

시험문제가 너무 쉬우면 상위권과 하위권 모두 90점을 받아 격차가 없을텐데...
클로드 3, 라마 3, 그리고 이후에는 GPT 등 더욱 강력한 모델이 출시되면서- 5, 업계에서는 보다 어려운 모델과 보다 차별화된 벤치마크 테스트가 시급히 필요합니다.
대형 모델 아레나를 만든 조직인 LMSYS가 차세대 벤치마크인 Arena-Hard를 출시해 많은 관심을 받았습니다.
Llama 3의 두 가지 지침이 미세 조정된 버전의 강점에 대한 최신 참조 자료도 제공됩니다.
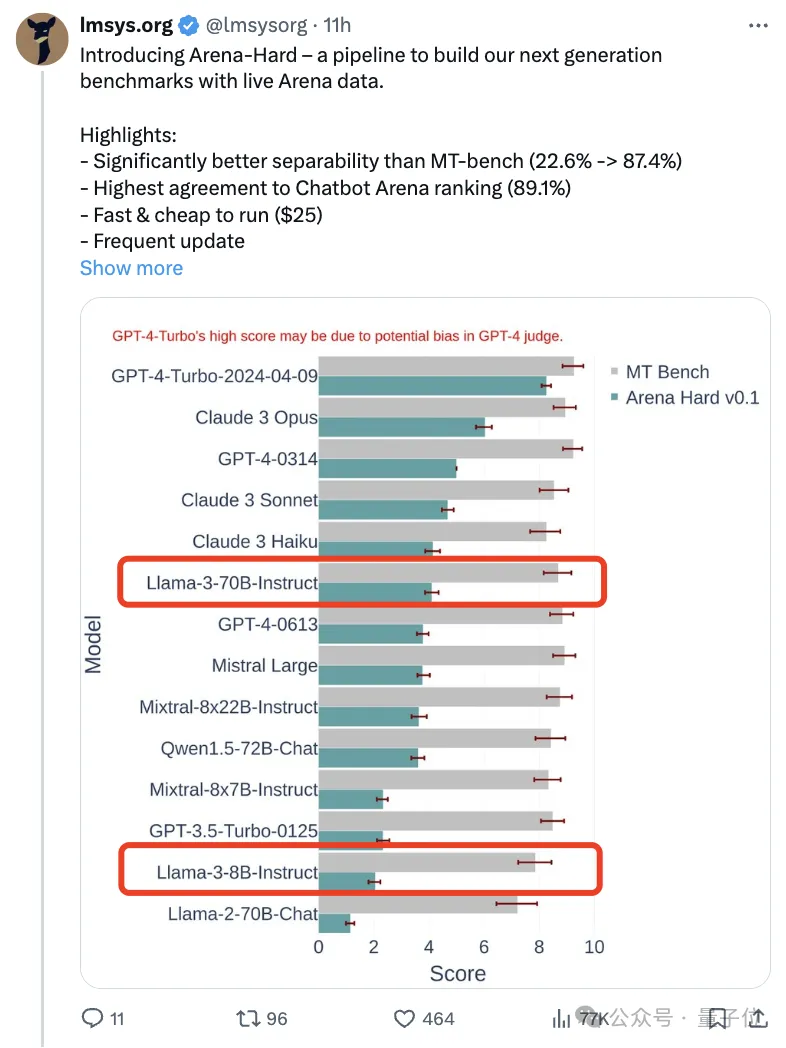
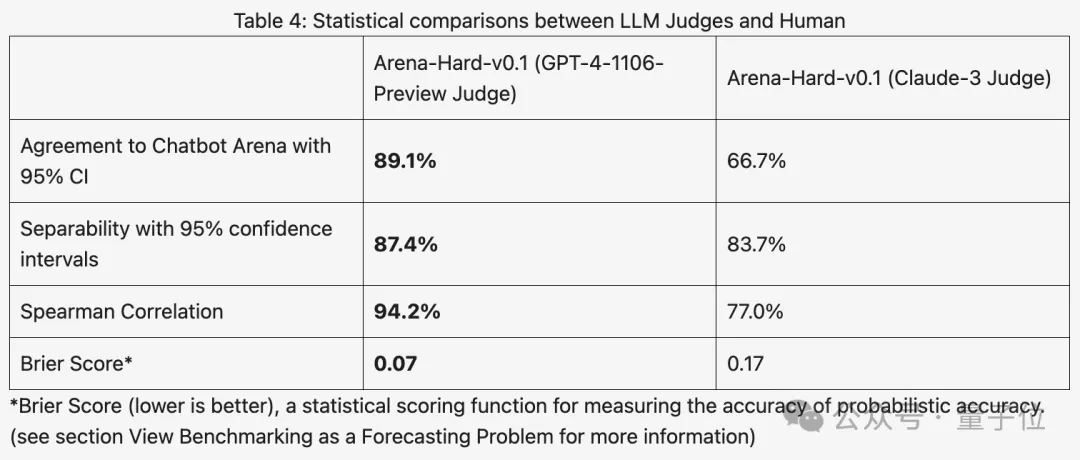
비슷한 점수를 받았던 이전 MT 벤치와 비교해 아레나-하드 차별성은 22.6%에서 87.4%로 높아졌는데, 이는 한 눈에 확연하다.
Arena-Hard는 경기장의 실시간 인간 데이터를 사용하여 구축되었으며 인간 선호도와의 일관성 비율은 89.1%에 달합니다.
SOTA에 도달하는 위의 두 가지 지표 외에도 추가 이점이 있습니다.
실시간 업데이트되는 테스트 데이터에는 훈련 단계에서 인간이 새로 생각하고 AI가 본 적이 없는 프롬프트 단어가 포함되어 잠재적인 데이터를 완화합니다. .
새 모델을 출시한 후 더 이상 인간 사용자가 투표할 때까지 일주일 정도 기다릴 필요가 없습니다. $25만 지출하면 테스트 파이프라인을 신속하게 실행하고 결과를 얻을 수 있습니다.
일부 네티즌들은 시험에서 고등학교 시험 대신 실제 사용자 프롬프트 단어를 사용하는 것이 정말 중요하다고 말했습니다.

간단히 말하면 대형 모델 분야의 20만 사용자 쿼리 중에서 500개의 고품질 프롬프트 단어가 테스트 세트로 선택됩니다.
먼저 선택 과정에서 다양성을 보장하세요. 즉, 테스트 세트는 광범위한 실제 주제를 다루어야 합니다.
이를 보장하기 위해 팀은 BERTopic의 주제 모델링 파이프라인을 채택합니다. 먼저 OpenAI의 임베딩 모델(text-embedding-3-small)을 사용하여 각 팁을 변환하고, UMAP를 사용하여 차원을 줄이고, 계층 기반 모델 알고리즘을 사용하여 클러스터링합니다( HDBSCAN)을 사용하여 클러스터를 식별하고 마지막으로 집계에 GPT-4-turbo를 사용합니다.
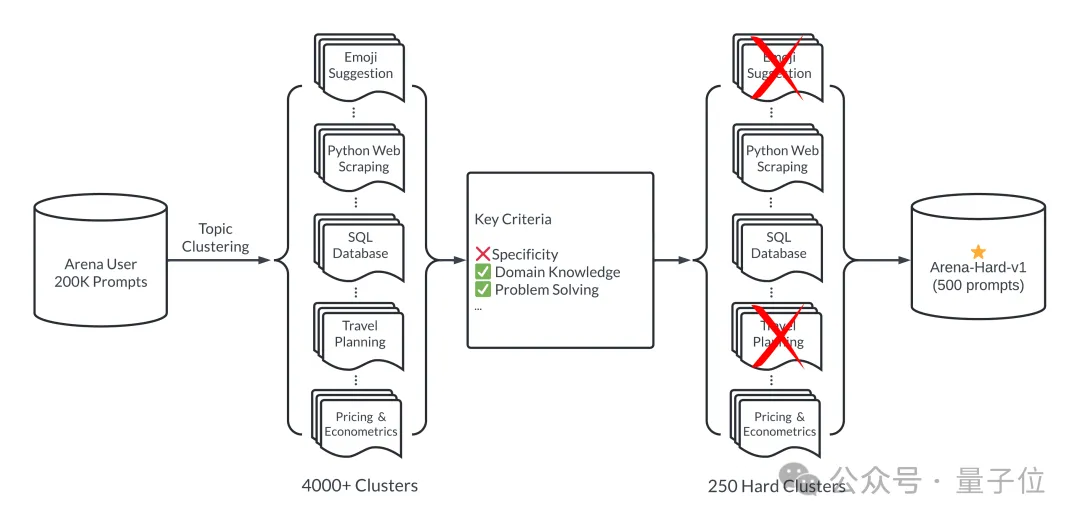
또한 선택한 프롬프트 단어가 7가지 핵심 지표로 측정되는 고품질인지 확인하세요.

GPT-3.5-Turbo 및 GPT-4-Turbo를 사용하여 0부터 7까지 각 팁에 주석을 달아 얼마나 많은 조건이 충족되는지 확인하세요. 그런 다음 각 클러스터는 단서의 평균 점수를 기준으로 점수가 매겨집니다.
고품질 질문은 일반적으로 게임 개발이나 수학적 증명과 같은 어려운 주제나 작업과 관련이 있습니다.
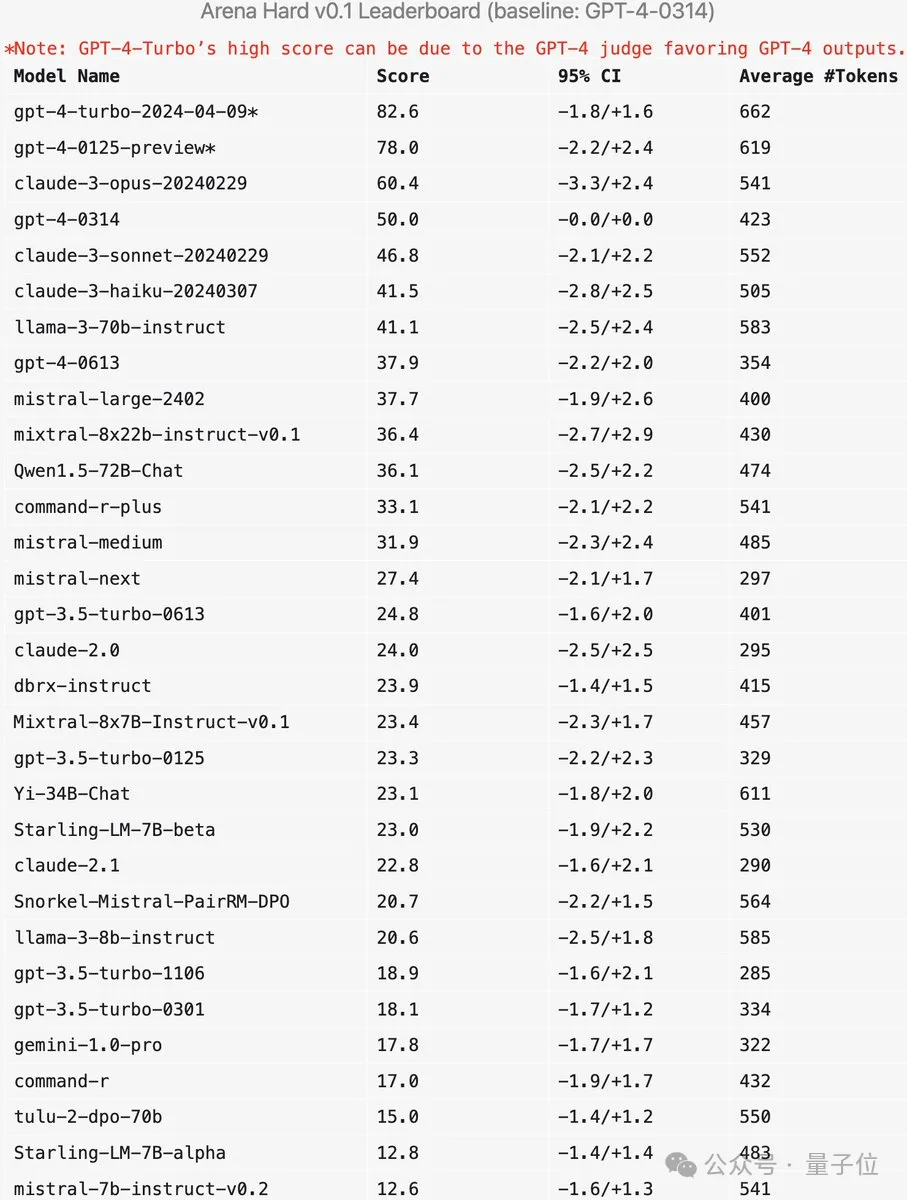
Arena-Hard에는 현재 약점이 있습니다. GPT-4를 심판으로 사용하면 자체 출력을 선호합니다. 관계자들은 이에 상응하는 팁도 전했다.
최근 두 버전의 GPT-4 점수가 Claude 3 Opus보다 훨씬 높다는 것을 알 수 있지만, 인간 투표 점수의 차이는 그다지 뚜렷하지 않습니다.
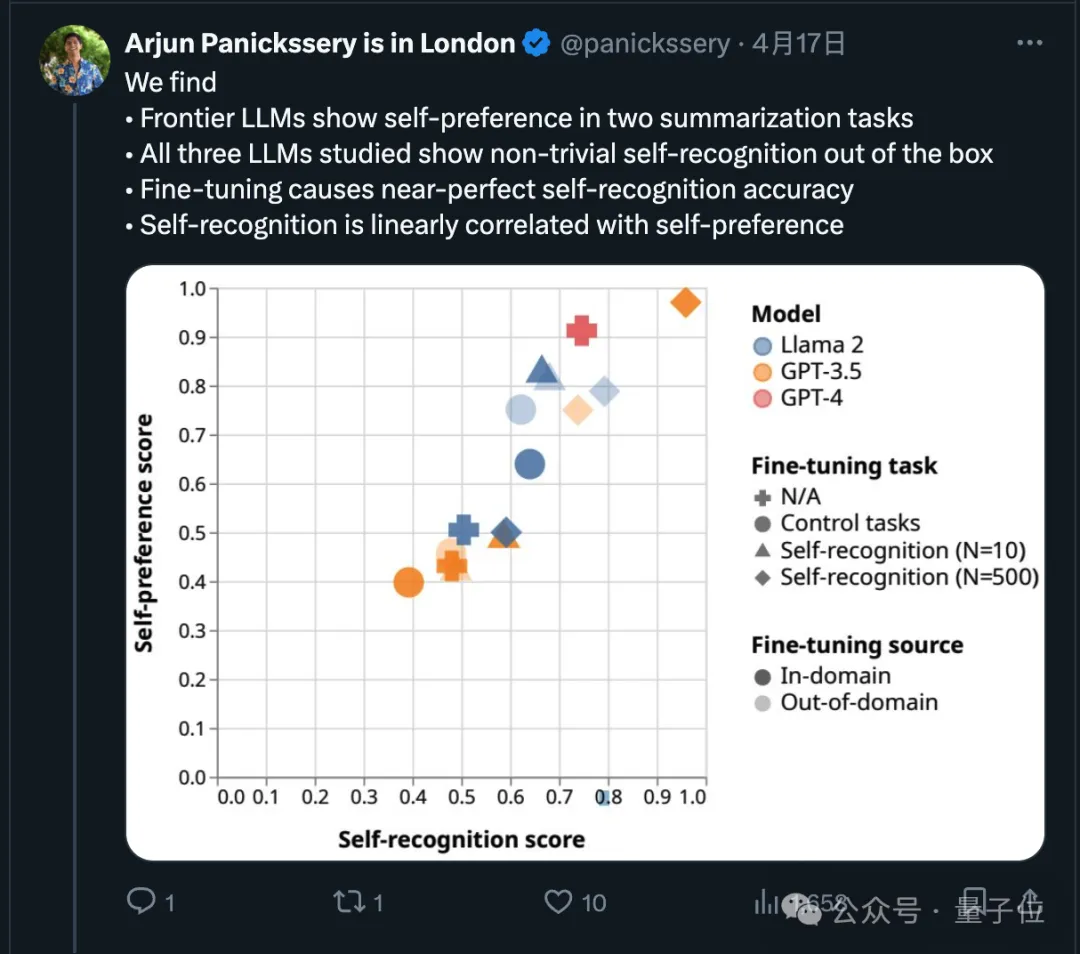
사실 이 점과 관련하여 최근 연구에 따르면 최첨단 모델은 자체 출력을 선호하는 것으로 나타났습니다.

연구팀은 또한 AI가 텍스트가 스스로 작성되었는지 여부를 본질적으로 판단할 수 있다는 사실을 발견했습니다. 미세 조정 후에는 자기 인식 능력이 향상될 수 있으며, 자기 인식 능력은 자기 인식 능력과 선형적으로 관련됩니다. 선호.
그럼 채점에 Claude 3를 사용하면 결과가 어떻게 바뀔까요? LMSYS도 관련 실험을 해왔습니다.
우선 클로드 시리즈의 점수가 확실히 오를 겁니다.
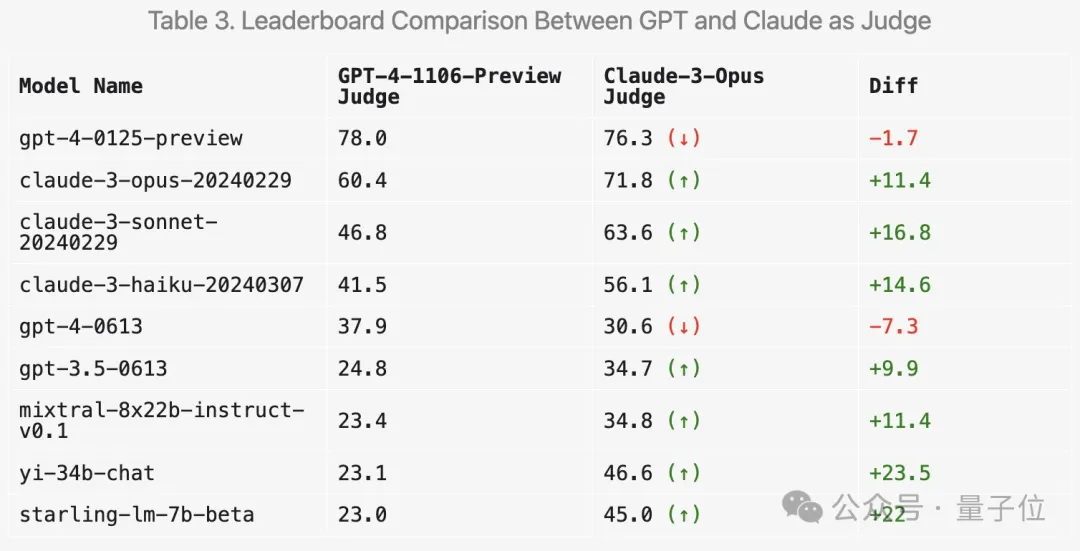
그러나 놀랍게도 Mixtral 및 Zero One Thousand Yi와 같은 여러 개방형 모델을 선호하며 GPT-3.5에서도 훨씬 더 높은 점수를 받았습니다.
전반적으로 Claude 3를 사용하여 채점한 인간 결과와의 차별성과 일관성은 GPT-4만큼 좋지 않습니다.
많은 네티즌들이 종합 채점을 위해 여러 대형 모델을 사용할 것을 제안했습니다.
또한 팀은 새로운 벤치마크 테스트의 효율성을 검증하기 위해 더 많은 절제 실험을 수행했습니다.
예를 들어 프롬프트 단어에 "답변을 최대한 자세하게 작성하세요"를 추가하면 평균 출력 길이가 길어지고 실제로 점수가 향상됩니다.
그러나 프롬프트 단어를 "채팅에 좋아요"로 변경하면 평균 출력 길이도 늘어났지만 점수 향상은 뚜렷하지 않았습니다.
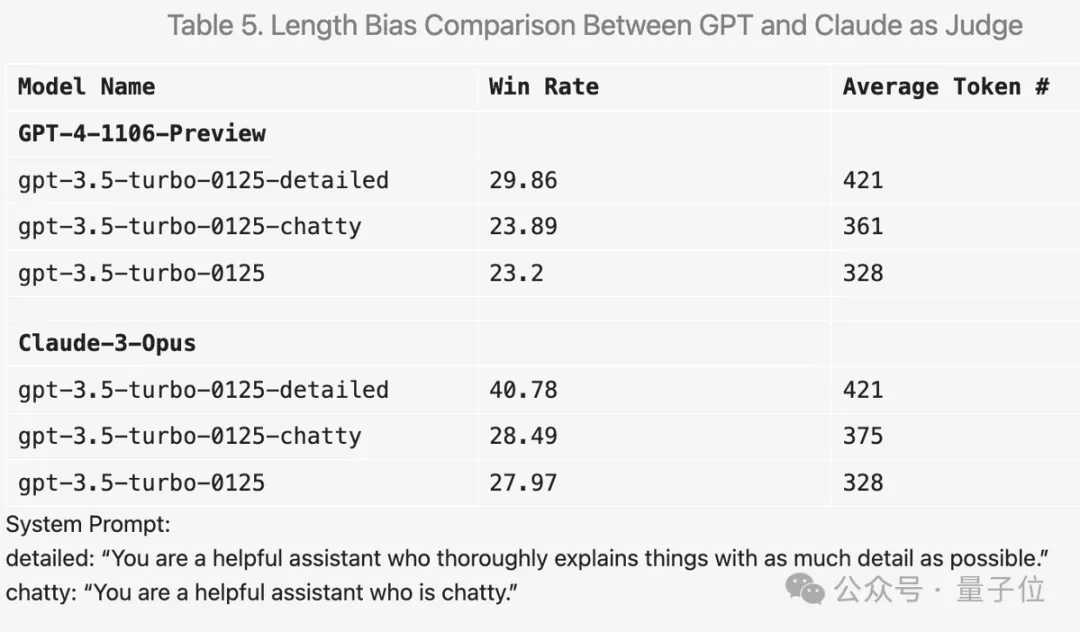
이 외에도 실험 중에 흥미로운 발견이 많이 있었습니다.
예를 들어 GPT-4는 채점에 있어서 매우 엄격한데, 답변에 오류가 있으면 엄중하게 감점되지만 Claude 3는 작은 오류를 인정해도 관대합니다.
코드 질문의 경우 Claude 3는 간단한 구조로 답변을 제공하는 경향이 있고 외부 코드 라이브러리에 의존하지 않으며 인간이 프로그래밍을 배우는 데 도움을 줄 수 있는 반면 GPT-4-Turbo는 교육적 가치에 관계없이 가장 실용적인 답변을 선호합니다.
또한 온도를 0으로 설정하더라도 GPT-4-Turbo는 약간 다른 판단을 내릴 수 있습니다.
계층 시각화의 처음 64개 클러스터에서도 대형 모델 분야 사용자가 묻는 질문의 품질과 다양성이 실제로 높다는 것을 알 수 있습니다.
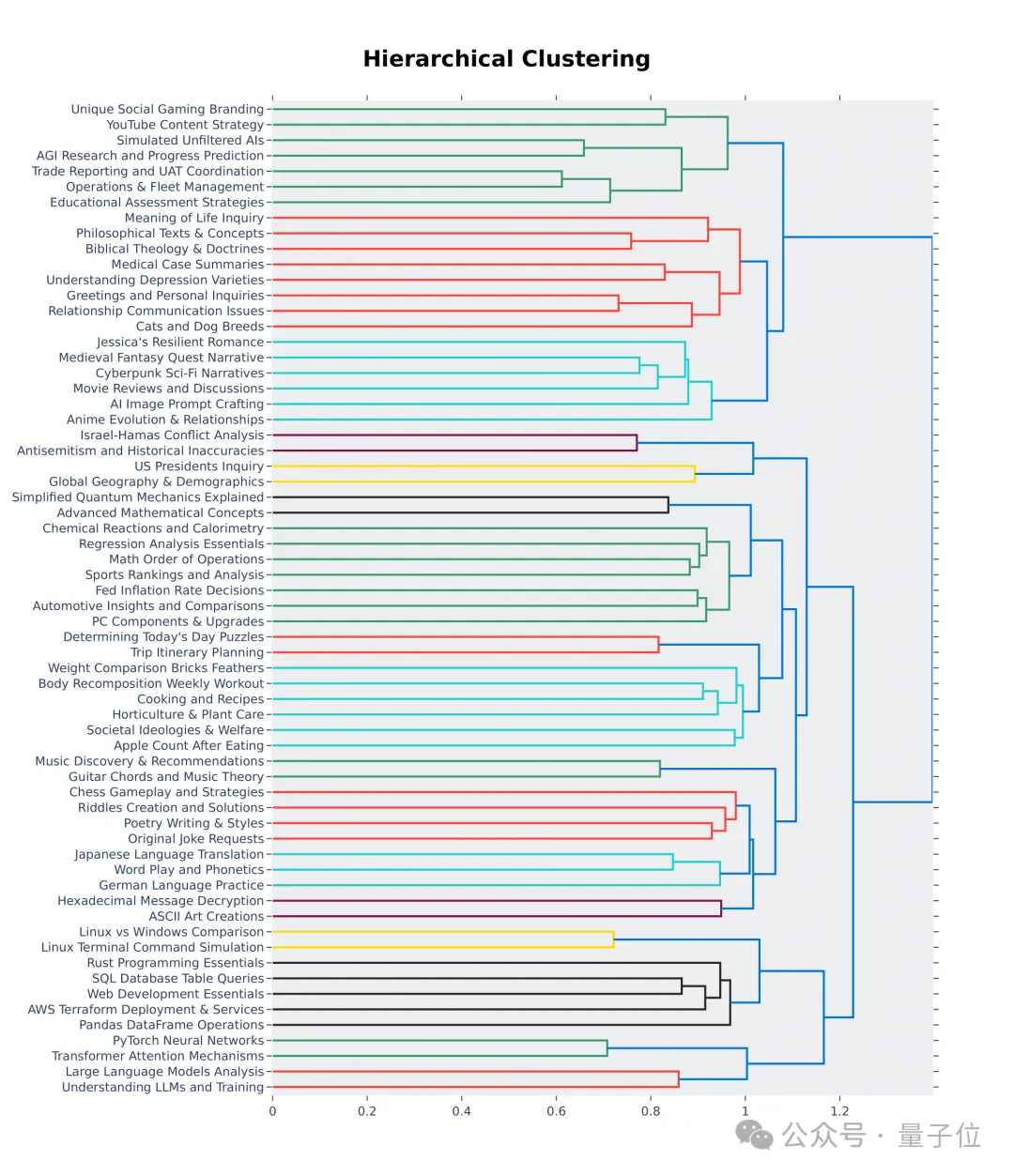
아마도 여기에 여러분의 기여가 있을 것입니다.
Arena-Hard GitHub: https://github.com/lm-sys/arena-hard
Arena-Hard HuggingFace: https://huggingface.co/spaces/lmsys/arena-hard-browser
대형 모델 경기장: https://arena.lmsys.org
참조 링크:
[1]https://x.com/lmsysorg/status/1782179997622649330
[2]https://lmsys.org/blog/2024-04 - 19-아레나-하드/
위 내용은 새로운 테스트 벤치마크 공개, 가장 강력한 오픈소스 라마3 당황스럽다의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



