


AIxiv 칼럼은 본 사이트에서 학술 및 기술 콘텐츠를 게재하는 칼럼입니다. 지난 몇 년 동안 이 사이트의 AIxiv 칼럼에는 전 세계 주요 대학 및 기업의 최고 연구실을 대상으로 한 2,000개 이상의 보고서가 접수되어 학술 교류 및 보급을 효과적으로 촉진하고 있습니다. 공유하고 싶은 훌륭한 작품이 있다면 자유롭게 기여하거나 보고를 위해 연락주시기 바랍니다. 제출 이메일: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com
국제 최고 수준의 GPT-4 128K와 Claude 200K부터 200만 단어 이상의 텍스트를 지원하는 국내 '레드 프라이드 치킨' 키미채팅까지, 긴 맥락에서 어김없이 대형 언어 모델(LLM)이 굴러왔습니다. 기술. 세상에서 가장 똑똑한 사람들이 어떤 일을 하고 있을 때, 그 문제의 중요성과 어려움은 자명합니다.
매우 긴 컨텍스트는 대형 모델의 생산성 가치를 크게 확장할 수 있습니다.AI의 인기로 인해 사용자는 더 이상 대형 모델을 가지고 놀거나 몇 가지 수수께끼를 푸는 데 만족하지 않고 진정한 생산성 향상을 위해 대형 모델을 사용하고 싶어하기 시작했습니다. 결국, 만드는 데 일주일이 걸렸던 PPT는 이제 대형 모델에 일련의 프롬프트 단어와 몇 가지 참조 문서만 제공하면 몇 분 만에 생성될 수 있습니다.
Lightning Attention(TransNormerLLM), State Space Modeling(Mamba), 선형 RNN(RWKV, HGRN, Griffin) 등과 같은 몇 가지 새로운 효율적인 시퀀스 모델링 방법이 최근 등장하여 뜨거운 연구 방향이 되었습니다. 연구원들은 이미 성숙한 7년 된 Transformer 아키텍처를 변형하여 성능은 비슷하지만 선형적 복잡성만 있는 새로운 아키텍처를 얻기를 열망하고 있습니다. 이러한 유형의 접근 방식은 모델 아키텍처 설계에 중점을 두고 CUDA 또는 Triton을 기반으로 하는 하드웨어 친화적인 구현을 제공하므로 FlashAttention과 같은 단일 카드 GPU 내에서 효율적으로 계산할 수 있습니다.
동시에 또 다른 긴 시퀀스 훈련 컨트롤러도 다른 전략을 채택했습니다. 즉, 시퀀스 병렬성이 점점 더 많은 관심을 받고 있습니다. 긴 시퀀스를 시퀀스 차원에서 균등하게 분할된 여러 개의 짧은 시퀀스로 나누고, 짧은 시퀀스를 서로 다른 GPU 카드에 분산하여 병렬 훈련을 하고, 카드 간 통신으로 보완함으로써 시퀀스 병렬 훈련의 효과를 얻습니다. 초기 Colossal-AI 시퀀스 병렬 처리부터 Megatron 시퀀스 병렬 처리, DeepSpeed Ulysses 및 최근 Ring Attention에 이르기까지 연구원들은 시퀀스 병렬 처리의 훈련 효율성을 향상시키기 위해 보다 우아하고 효율적인 통신 메커니즘을 계속 설계해 왔습니다. 물론 이러한 알려진 방법은 모두 이 기사에서 Softmax Attention이라고 부르는 전통적인 주의 메커니즘을 위해 설계되었습니다. 이러한 방법은 이미 다양한 전문가에 의해 분석되었으므로 이 기사에서는 이에 대해 자세히 논의하지 않습니다.

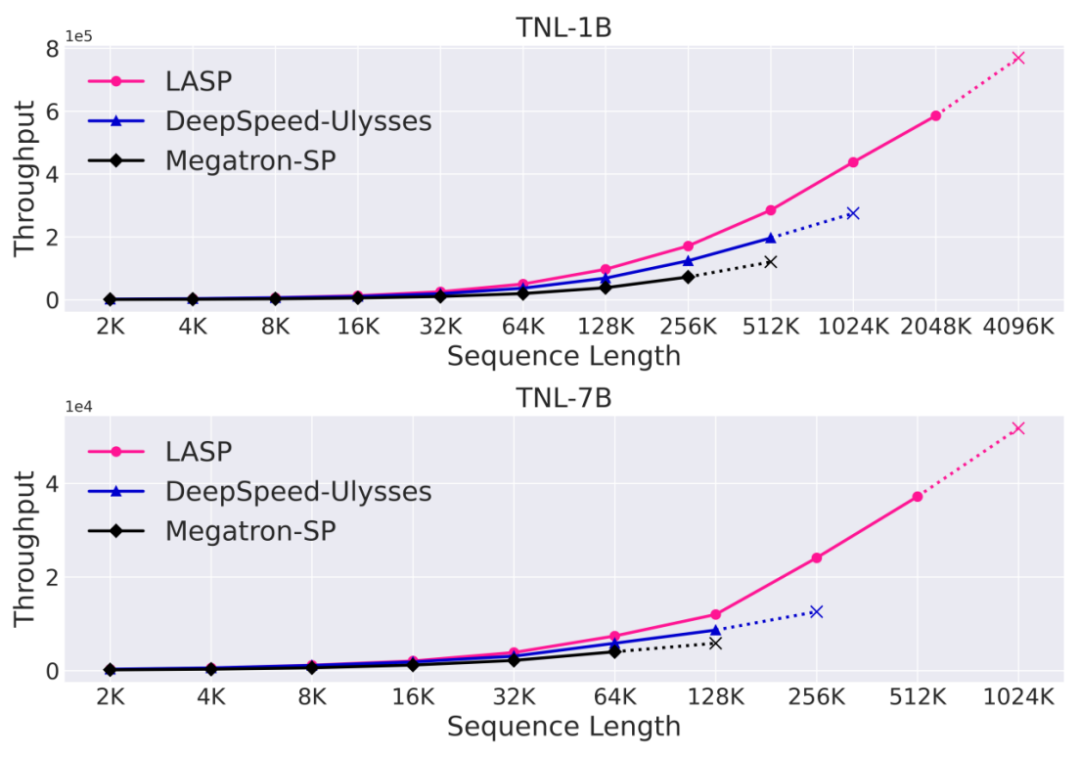
이 글에서 소개할 LASP가 탄생했습니다. 상하이 인공 지능 연구소(Shanghai Artificial Intelligence Laboratory)의 연구원들은 효율적인 시퀀스 병렬 컴퓨팅을 달성하기 위해 Linear Attention의 선형 오른쪽 곱셈 속성을 완전히 활용하는 LASP(Linear Attention Sequence Parallelism) 방법을 제안했습니다. 128카드 A100 80G GPU, TransNormerLLM 1B 모델 및 FSDP 백엔드 구성에서 LASP는 시퀀스 길이를 최대 4096K(4M)까지 확장할 수 있습니다. 성숙한 시퀀스 병렬 방법과 비교하여 LASP의 훈련 가능한 가장 긴 시퀀스 길이는 Megatron-SP의 8배, DeepSpeed Ulysses의 4배이며 속도는 각각 136% 및 38% 빠릅니다.
자연어 처리 방법의 이름에는 Linear Attention이 포함된다는 점에 유의해야 하지만, Linear Attention 방법에 국한되지 않고 Lightning Attention(TransNormerLLM), State Space Modeling(Mamba), 선형 RNN(RWKV, HGRN, Griffin) 및 기타 선형 시퀀스 모델링 방법.
LASP 방법 소개
LASP의 개념을 더 잘 이해하기 위해 먼저 Softmax의 전통적인 계산 공식을 검토해 보겠습니다. Attention: O=softmax((QK^T)⋅M)V, 여기서 Q, K, V, M, O 는 쿼리, 키, 값, 마스크 및 출력 행렬입니다. 여기서 M은 단방향 작업(예: GPT)에서 하삼각 all-1 행렬이고 양방향 작업(예: BERT)에서는 무시될 수 있습니다. , 양방향 작업을 위한 마스크 행렬이 없습니다. 아래 설명을 위해 LASP를 4가지 포인트로 나눕니다.
Linear Attention 원리
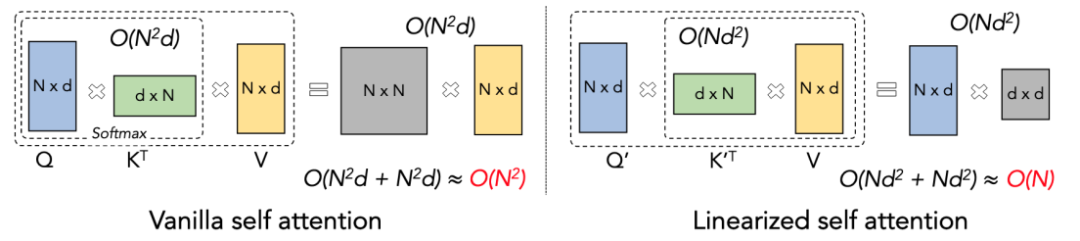
Linear Attention은 Softmax Attention의 변형으로 간주될 수 있습니다. Linear Attention은 계산 비용이 많이 드는 Softmax 연산자를 제거하고 Attention의 계산식은 O=((QK^T)⊙M) V의 간결한 형태로 작성할 수 있습니다. 그러나 단방향 작업에 마스크 행렬 M이 존재하기 때문에 이 형식은 여전히 왼쪽 곱셈 계산(즉, QK^T를 먼저 계산)만 수행할 수 있으므로 O(N)의 선형 복잡도를 얻을 수 없습니다. . 그러나 양방향 작업의 경우 마스크 행렬이 없으므로 계산 공식은 O=(QK^T) V로 더욱 단순화될 수 있습니다. Linear Attention의 독창성은 단순히 행렬 곱셈의 결합 법칙을 사용하여 계산 공식을 O=Q(K^T V)로 변환할 수 있다는 것입니다. 이 계산 형식을 선형 주의(Linear Attention)라고 볼 수 있습니다. 이 양방향 작업에서는 O(N) 복잡성을 달성할 수 있습니다!
LASP 데이터 배포
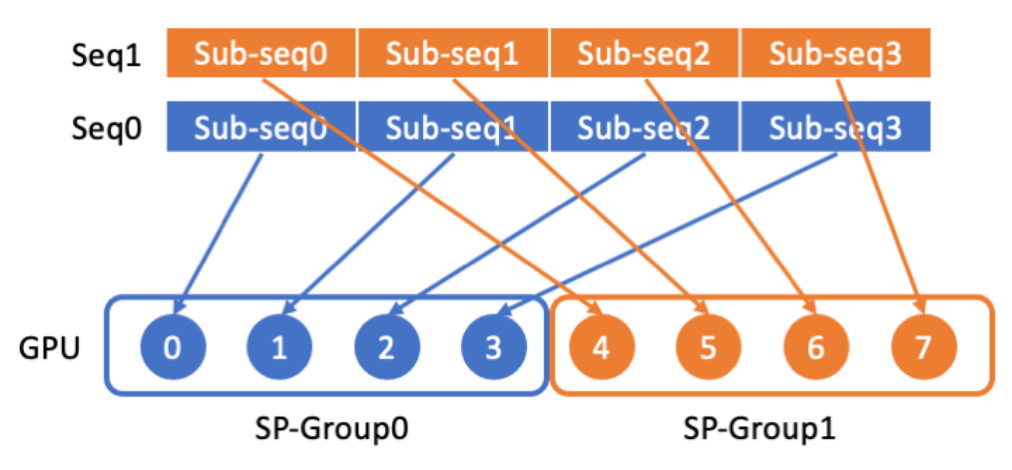
LASP는 먼저 긴 시퀀스 데이터를 시퀀스 차원에서 균등하게 분할된 여러 개의 하위 시퀀스로 나눈 다음 해당 하위 시퀀스를 시퀀스 병렬 통신 그룹의 모든 GPU에 보냅니다. 후속 시퀀스의 병렬 계산을 위한 하위 시퀀스.
LASP 핵심 메커니즘
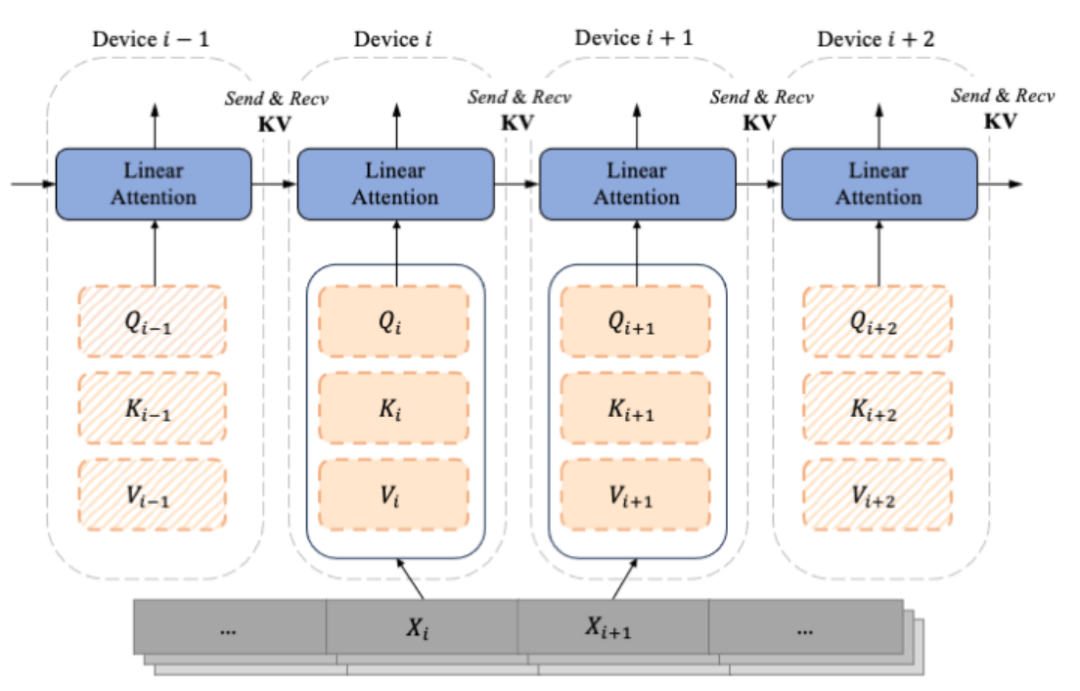
디코더 전용 GPT와 유사한 모델이 점차 LLM의 사실상 표준이 되면서 LASP는 단방향 캐주얼 작업 시나리오를 충분히 고려하여 설계되었습니다. 분할된 하위 시퀀스 Xi에서 계산된 것은 시퀀스 차원에 따라 분할된 Qi, Ki 및 Vi입니다. 각 인덱스 i는 청크 및 장치(즉, GPU)에 해당합니다. Mask 행렬의 존재로 인해 LASP 작성자는 각 Chunk에 해당하는 Qi, Ki 및 Vi를 Intra-Chunk와 Inter-Chunk의 두 가지 유형으로 교묘하게 구분합니다. 그 중 Intra-Chunk는 Mask 행렬이 블록으로 분할된 후 대각선에 있는 Chunk입니다. Mask 행렬이 여전히 존재하고 Inter-Chunk가 여전히 사용되어야 한다고 볼 수 있습니다. 마스크 행렬의 비대각선(마스크 행렬이 있으면 오른쪽 곱셈을 사용할 수 있음). 분명히 더 많은 청크를 나눌수록 대각선의 청크 비율이 작아집니다. 대각선을 벗어난 청크의 비율은 더 커집니다. Attention이 계산하는 청크가 많을수록 오른쪽 곱셈을 사용할 수 있습니다. 그중 오른쪽 곱해진 Inter-Chunk 계산을 위해 순방향 계산 중에 각 장치는 지점 간 통신을 사용하여 이전 장치의 KV를 수신하고 업데이트된 자체 KV를 다음 장치로 보내야 합니다. 역으로 계산할 경우 Send 및 Recive의 개체가 KV의 그래디언트 dKV가 된다는 점을 제외하면 정반대입니다. 순방향 계산 과정은 아래 그림과 같습니다.
LASP 코드 구현
GPU에서 LASP의 컴퓨팅 효율성을 향상시키기 위해 저자는 Intra-Chunk 및 Inter 계산에 Kernel Fusion을 수행했습니다. -Chunk 각각 KV 및 dKV의 업데이트 계산도 청크 내 및 청크 간 계산에 통합됩니다. 또한 역전파 중에 활성화 KV를 다시 계산하는 것을 피하기 위해 저자는 순전파 계산 직후 GPU의 HBM에 이를 저장하기로 결정했습니다. 후속 역전파 중에 LASP는 사용을 위해 KV에 직접 액세스합니다. HBM에 저장된 KV 크기는 d x d이며 시퀀스 길이 N의 영향을 전혀 받지 않습니다. 입력 시퀀스 길이 N이 크면 KV의 메모리 공간은 중요하지 않게 됩니다. 단일 GPU 내에서 저자는 Triton으로 구현된 Lightning Attention을 구현하여 HBM과 SRAM 간의 IO 오버헤드를 줄여 단일 카드 Linear Attention 계산을 가속화했습니다.
자세한 내용을 알고 싶은 독자들은 논문의 알고리즘 2(LASP 전진 과정)와 알고리즘 3(LASP 역진행)과 논문의 자세한 도출 과정을 읽어보실 수 있습니다.
트래픽 분석
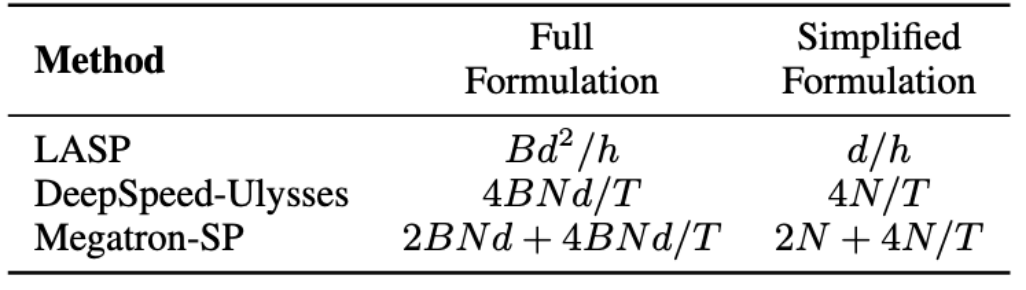
LASP 알고리즘에서 순방향 전파에는 각 Linear Attention 모듈 계층에서 KV 활성화 통신이 필요하다는 점에 유의해야 합니다. 트래픽은 Bd^2/h입니다. 여기서 B는 배치 크기이고 h는 헤드 수입니다. 이에 비해 Megatron-SP는 각 Transformer 레이어의 두 Layer Norm 레이어 이후에 All-Gather 작업을 사용하고 Attention 및 FFN 레이어 이후에 Reduce-Scatter 작업을 사용하므로 통신이 발생합니다. 수량은 2BNd + 4BNd/T입니다. T는 시퀀스 병렬 차원입니다. DeepSpeed-Ulysses는 All-to-All 설정된 통신 작업을 사용하여 각 Attention 모듈 계층의 입력 Q, K, V 및 출력 O를 처리하여 4BNd/T의 통신 볼륨을 생성합니다. 세 곳의 통신량 비교는 아래 표와 같습니다. 여기서 d/h는 머리 치수이며 일반적으로 128로 설정됩니다. 실제 적용에서 LASP는 N/T>=32일 때 가장 낮은 이론적 통신량을 달성할 수 있습니다. 또한 LASP의 통신량은 시퀀스 길이 N 또는 하위 시퀀스 길이 C의 영향을 받지 않습니다. 이는 대규모 GPU 클러스터에서 매우 긴 시퀀스의 병렬 컴퓨팅에 큰 이점입니다.
데이터 시퀀스 하이브리드 병렬
데이터 병렬 처리(즉, 배치 수준 데이터 분할)는 분산 교육을 위한 일상적인 작업이었습니다. 이는 원래 데이터 병렬 처리(PyTorch DDP)를 기반으로 발전했습니다. 원래 DeepSpeed ZeRO 시리즈부터 PyTorch에서 공식적으로 지원하는 FSDP에 이르기까지 더 많은 메모리 절약형 슬라이스 데이터 병렬성을 달성하기 위해 슬라이스 데이터 병렬성은 충분히 성숙해졌으며 점점 더 많은 사용자가 사용하고 있습니다. LASP는 시퀀스 수준 데이터 분할 방법으로 PyTorch DDP, Zero-1/2/3, FSDP를 포함한 다양한 데이터 병렬 방법과 호환됩니다. 이는 LASP 사용자에게는 의심할 여지 없이 좋은 소식입니다.
정확도 실험
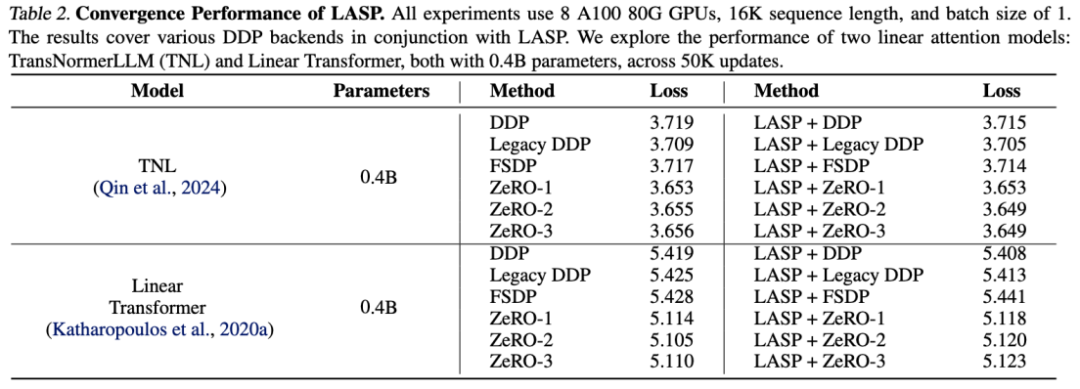
TransNormerLLM(TNL) 및 Linear Transformer에 대한 실험 결과는 시스템 최적화 방법인 LASP가 다양한 DDP 백엔드와 결합되어 Baseline과 동등한 성능을 달성할 수 있음을 보여줍니다.
확장성 실험
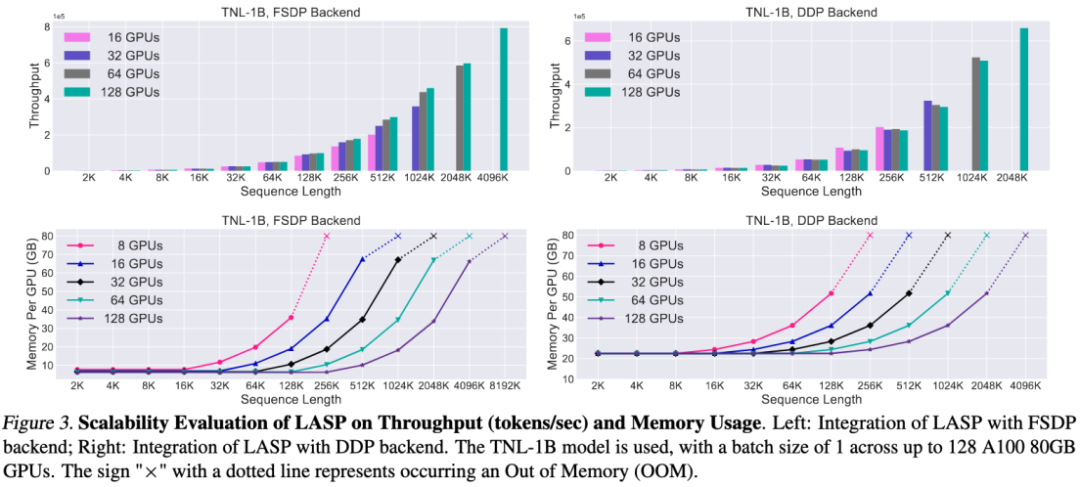
LASP는 효율적인 통신 메커니즘 설계 덕분에 수백 개의 GPU 카드까지 쉽게 확장할 수 있으며 좋은 확장성을 유지합니다.
속도 비교 실험
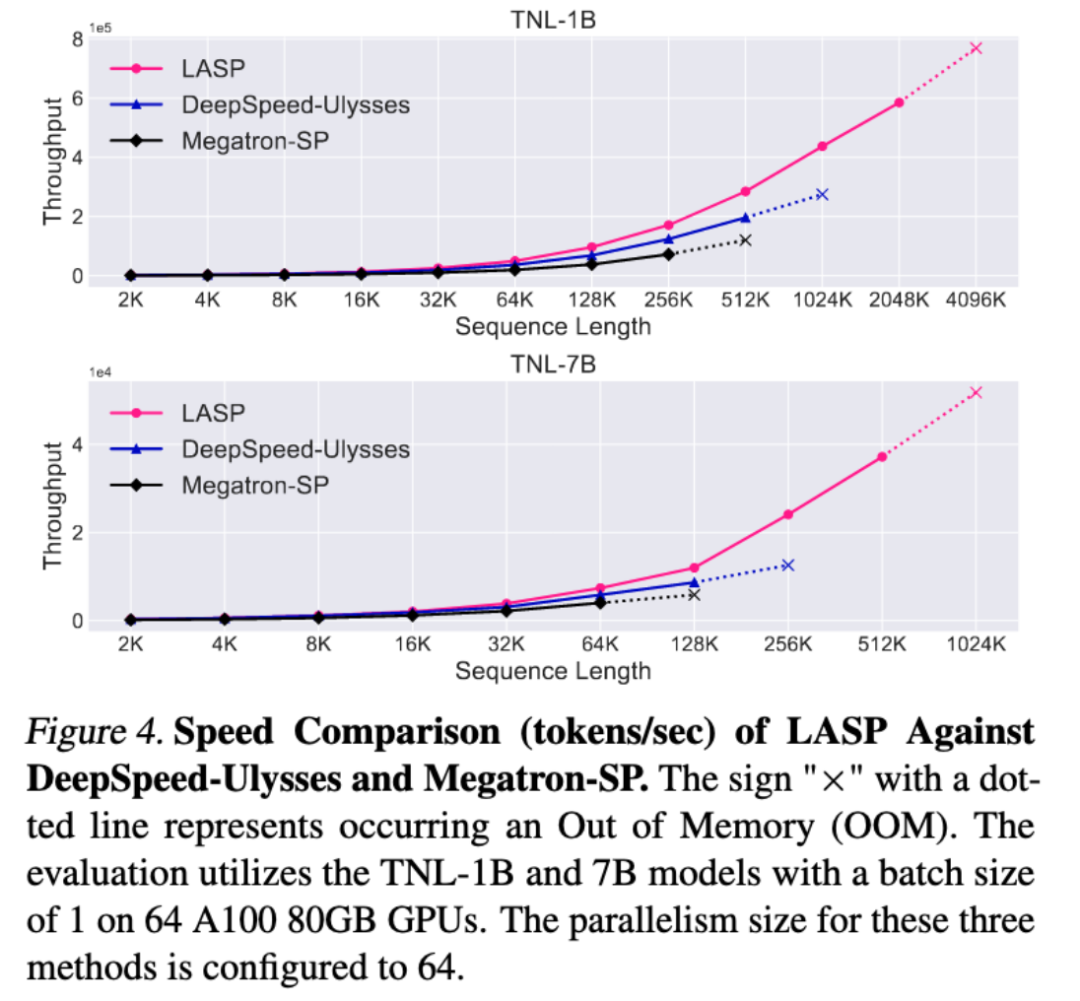
성숙한 시퀀스 병렬 방법인 Megatron-SP 및 DeepSpeed-Ulysses와 비교했을 때, LASP의 훈련 가능한 가장 긴 시퀀스 길이는 Megatron-SP의 8배, DeepSpeed-의 4배입니다. Ulysses의 속도는 각각 136%, 38% 더 빠릅니다.
결론
저자는 바로 사용할 수 있는 LASP 코드 구현을 제공했습니다. LASP를 경험하려면 PyTorch만 있으면 됩니다. 몇 분 만에 매우 빠른 시퀀스 병렬 처리가 가능합니다.
코드 포털: https://github.com/OpenNLPLab/LASP
위 내용은 매우 긴 시퀀스, 매우 빠른 속도: 차세대 효율적인 대규모 언어 모델을 위한 LASP 시퀀스 병렬 처리의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



