

이 글에서는 학습 곡선을 통해 머신러닝 모델에서 과적합과 과소적합을 효과적으로 식별하는 방법을 소개합니다.
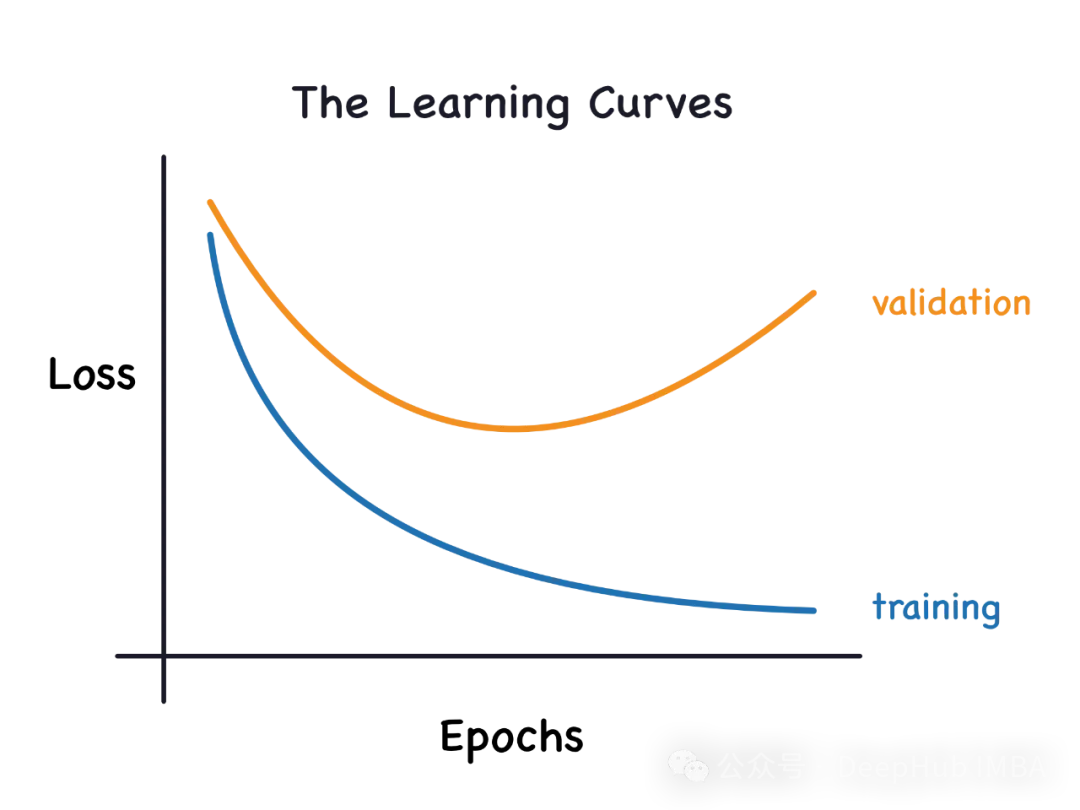
모델이 데이터에서 과도하게 학습되어 데이터로부터 노이즈를 학습하는 경우 이를 과적합이라고 합니다. 과적합된 모델은 모든 예를 너무 완벽하게 학습하므로 보이지 않거나 새로운 예를 잘못 분류합니다. 과대적합 모델의 경우 완벽/거의 완벽에 가까운 훈련 세트 점수와 형편없는 검증 세트/테스트 점수를 얻게 됩니다.
약간 수정됨: "과적합의 원인: 간단한 문제를 해결하기 위해 복잡한 모델을 사용하면 데이터에서 노이즈가 추출됩니다. 훈련 세트로 사용되는 작은 데이터 세트는 모든 데이터를 올바르게 표현하지 못할 수 있기 때문입니다."2. 과소적합
적합하지 않은 이유: 복잡한 문제를 해결하기 위해 간단한 모델을 사용합니다. 모델이 데이터의 모든 패턴을 학습할 수 없거나, 모델이 기본 데이터의 패턴을 잘못 학습합니다. 데이터 분석과 머신러닝에서는 모델 선택이 매우 중요합니다. 문제에 적합한 모델을 선택하면 예측의 정확성과 신뢰성이 향상될 수 있습니다. 복잡한 문제의 경우 데이터의 모든 패턴을 캡처하려면 더 복잡한 모델이 필요할 수 있습니다. 또한
Learning Curve
from sklearn.model_selection import learning_curve
#The function below builds the model and returns cross validation scores, train score and learning curve data def learn_curve(X,y,c): ''' param X: Matrix of input featuresparam y: Vector of Target/Labelc: Inverse Regularization variable to control overfitting (high value causes overfitting, low value causes underfitting)''' '''We aren't splitting the data into train and test because we will use StratifiedKFoldCV.KFold CV is a preferred method compared to hold out CV, since the model is tested on all the examples.Hold out CV is preferred when the model takes too long to train and we have a huge test set that truly represents the universe''' le = LabelEncoder() # Label encoding the target sc = StandardScaler() # Scaling the input features y = le.fit_transform(y)#Label Encoding the target log_reg = LogisticRegression(max_iter=200,random_state=11,C=c) # LogisticRegression model # Pipeline with scaling and classification as steps, must use a pipelne since we are using KFoldCV lr = Pipeline(steps=(['scaler',sc],['classifier',log_reg])) cv = StratifiedKFold(n_splits=5,random_state=11,shuffle=True) # Creating a StratifiedKFold object with 5 folds cv_scores = cross_val_score(lr,X,y,scoring="accuracy",cv=cv) # Storing the CV scores (accuracy) of each fold lr.fit(X,y) # Fitting the model train_score = lr.score(X,y) # Scoring the model on train set #Building the learning curve train_size,train_scores,test_scores =learning_curve(estimator=lr,X=X,y=y,cv=cv,scoring="accuracy",random_state=11) train_scores = 1-np.mean(train_scores,axis=1)#converting the accuracy score to misclassification rate test_scores = 1-np.mean(test_scores,axis=1)#converting the accuracy score to misclassification rate lc =pd.DataFrame({"Training_size":train_size,"Training_loss":train_scores,"Validation_loss":test_scores}).melt(id_vars="Training_size") return {"cv_scores":cv_scores,"train_score":train_score,"learning_curve":lc}
1. 피팅 모델의 학습 곡선
lc = learn_curve(X,y,1) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Deep HUB Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])}\n\n\ Training Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of Good Fit Model") plt.ylabel("Misclassification Rate/Loss");
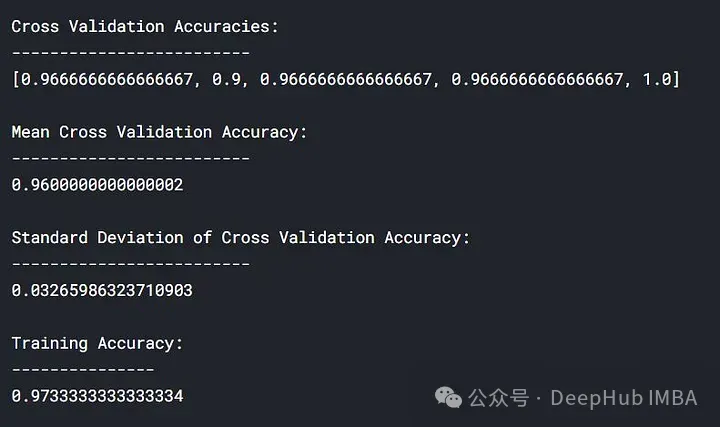 위 결과에서 교차 검증 정확도는 훈련 정확도에 가깝습니다.
위 결과에서 교차 검증 정확도는 훈련 정확도에 가깝습니다.
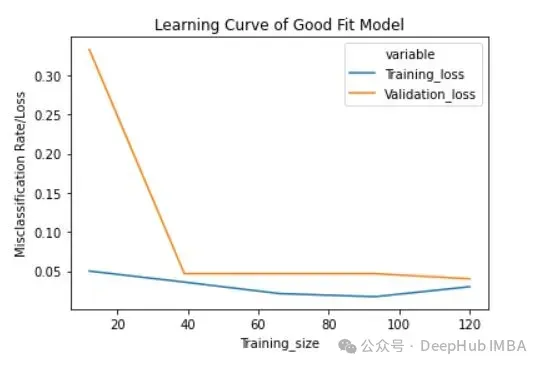 훈련 손실(파란색): 잘 맞는 모델의 학습 곡선은 훈련 사례 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 더 많은 훈련 사례를 추가해도 모델의 성능을 향상시킬 수 없음을 나타냅니다. 훈련 데이터.
훈련 손실(파란색): 잘 맞는 모델의 학습 곡선은 훈련 사례 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 더 많은 훈련 사례를 추가해도 모델의 성능을 향상시킬 수 없음을 나타냅니다. 훈련 데이터.
검증 손실(노란색): 잘 맞는 모델의 학습 곡선은 처음에는 검증 손실이 높으며 훈련 샘플 수가 증가함에 따라 점차적으로 감소하고 평탄해집니다. 이는 샘플이 많을수록 더 많은 패턴을 배울 수 있으며 이는 "보이지 않는" 데이터에 도움이 될 것입니다
마지막으로, 합리적인 수의 훈련 예제를 추가한 후에 훈련 손실과 검증 손실이 서로 가깝다는 것을 알 수 있습니다.
2. 과적합 모델의 학습 곡선
lc = learn_curve(X,y,10000) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Deep HUB Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])} (High Variance)\n\n\ Training Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of an Overfit Model") plt.ylabel("Misclassification Rate/Loss");
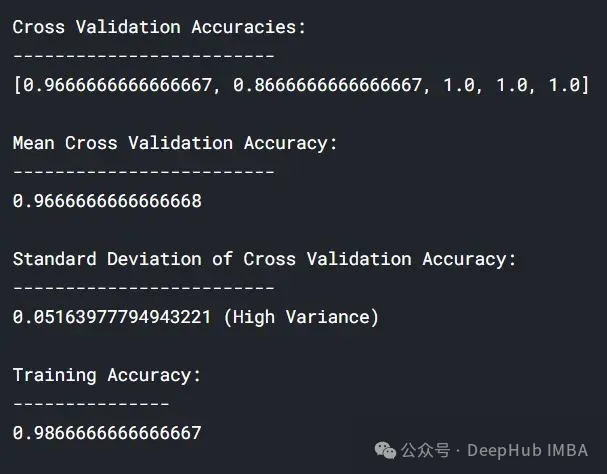
与拟合模型相比,交叉验证精度的标准差较高。
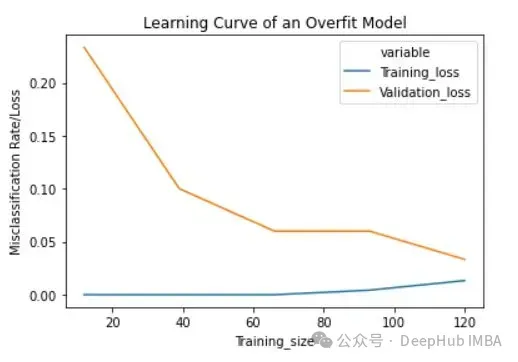
过拟合模型的学习曲线一开始的训练损失很低,随着训练样例的增加,学习曲线逐渐增加,但不会变平。过拟合模型的学习曲线在开始时具有较高的验证损失,随着训练样例的增加逐渐减小并且不趋于平坦,说明增加更多的训练样例可以提高模型在未知数据上的性能。同时还可以看到,训练损失和验证损失彼此相差很远,在增加额外的训练数据时,它们可能会彼此接近。
将反正则化变量/参数' c '设置为1/10000来获得欠拟合模型(' c '的低值导致欠拟合)。
lc = learn_curve(X,y,1/10000) print(f'Cross Validation Accuracies:\n{"-"*25}\n{list(lc["cv_scores"])}\n\n\ Mean Cross Validation Accuracy:\n{"-"*25}\n{np.mean(lc["cv_scores"])}\n\n\ Standard Deviation of Cross Validation Accuracy:\n{"-"*25}\n{np.std(lc["cv_scores"])} (Low variance)\n\n\ Training Deep HUB Accuracy:\n{"-"*15}\n{lc["train_score"]}\n\n') sns.lineplot(data=lc["learning_curve"],x="Training_size",y="value",hue="variable") plt.title("Learning Curve of an Underfit Model") plt.ylabel("Misclassification Rate/Loss");
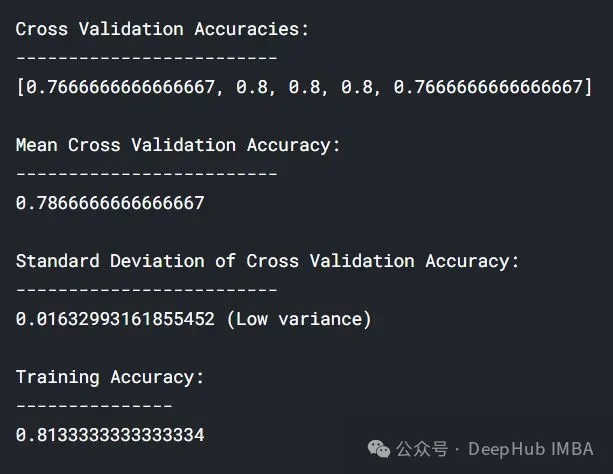
与过拟合和良好拟合模型相比,交叉验证精度的标准差较低。
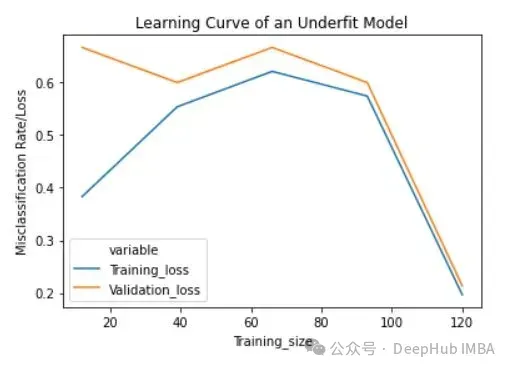
欠拟合模型的学习曲线在开始时具有较低的训练损失,随着训练样例的增加逐渐增加,并在最后突然下降到任意最小点(最小并不意味着零损失)。这种最后的突然下跌可能并不总是会发生。这表明增加更多的训练样例并不能提高模型在未知数据上的性能。
在机器学习和统计建模中,过拟合(Overfitting)和欠拟合(Underfitting)是两种常见的问题,它们描述了模型与训练数据的拟合程度如何影响模型在新数据上的表现。
分析生成的学习曲线时,可以关注以下几个方面:
根据学习曲线的分析,你可以采取以下策略进行调整:
使用正则化技术(如L1、L2正则化)。
减少模型的复杂性,比如减少参数数量、层数或特征数量。
增加更多的训练数据。
应用数据增强技术。
使用早停(early stopping)等技术来避免过度训练。
通过这样的分析和调整,学习曲线能够帮助你更有效地优化模型,并提高其在未知数据上的泛化能力。
위 내용은 학습 곡선을 통해 과적합과 과소적합 식별의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



