

Google에 이어 Meta도 무한히 긴 컨텍스트를 굴립니다.
Transformers의 2차 복잡성과 약한 길이 외삽은 긴 시퀀스로 확장하는 능력을 제한합니다. 선형 주의 및 상태 공간 모델과 같은 2차 솔루션이 존재하지만 과거 경험으로 볼 때 사전 훈련 효율성 측면에서 성능이 좋지 않습니다. 및 다운스트림 작업 정확도.
최근 Google이 제안한 Infini-Transformer는 저장 공간 및 컴퓨팅 요구 사항을 늘리지 않고도 Transformer 기반 LLM(대형 언어 모델)을 무한히 긴 입력으로 확장할 수 있는 효과적인 방법을 선보여 사람들의 관심을 끌었습니다.
거의 동시에 메타도 무한히 긴 텍스트 기술을 제안했습니다.

논문 주소: https://arxiv.org/pdf/2404.08801.pdf
논문 제목: MEGALODON: Efficient LLM Pretraining and Inference with Unlimited Context Length
코드: https:/ /github.com/XuezheMax/megalodon
4월 12일 제출된 논문에서 Meta, University of Southern California, CMU, UCSD 및 기타 기관은 효율적인 시퀀스 모델링을 위한 신경망인 MEGALODON을 도입했습니다. 제한되지 않습니다.
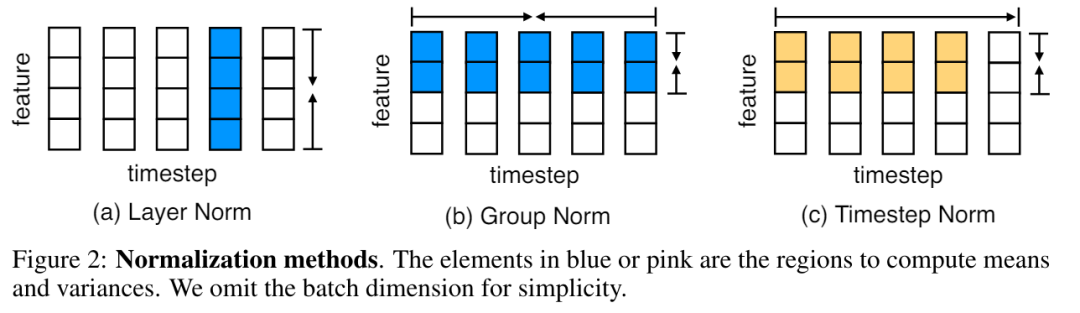
MEGALODON은 MEGA(Gated Attention을 사용한 지수 이동 평균)의 구조를 더욱 발전시키고 CEMA(복소 지수 이동 평균), 시간 단계 정규화 계층, 정규화된 주의 메커니즘 및 두 가지 특징을 가진 사전 정규화된 잔차 연결.

LLAMA2와 직접 비교하면 MEGALODON은 70억 개의 매개변수와 2조 개의 훈련 토큰 규모에서 Transformer보다 더 나은 효율성을 달성합니다. MEGALODON의 훈련 손실은 LLAMA2-7B(1.75)와 13B(1.67) 사이인 1.70에 이릅니다. Transformers에 대한 MEGALODON의 개선 사항은 다양한 작업 및 양식에 대한 다양한 벤치마크에서 강력한 성능을 보여줍니다.
MEGALODON은 기본적으로 Gated Attention 메커니즘과 고전적인 지수 이동 평균(EMA) 방법을 활용하는 향상된 MEGA 아키텍처(Ma et al., 2023)입니다. 대규모 장기 상황 사전 훈련에서 MEGALODON의 성능과 효율성을 더욱 향상시키기 위해 저자는 다양한 기술 구성 요소를 제안했습니다. 첫째, MEGALODON은 MEGA의 다차원 감쇠 EMA를 복소 영역으로 확장하는 복소 지수 이동 평균(CEMA) 구성 요소를 도입합니다. 둘째, MEGALODON은 그룹 정규화 계층을 자동회귀 시퀀스 모델링 작업으로 일반화하여 순차 차원에 따른 정규화를 허용하는 시간 단계 정규화 계층을 제안합니다.
대규모 사전 훈련의 안정성을 향상시키기 위해 MEGALODON은 널리 채택되는 사전 정규화 및 사후 정규화 방법을 수정하여 2홉 잔차 구성을 사용한 사전 정규화뿐만 아니라 정규화된 주의도 제안합니다. MEGALODON은 MEGA-chunk에서 수행된 것처럼 입력 시퀀스를 고정된 청크로 간단히 청크함으로써 모델 훈련 및 추론에서 선형 계산 및 메모리 복잡성을 달성합니다.
LLAMA2와 직접 비교할 때 MEGALODON-7B는 데이터 및 계산을 제어하는 동시에 훈련 복잡성 측면에서 LLAMA2-7B를 훈련하는 데 사용되는 최첨단 Transformer 변형보다 훨씬 뛰어납니다. 최대 2M의 다양한 컨텍스트 길이에서의 복잡성과 스크롤의 긴 컨텍스트 QA 작업을 포함한 긴 컨텍스트 모델링에 대한 평가는 무한 길이 시퀀스를 모델링하는 MEGALODON의 능력을 보여줍니다. LRA, ImageNet, Speech Commands, WikiText-103 및 PG19를 포함한 중소 규모 벤치마크에 대한 추가 실험 결과는 MEGALODON의 볼륨 및 다중 모드 기능을 보여줍니다.
방법 소개
우선, 이 글에서는 MEGA(Moving Average Equipped Gated Attention) 아키텍처의 주요 구성 요소를 간략하게 검토하고 MEGA에 존재하는 문제점에 대해 논의합니다.
MEGA는 주의 행렬 계산에 EMA(지수 이동 평균) 구성 요소를 삽입하여 시간 단계 차원에 걸쳐 귀납적 편향을 통합합니다. 특히, 다차원 감쇠 EMA는 먼저 입력 시퀀스의 각 차원을 확장합니다. 형식은 다음과 같습니다. 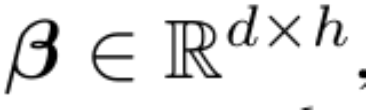
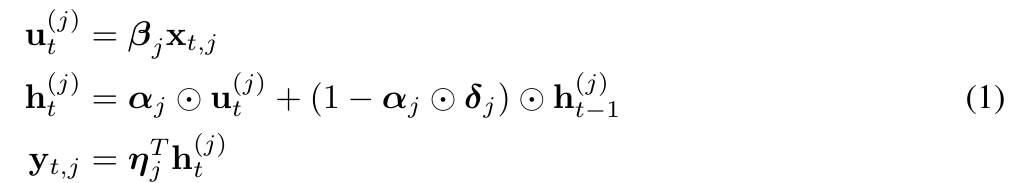
기술적으로 말하면, MEGA의 EMA 하위 계층은 각 토큰 근처의 로컬 상황 정보를 캡처하는 데 도움을 주어 블록 경계를 넘어선 상황에서 정보가 손실되는 문제를 완화합니다. MEGA가 인상적인 결과를 달성했지만 다음과 같은 문제에 직면합니다.
i) MEGA에서 EMA 하위 계층의 제한된 표현력으로 인해 블록 수준 Attention을 사용하는 MEGA의 성능은 여전히 Full Attention MEGA에 비해 뒤떨어집니다.
ii) 다양한 작업 및 데이터 유형의 경우 최종 MEGA 아키텍처에는 다양한 정규화 레이어, 정규화 모드 및 주의 기능 f(・)와 같은 구조적 차이가 있을 수 있습니다.
iii) MEGA가 대규모 사전 훈련을 위해 확장된다는 경험적 증거는 없습니다.


CEMA: 다차원 감쇠 EMA를 복잡한 영역으로 확장
MEGA가 직면한 문제를 해결하기 위해 본 연구에서는 MEGALODON을 제안합니다.
구체적으로 그들은 위의 방정식 (1)을 다음 형식으로 다시 작성하고 (2)의 θ_j를 다음과 같이 매개변수화하는 복소 지수 이동 평균 CEMA(복소 지수 이동 평균)를 창의적으로 제안했습니다.
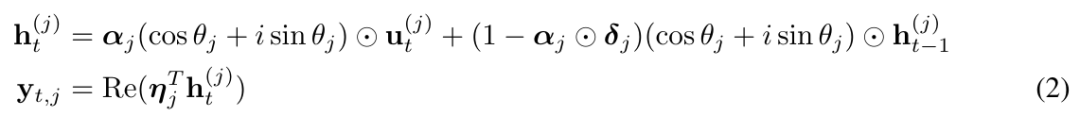
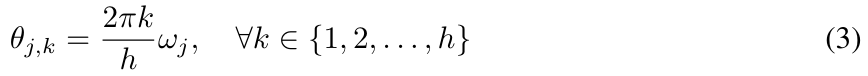
MEGALODON에서 본 연구는 누적 평균과 분산을 계산하여 그룹 정규화를 자기회귀 사례로 확장합니다.
그림 2는 레이어 정규화와 시간 단계 정규화를 보여줍니다.
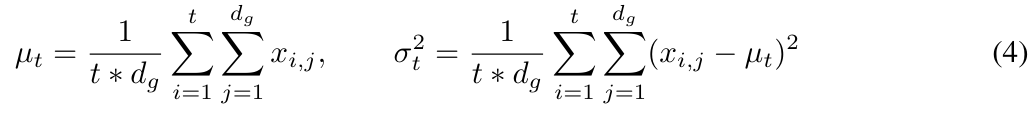
그러면 위 식 (17)의 attention 연산은 다음과 같이 변경됩니다. 모델 크기를 늘리면 사전 정규화 불안정성이 발생할 수 있습니다. Transformer 블록을 기반으로 한 사전 정규화는 다음과 같이 표현될 수 있습니다(그림 3(b) 참조).

 원래 MEGA 아키텍처에서는 게이트된 잔류 연결(21 ) 이 문제를 완화하기 위해. 그러나 업데이트 게이트 Φ는 더 많은 모델 매개변수를 도입하며 모델 크기가 70억으로 확장되면 불안정성 문제가 여전히 존재합니다. MEGALODON은 그림 3(c)와 같이 각 블록의 잔여 연결을 간단히 재배열하는 2홉 잔차가 있는 사전 표준이라는 새로운 구성을 도입합니다. 긴 컨텍스트 시퀀스 모델링에서 MEGALODON의 확장성과 효율성을 평가하기 위해 이 논문에서는 MEGALODON을 70억 규모로 확장합니다.
원래 MEGA 아키텍처에서는 게이트된 잔류 연결(21 ) 이 문제를 완화하기 위해. 그러나 업데이트 게이트 Φ는 더 많은 모델 매개변수를 도입하며 모델 크기가 70억으로 확장되면 불안정성 문제가 여전히 존재합니다. MEGALODON은 그림 3(c)와 같이 각 블록의 잔여 연결을 간단히 재배열하는 2홉 잔차가 있는 사전 표준이라는 새로운 구성을 도입합니다. 긴 컨텍스트 시퀀스 모델링에서 MEGALODON의 확장성과 효율성을 평가하기 위해 이 논문에서는 MEGALODON을 70억 규모로 확장합니다.
LLM 사전 훈련
데이터 효율성을 높이기 위해 연구원들은 그림 1과 같이 훈련 과정에서 MEGALODON-7B, LLAMA2-7B 및 LLAMA2-13B의 음의 로그 가능성(NLL)을 보여주었습니다.
동일한 수의 훈련 토큰으로 MEGALODON-7B는 LLAMA2-7B보다 훨씬 더 나은(낮은) NLL을 달성하여 더 나은 데이터 효율성을 보여주었습니다. 
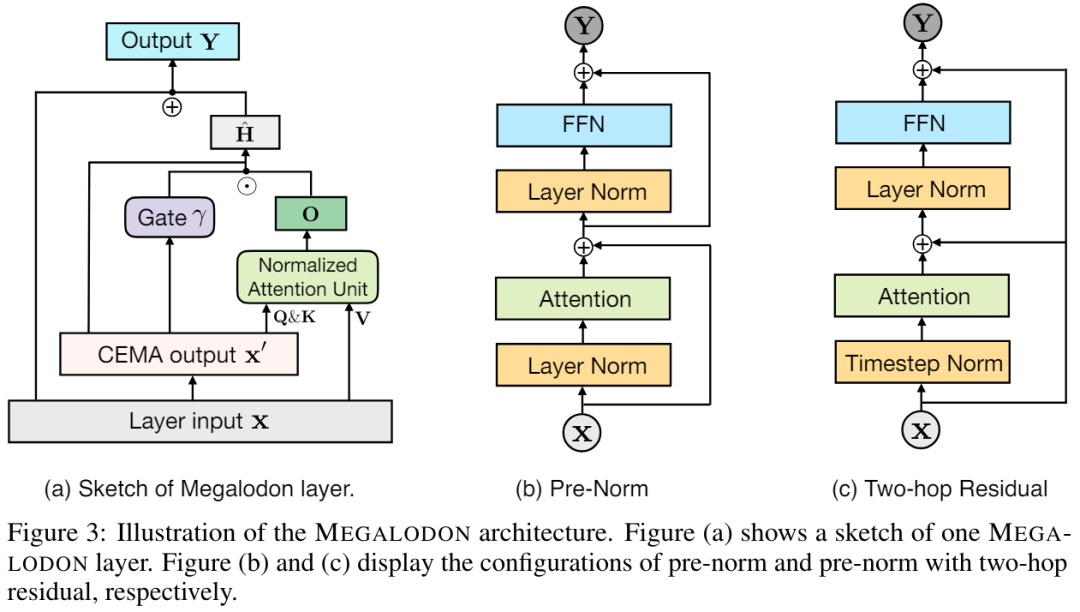
그림 4는 각각 4K 및 32K 컨텍스트 길이를 사용하는 LLAMA2-7B 및 MEGALODON-7B에 대한 장치당 평균 WPS(초당 단어/토큰)를 보여줍니다. LLAMA2 모델의 경우 연구에서는 Flash-Attention V2를 사용하여 전체 주의 계산을 가속화합니다. 4K 컨텍스트 길이에서 MEGALODON-7B는 CEMA 및 시간 단계 정규화 도입으로 인해 LLAMA2-7B보다 약간 느립니다(~6%). 컨텍스트 길이를 32K로 확장하면 MEGALODON-7B는 LLAMA2-7B(약 32%)보다 훨씬 빠르며, 이는 긴 컨텍스트 사전 학습에 대한 MEGALODON의 계산 효율성을 보여줍니다.
짧은 컨텍스트 평가
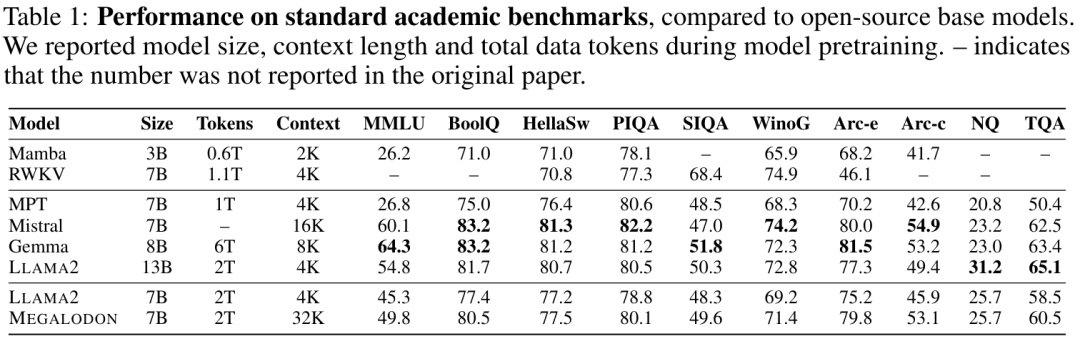
표 1에는 MEGALODON 및 LLAMA2의 학술 벤치마크 결과와 MPT, RWKV, Mamba, Mistral 및 Gemma를 포함한 다른 오픈 소스 기반 모델의 비교 결과가 요약되어 있습니다. 동일한 2T 토큰으로 사전 훈련한 후 MEGALODON-7B는 모든 벤치마크에서 LLAMA2-7B보다 성능이 뛰어납니다. 일부 작업에서는 MEGALODON-7B의 성능이 LLAMA2-13B의 성능과 비슷하거나 훨씬 더 좋습니다.
긴 컨텍스트 평가
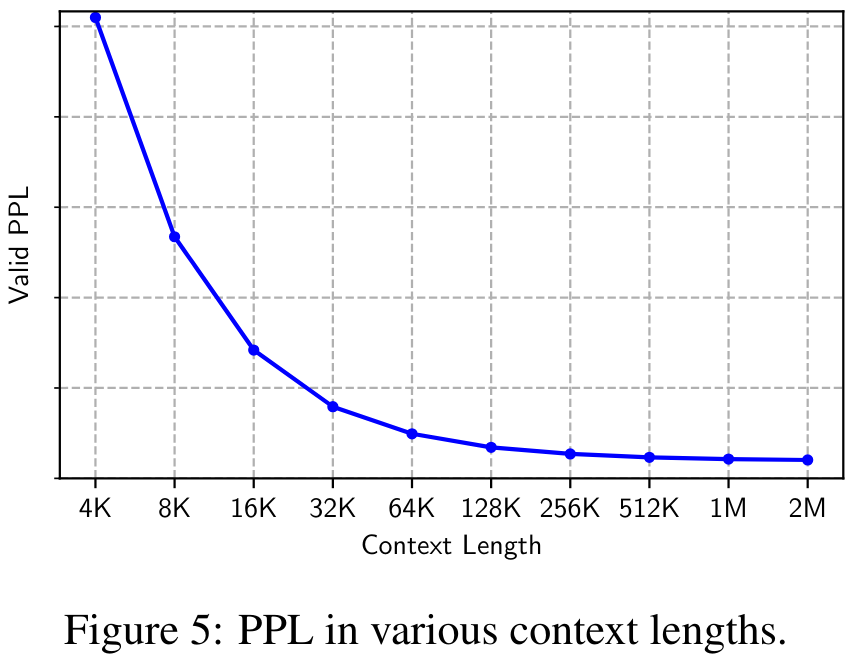
그림 5는 4K에서 2M까지 다양한 컨텍스트 길이에서 검증 데이터세트의 Perplexity(PPL)를 보여줍니다. PPL은 컨텍스트 길이에 따라 단조롭게 감소하여 매우 긴 시퀀스를 모델링할 때 MEGALODON의 효율성과 견고성을 검증하는 것을 볼 수 있습니다.
지시 미세 조정
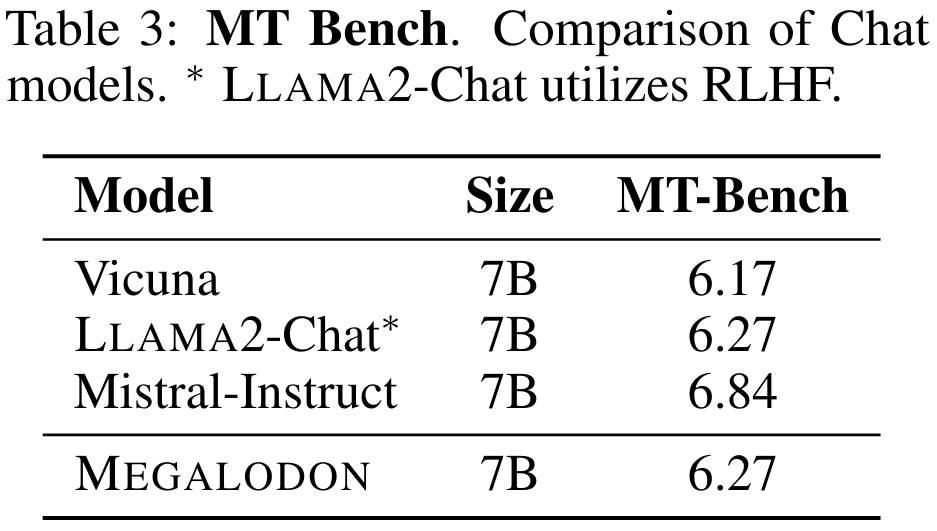
표 3은 MT-Bench에서 7B 모델의 성능을 요약한 것입니다. MEGALODON은 Vicuna에 비해 MT-Bench에서 우수한 성능을 보여주며 추가 정렬 미세 조정을 위해 RLHF를 활용하는 LLAMA2-Chat과 비슷합니다.
중규모 벤치마크 평가
이미지 분류 작업에 대한 MEGALODON의 성능을 평가하기 위해 연구에서는 Imagenet-1K 데이터 세트에 대한 실험을 수행했습니다. 표 4는 검증 세트의 Top-1 정확도를 보고합니다. MEGALODON의 정확도는 DeiT-B보다 1.3%, MEGA보다 0.8% 높습니다.
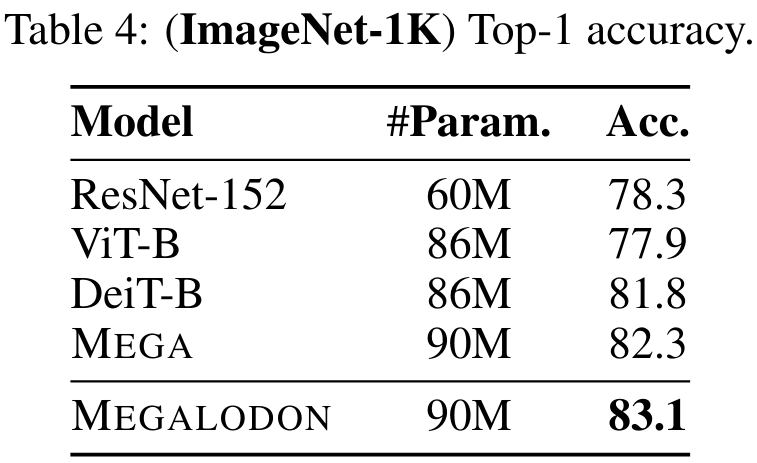
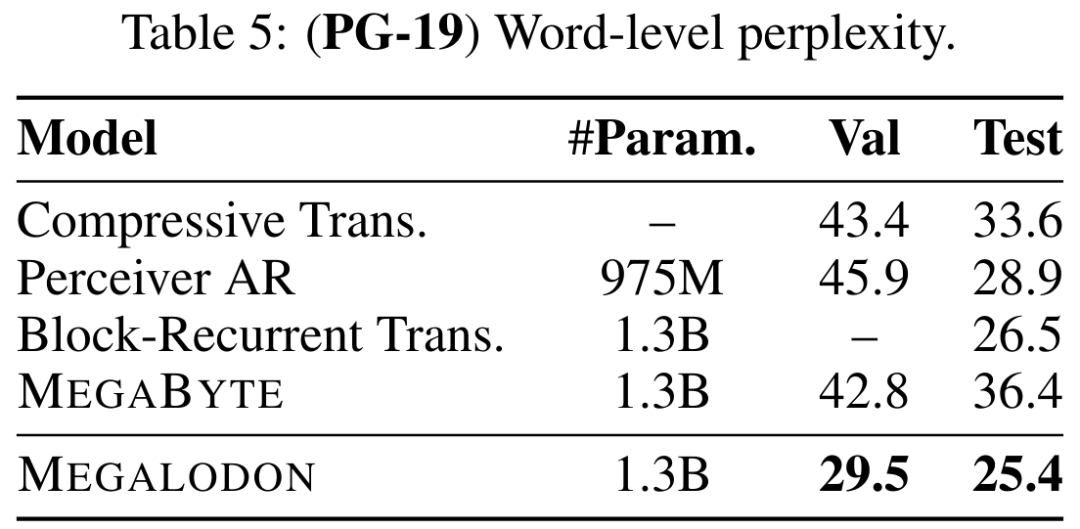
표 5는 PG-19에서 MEGALODON의 PPL(word-level perplexity)과 Compressive Transformer, Perceiver AR, Perceiver AR, Block Loop Transformer를 포함한 이전 최첨단 모델과의 비교를 보여줍니다. 그리고 MEGABYTE 등. MEGALODON의 성능은 분명히 앞서 있습니다.
자세한 내용은 원문을 참고해주세요.
위 내용은 메타 무제한 긴 텍스트 대형 모델은 여기에 있습니다: 7B 매개변수만, 오픈 소스의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



