실행 가능한 대안이 될 수 있는지 평가하는 것입니다. 이를 위해 그들은 먼저 비디오를 이해하는 데 있어 Mamba의 다양한 역할을 어떻게 생각해야 하는지에 대한 질문을 다루었습니다. 이를 바탕으로 Mamba가 어떤 작업을 더 잘 수행하는지 추가로 연구했습니다. 이 논문에서는 비디오 모델링에서 Mamba의 역할을 1) 시간 모델, 2) 시간 모듈, 3) 다중 모드 상호 작용 네트워크, 4) 시공간 모델의 네 가지 범주로 나눕니다. 각 역할에 대해 연구팀은 다양한 비디오 이해 작업에 대한 비디오 모델링 기능을 연구했습니다. Manba와 Transformer를 공정하게 비교하기 위해 연구팀은 표준 또는 수정된 Transformer 아키텍처를 기반으로 비교할 모델을 신중하게 선택했습니다. 이를 바탕으로 그들은 12가지 비디오 이해 작업에 적합한 14가지 모델/모듈이 포함된 Video Mamba Suite를 얻었습니다. 연구팀은 Video Mamba Suite가 향후 SSM 기반 영상 이해 모델 탐색을 위한 기본 리소스가 되기를 희망합니다. 작업 및 데이터: 연구팀은 5가지 비디오 타이밍 작업에 대한 Mamba의 성능을 평가했습니다. ACS 세그먼트), 시간적 동작 분할(GTEA), 고밀도 비디오 캡션(ActivityNet, YouCook), 비디오 세그먼트 캡션(ActivityNet, YouCook) 및 동작 예측(Epic-Kitchen-100). 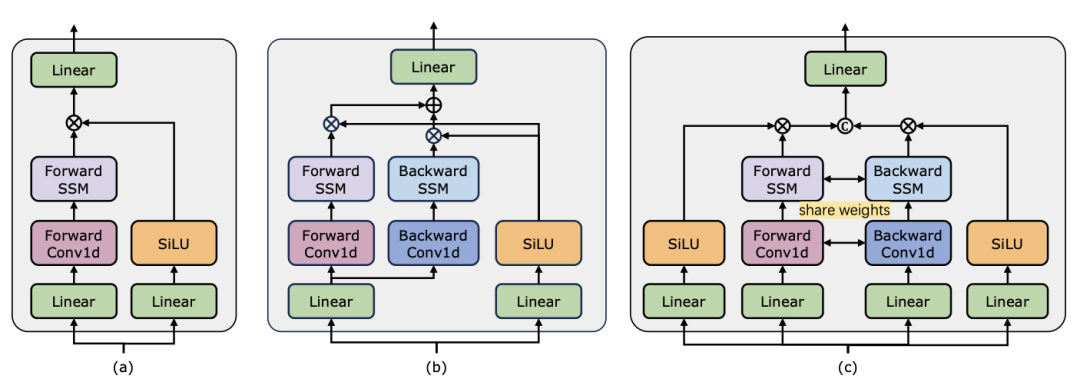 Baseline and Challenger: 연구팀은 Transformer 기반 모델을 각 작업의 기준으로 선택했습니다. 특히 이러한 기본 모델에는 ActionFormer, ASFormer, Testra 및 PDVC가 포함됩니다. Mamba 챌린저를 구축하기 위해 기본 모델의 Transformer 모듈을 Mamba 기반 모듈로 교체했습니다. 여기에는 위에 표시된 세 가지 모듈, 원래 Mamba(a), ViM(b) 및 DBM(c)이 포함됩니다. 연구팀이 설계한) 모듈입니다. 이 논문이 인과 추론과 관련된 행동 예측 작업에서 기본 모델의 성능을 원본 Mamba 모듈과 비교한다는 점은 주목할 가치가 있습니다. 결과 및 분석: 이 논문은 네 가지 작업에 대한 다양한 모델의 비교 결과를 보여줍니다. 전반적으로 일부 Transformer 기반 모델에는 성능 향상을 위해 Attention 변형이 통합되어 있습니다. 아래 표는 기존 Transformer 시리즈 방식과 비교하여 Mamba 시리즈의 우수한 성능을 보여줍니다.
Baseline and Challenger: 연구팀은 Transformer 기반 모델을 각 작업의 기준으로 선택했습니다. 특히 이러한 기본 모델에는 ActionFormer, ASFormer, Testra 및 PDVC가 포함됩니다. Mamba 챌린저를 구축하기 위해 기본 모델의 Transformer 모듈을 Mamba 기반 모듈로 교체했습니다. 여기에는 위에 표시된 세 가지 모듈, 원래 Mamba(a), ViM(b) 및 DBM(c)이 포함됩니다. 연구팀이 설계한) 모듈입니다. 이 논문이 인과 추론과 관련된 행동 예측 작업에서 기본 모델의 성능을 원본 Mamba 모듈과 비교한다는 점은 주목할 가치가 있습니다. 결과 및 분석: 이 논문은 네 가지 작업에 대한 다양한 모델의 비교 결과를 보여줍니다. 전반적으로 일부 Transformer 기반 모델에는 성능 향상을 위해 Attention 변형이 통합되어 있습니다. 아래 표는 기존 Transformer 시리즈 방식과 비교하여 Mamba 시리즈의 우수한 성능을 보여줍니다.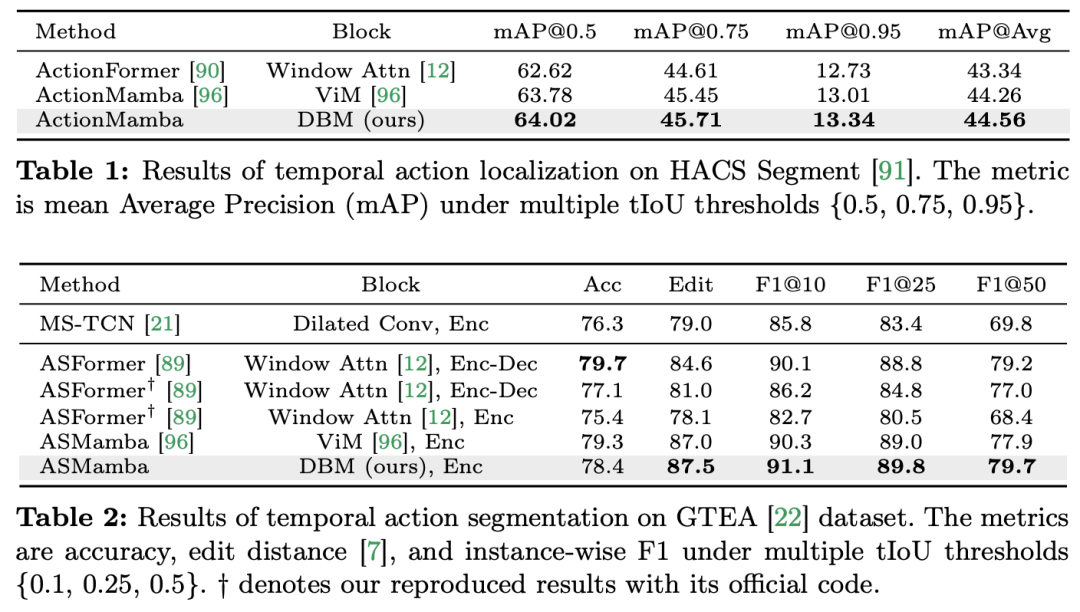
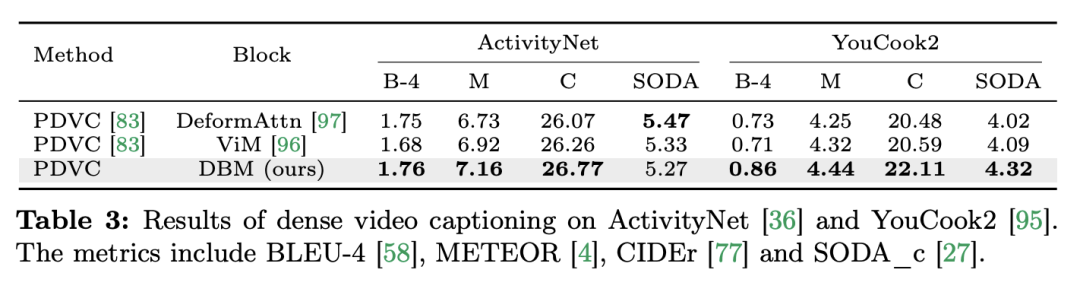
연구팀은 단일 모드 작업에만 초점을 맞춘 것이 아니라 교차 모드 상호 작용 작업에서 Mamba의 성능도 평가했습니다. 이 논문에서는 VTG(비디오 시간적 위치 파악) 작업을 사용하여 Mamba의 성능을 평가합니다. 다루는 데이터 세트에는 QvHighlight 및 Charade-STA가 포함됩니다. 작업 및 데이터: 연구팀은 시간적 동작 위치 파악(HACS 세그먼트), 시간적 동작 분할(GTEA), 밀도 높은 비디오 자막(ActivityNet, YouCook ), 비디오 단락 자막 등 5가지 비디오 시간적 작업에 대한 Mamba의 성능을 평가했습니다. (ActivityNet, YouCook) 및 행동 예측(Epic-Kitchen-100). Baseline and Challenger: 연구팀은 UniVTG를 사용하여 Mamba 기반 VTG 모델을 구축했습니다. UniVTG는 Transformer를 다중 모드 상호 작용 네트워크로 채택합니다. 비디오 기능과 텍스트 기능이 주어지면 먼저 각 모달리티에 대해 학습 가능한 위치 임베딩과 모달리티 유형 임베딩을 추가하여 위치 및 모달리티 정보를 보존합니다. 그런 다음 텍스트와 비디오 토큰이 연결되어 다중 모드 Transformer 인코더에 추가로 공급되는 공동 입력을 형성합니다. 마지막으로 텍스트 증강 비디오 특징이 추출되어 예측 헤드에 입력됩니다. 크로스 모달 Mamba 경쟁자를 만들기 위해 연구팀은 양방향 Mamba 블록을 쌓아 Transformer 기준을 대체할 다중 모달 Mamda 인코더를 형성하기로 결정했습니다. 결과 및 분석: 이 문서에서는 QvHighlight를 통해 여러 모델의 성능을 테스트합니다. Mamba의 평균 mAP는 44.74로 Transformer에 비해 크게 향상되었습니다. Charade-STA에서는 Mamba 기반 방식이 Transformer와 비슷한 경쟁력을 보여줍니다. 이는 Mamba가 다양한 양식을 효과적으로 통합할 수 있는 잠재력을 가지고 있음을 보여줍니다. 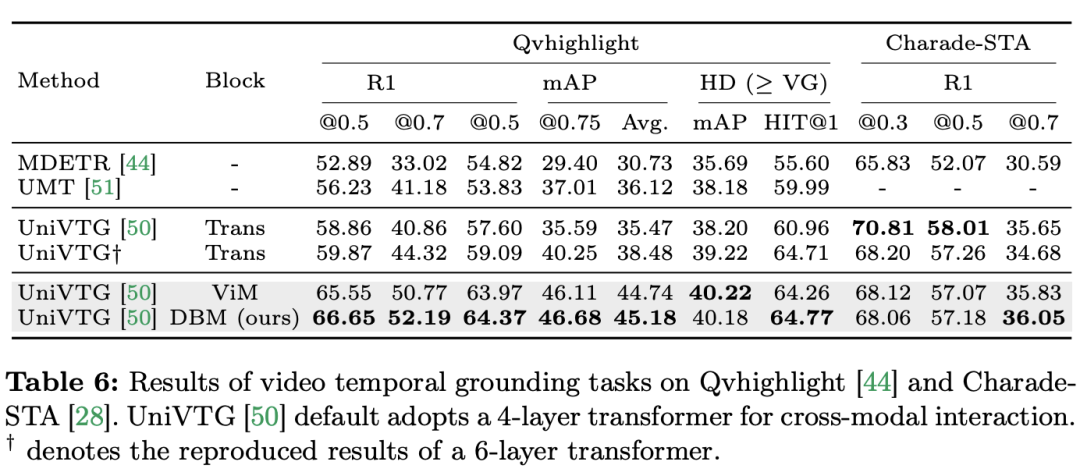
Mamba는 선형 스캐닝 기반 모델인 반면 Transformer는 글로벌 마크 상호 작용 기반 모델이라는 점을 고려하면, 연구팀은 마크 시퀀스에서 텍스트 위치가 다중 모드 집계 효과에 영향을 미칠 수 있다고 직관적으로 믿습니다. 이를 조사하기 위해 표에 다양한 텍스트-시각적 융합 방법을 포함하고 그림에 네 가지 마크 배열을 보여줍니다. 결론은 텍스트적 조건이 시각적 특징의 왼쪽에 융합될 때 가장 좋은 결과를 얻을 수 있다는 것입니다. QvHighlight는 이 융합에 영향을 덜 미치는 반면 Charade-STA는 데이터 세트의 특성으로 인해 텍스트의 위치에 특히 민감합니다. 
연구팀은 포스트 타이밍 모델링에서 Mamba의 성능을 평가하는 것 외에도 비디오 타이밍 어댑터로서의 효율성도 조사했습니다. Two Towers 모델은 세분화된 내레이션이 포함된 400만 개의 비디오 클립이 포함된 자기중심적 데이터에 대해 비디오-텍스트 대조 학습을 수행하여 사전 학습되었습니다. 작업 및 데이터: 연구팀은 Temporal Action Localization(HACS Segment), Temporal Action Segmentation(GTEA), Dense Video Subtitles(ActivityNet, YouCook), video 등 5가지 비디오 시간 작업에 대한 Mamba의 성능을 평가했습니다. 단락 자막(ActivityNet, YouCook) 및 행동 예측(Epic-Kitchen-100). Baseline 및 Challenger: TimeSformer는 별도의 시공간 Attention 블록을 채택하여 비디오의 공간적 및 시간적 관계를 별도로 모델링합니다. 이를 위해 연구팀은 기존의 Timing Self-Attention을 대체하고 별도의 시공간 상호작용을 개선하기 위해 타이밍 어댑터로 양방향 Mamba 블록을 도입했습니다. 공정한 비교를 위해 TimeSformer의 공간 주의 레이어는 변경되지 않은 상태로 유지됩니다. 여기서 연구팀은 ViM 블록을 타이밍 모듈로 사용하고 결과 모델을 TimeMamba라고 불렀습니다. 표준 ViM 블록에는 self-attention 블록보다 더 많은 매개변수(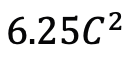 보다 약간 더 많음)가 있다는 점에 주목할 가치가 있습니다. 여기서 C는 기능 차원입니다. 따라서 논문에서는 ViM 블록의 확장 비율 E를 1로 설정하여 공정한 비교를 위해 매개변수 크기를
보다 약간 더 많음)가 있다는 점에 주목할 가치가 있습니다. 여기서 C는 기능 차원입니다. 따라서 논문에서는 ViM 블록의 확장 비율 E를 1로 설정하여 공정한 비교를 위해 매개변수 크기를 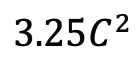 로 줄였습니다. TimeSformer에서 사용하는 일반적인 잔여 연결 형식 외에도 연구팀은 겨울왕국 스타일 적응도 탐색했습니다. 다음은 5가지 어댑터 구조입니다.
로 줄였습니다. TimeSformer에서 사용하는 일반적인 잔여 연결 형식 외에도 연구팀은 겨울왕국 스타일 적응도 탐색했습니다. 다음은 5가지 어댑터 구조입니다. 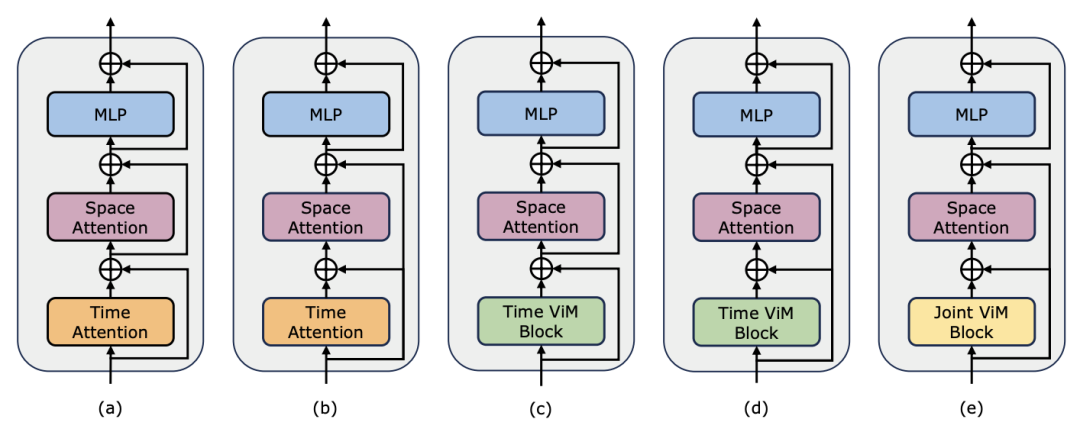
1. 제로샷 다중 인스턴스 검색. 연구팀은 먼저 표에서 별도의 시공간 상호작용이 있는 다양한 모델을 평가한 결과, 논문에 재현된 Frozen 스타일 잔여 연결이 LaViLa의 연결과 일치한다는 사실을 발견했습니다. 원본 스타일과 겨울왕국 스타일을 비교할 때 겨울왕국 스타일이 항상 더 나은 결과를 생성한다는 것을 관찰하는 것은 어렵지 않습니다. 또한 동일한 적응 방법에서 ViM 기반 시간 모듈은 항상 주의 기반 시간 모듈보다 성능이 뛰어납니다. 논문에서 사용된 ViM 임시 블록은 임시 셀프 어텐션 블록보다 매개 변수가 적다는 점에 주목할 가치가 있으며 이는 Mamba 선택적 스캐닝의 더 나은 매개 변수 활용 및 정보 추출 기능을 강조합니다. 또한 연구팀은 시공간 ViM 블록을 추가로 검증했습니다. 시공간 ViM 블록은 시간 ViM 블록을 전체 비디오 시퀀스에 대한 공동 시공간 모델링으로 대체합니다. 놀랍게도 전역 모델링의 도입에도 불구하고 시공간 ViM 블록은 실제로 성능 저하를 초래했습니다. 이를 위해 연구팀은 스캔 기반 시공간이 미리 훈련된 공간 주의 블록을 파괴하여 공간 특징 분포를 생성할 수 있다고 추측합니다. 실험 결과는 다음과 같습니다. 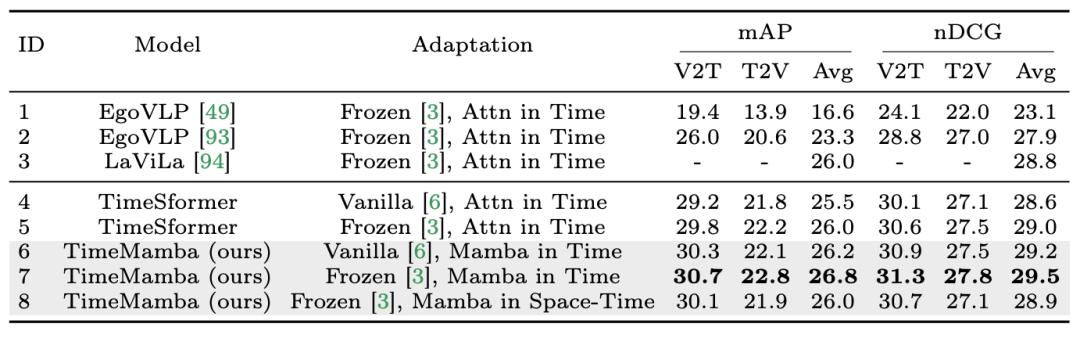
2. 다중 인스턴스 검색 및 동작 인식을 미세 조정합니다. 연구팀은 다중 인스턴스 검색 및 동작 인식을 위해 Epic-Kitchens-100 데이터세트에서 16프레임으로 미세 조정된 사전 훈련된 모델을 계속 사용하고 있습니다. 실험 결과에서 TimeMamba가 동사 인식 측면에서 TimeSformer보다 훨씬 뛰어난 성능을 보이는 것을 볼 수 있으며, 이는 2.8% 포인트를 초과하며, 이는 TimeMamba가 세분화된 타이밍을 효과적으로 모델링할 수 있음을 보여줍니다. 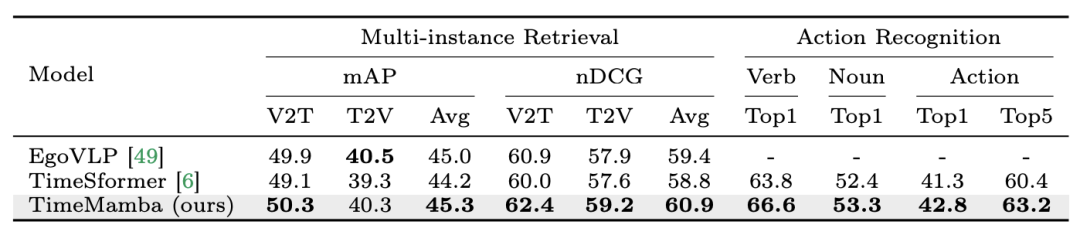
3. 제로 샘플 장편 Q&A. 연구팀은 EgoSchema 데이터 세트에서 모델의 긴 비디오 Q&A 성능을 추가로 평가했습니다. 실험 결과는 다음과 같습니다. 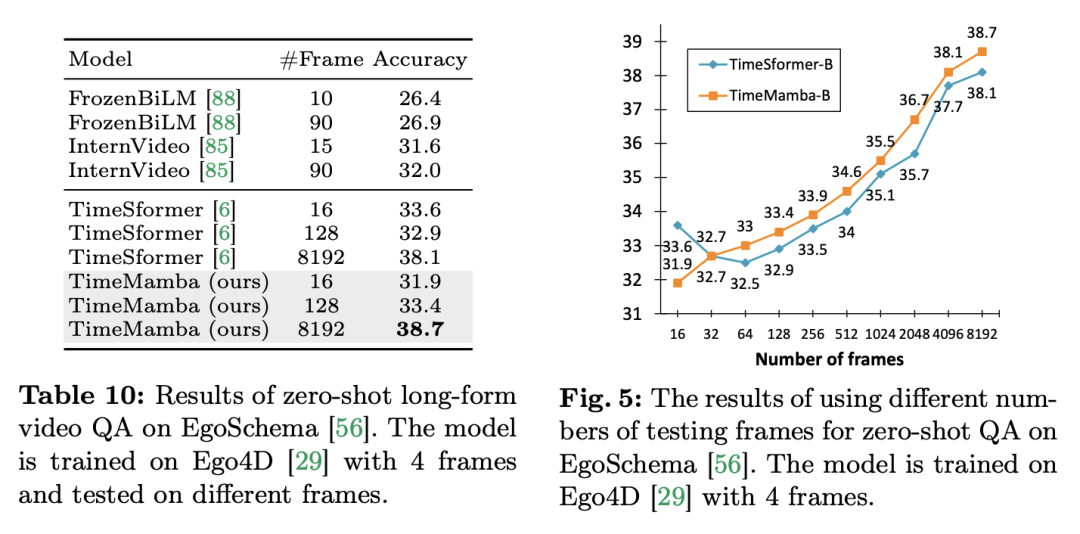
TimeSformer와 TimeMamba 모두 Ego4D에서 사전 훈련한 후 대규모 사전 훈련된 모델(예: InternVideo)의 성능을 능가합니다. 또한 연구팀은 ViM 블록의 긴 비디오 시간 모델링 기능의 영향을 탐색하기 위해 고정 FPS의 비디오에서 시작하여 테스트 프레임 수를 지속적으로 늘렸습니다. 두 모델 모두 4개의 프레임으로 사전 학습되어 있지만 TimeMamba와 TimeSformer의 성능은 프레임 수가 증가함에 따라 꾸준히 향상됩니다. 한편, 8192 프레임을 사용하면 상당한 개선이 관찰됩니다. 입력 프레임이 32개를 초과하면 TimeMamba는 일반적으로 TimeSformer보다 더 많은 프레임의 이점을 얻습니다. 이는 Temporal Self-Attention에서 Temporal ViM 블록의 우수성을 나타냅니다. 작업 및 데이터: 또한 이 논문에서는 시공간 모델링, 특히 Epic-Kitchens에서 Mamba의 기능을 평가합니다. - 모델의 성능 제로샷 다중 인스턴스 검색에서는 100개의 데이터 세트에 대해 평가됩니다. 기준선 및 경쟁사: ViViT와 TimeSformer는 공간적 주의를 기울이는 ViT를 공동의 공간적-시간적 관심을 갖는 모델로 변환하는 방법을 연구합니다. 이를 기반으로 연구팀은 ViM 모델의 공간적 선택적 스캐닝을 시공간적 선택적 스캐닝을 포함하도록 더욱 확장했습니다. 이 확장 모델의 이름을 ViViM으로 지정합니다. 연구팀은 초기화를 위해 ImageNet-1K에서 사전 훈련된 ViM 모델을 사용했습니다. ViM 모델에는 플랫 토큰 시퀀스의 중간에 삽입되는 cls 토큰이 포함되어 있습니다. 아래 그림은 ViM 모델을 ViViM으로 변환하는 방법을 보여줍니다. M개의 프레임이 포함된 특정 입력의 경우 각 프레임에 해당하는 토큰 시퀀스 중간에 cls 토큰을 삽입합니다. 또한 연구팀은 각 프레임마다 0으로 초기화되는 시간적 위치 임베딩(temporal position embedding)을 추가했습니다. 그러면 병합된 비디오 시퀀스가 ViViM 모델에 입력됩니다. 모델의 출력은 각 프레임에 대한 cls 토큰의 평균을 계산하여 얻습니다. 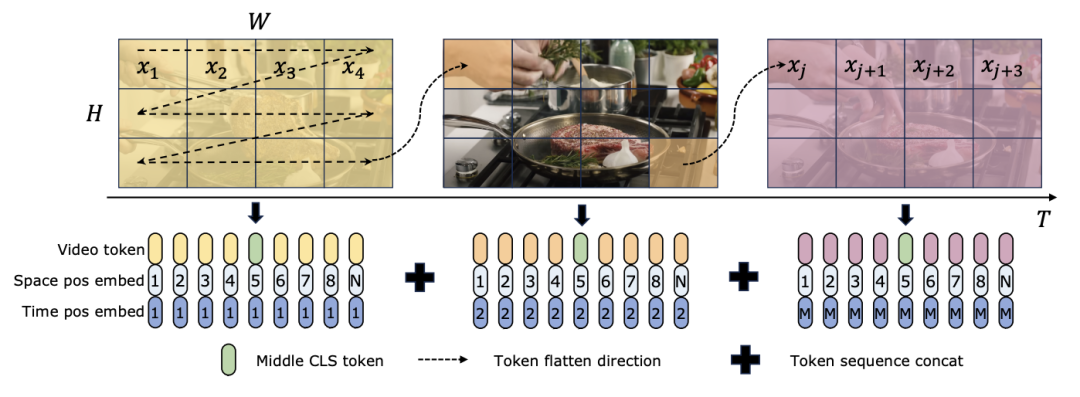
결과 및 분석: 이 논문은 제로 샘플 다중 인스턴스 검색에서 ViViM의 결과를 추가로 연구합니다. 실험 결과는 다음 표에 나와 있습니다. 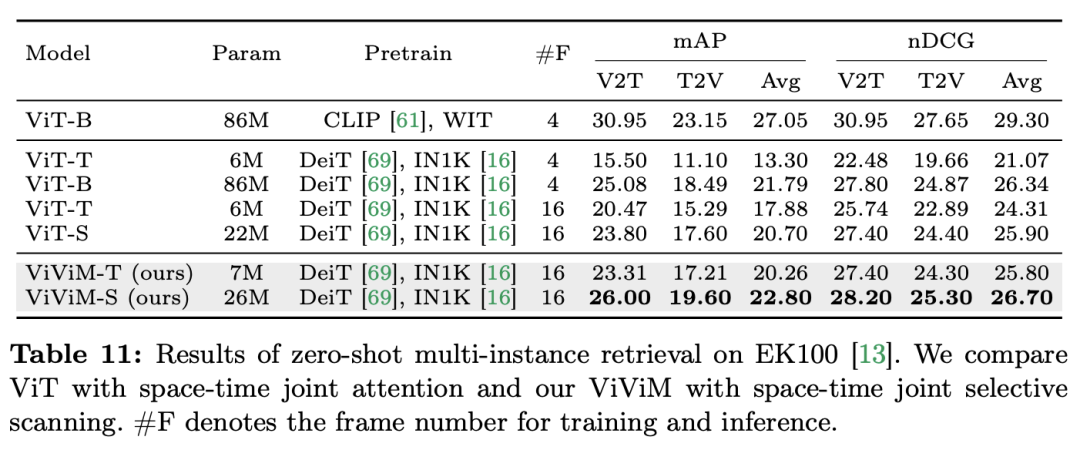
결과는 서로 다른 공간- 시간 모델은 제로 샘플 다중 인스턴스 검색을 수행합니다. ImageNet-1K에서 사전 훈련된 ViT와 ViViM을 비교해 보면 ViViM이 ViT보다 성능이 뛰어나다는 것을 알 수 있습니다. 흥미롭게도 ImageNet-1K에서 ViT-S와 ViM-S 간의 성능 차이는 작지만(79.8 대 80.5), ViViM-S는 제로샷 다중 인스턴스 검색(+2.1 mAP @Avg)에서 상당한 개선을 보여줍니다. ViViM은 긴 시퀀스를 모델링하는 데 매우 효과적이어서 성능이 향상됩니다. 이 문서는 비디오 이해 분야에서의 성능을 종합적으로 평가함으로써 기존 Transformers의 실행 가능한 대안으로서 Mamba의 잠재력을 보여줍니다. 연구팀은 12개의 비디오 이해 작업을 위한 14개의 모델/모듈로 구성된 Video Mamba Suite를 통해 복잡한 시공간 역학을 효율적으로 처리하는 Mamba의 능력을 입증했습니다. Mamba는 우수한 성능을 제공할 뿐만 아니라 더 나은 효율성과 성능의 균형을 달성합니다. 이러한 발견은 비디오 분석 작업에 대한 Mamba의 적합성을 강조할 뿐만 아니라 컴퓨터 비전 분야에 Mamba를 적용할 수 있는 새로운 길을 열어줍니다. 향후 작업에서는 Mamba의 적응성을 더욱 탐구하고 그 유용성을 보다 복잡한 다중 모드 비디오 이해 과제로 확장할 수 있습니다. 위 내용은 12개의 영상 이해 과제에서 Mamba가 Transformer를 처음으로 이겼습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



