

언어 모델은 일반적으로 문자열 형식인 텍스트에 대해 추론하지만 모델에 대한 입력은 숫자만 가능하므로 텍스트를 숫자 형식으로 변환해야 합니다.
토큰화는 자연어 처리의 기본 작업입니다. 연속된 텍스트 시퀀스(예: 문장, 단락 등)를 특정 내용에 따라 문자 시퀀스(예: 단어, 구, 문자, 구두점 등)로 나눌 수 있습니다. 그 중 단위를 토큰(token) 또는 워드(word)라고 합니다.
아래 그림에 표시된 특정 프로세스에 따라 먼저 텍스트 문장을 단위로 나눈 다음 단일 요소를 디지털화(벡터로 매핑)한 다음 이러한 벡터를 인코딩 모델에 입력하고 마지막으로 다운스트림 작업에 출력합니다. 최종 결과를 더 얻으려면.
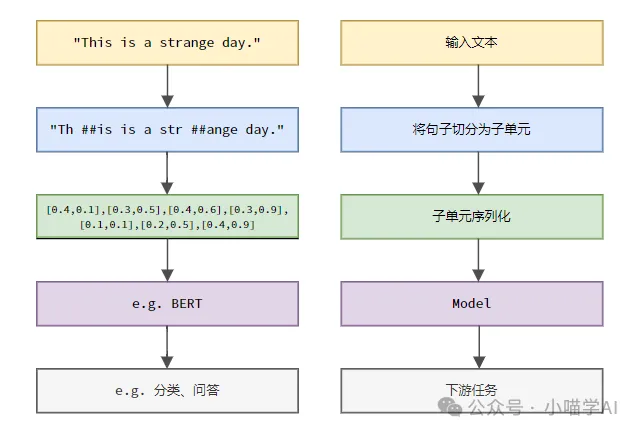
텍스트 세분화에 따라 토큰화는 단어 세분화 토큰화, 문자 세분화 토큰화, 하위 단어 세분화 토큰화의 세 가지 범주로 나눌 수 있습니다.
단어 세분성 토큰화는 가장 직관적인 단어 분할 방법으로, 단어에 따라 텍스트를 분할하는 것을 의미합니다. 예:
The quick brown fox jumps over the lazy dog.词粒度Tokenized结果:['The', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog', '.']
이 예에서는 텍스트가 독립된 단어로 구분되고 각 단어가 토큰으로 사용되며 구두점 '.'도 독립된 토큰으로 간주됩니다.
중국어 텍스트는 일반적으로 단어 분할 알고리즘을 통해 식별된 사전이나 구문, 관용어, 고유 명사 등에서 수집된 표준 어휘 모음을 기반으로 분할됩니다.
我喜欢吃苹果。词粒度Tokenized结果:['我', '喜欢', '吃', '苹果', '。']
이 중국어 텍스트는 "I", "like", "eat", "apple" 및 마침표 "."의 다섯 단어로 구분되며 각 단어는 토큰 역할을 합니다.
문자 세분화 토큰화는 텍스트를 가장 작은 문자 단위로 나눕니다. 즉, 각 문자는 별도의 토큰으로 처리됩니다. 예:
Hello, world!字符粒度Tokenized结果:['H', 'e', 'l', 'l', 'o', ',', ' ', 'w', 'o', 'r', 'l', 'd', '!']
문자 세분성 중국어의 토큰화는 각각의 독립적인 한자에 따라 텍스트를 분할하는 것입니다.
我喜欢吃苹果。字符粒度Tokenized结果:['我', '喜', '欢', '吃', '苹', '果', '。']
subword granular 토큰화는 단어 세분성과 문자 세분성 사이에서 텍스트를 단어와 문자 사이의 하위 단어(하위 단어)로 토큰으로 나눕니다. 일반적인 하위 단어 토큰화 방법에는 BPE(바이트 쌍 인코딩), WordPiece 등이 포함됩니다. 이러한 방법은 텍스트 데이터의 하위 문자열 빈도를 계산하여 단어 분할 사전을 자동으로 생성합니다. 이는 특정 의미 무결성을 유지하면서 서비스 불가능한 단어(OOV) 문제를 효과적으로 처리할 수 있습니다.
helloworld
BPE 알고리즘으로 훈련한 후 생성된 하위 단어 사전에 다음 항목이 포함되어 있다고 가정합니다.
h, e, l, o, w, r, d, hel, low, wor, orld
하위 단어 세분성 토큰화된 결과:
['hel', 'low', 'orld']
여기서 "helloworld"는 세 개의 하위 단어로 나뉩니다." " hel", "low", "orld"는 모두 사전에 나타나는 빈도가 높은 하위 문자열 조합입니다. 이 분할 방법은 알려지지 않은 단어(예: "helloworld"는 표준 영어 단어가 아님)를 처리할 수 있을 뿐만 아니라 특정 의미 정보(하위 단어의 조합으로 원래 단어를 복원할 수 있음)도 유지할 수 있습니다.
중국어의 경우 하위 단어 세분화 토큰화는 텍스트를 한자 사이의 하위 단어와 토큰으로 단어로 나누기도 합니다. 예:
我喜欢吃苹果
BPE 알고리즘으로 교육한 후 생성된 하위 단어 사전에 다음 항목이 포함되어 있다고 가정합니다.
我, 喜, 欢, 吃, 苹, 果, 我喜欢, 吃苹果
하위 단어 세분성 토큰화된 결과:
['我', '喜欢', '吃', '苹果']
이 예에서는 "I like to eat" 사과'는 '나', '좋아요', '먹다', '사과' 등 4개의 하위 단어로 나뉘며, 이 하위 단어는 모두 사전에 등재된다. 한자는 더 이상 영어 하위 단어처럼 결합하지 않지만, 하위 단어 토큰화 방식은 사전 생성 시 "좋아요", "사과 먹기" 등 빈도가 높은 단어 조합을 고려했습니다. 이 분할 방법은 알려지지 않은 단어를 처리하는 동안 단어 수준의 의미 정보를 유지합니다.
코퍼스나 어휘가 다음과 같이 생성되었다고 가정합니다.
vocabulary = {'我': 0,'喜欢': 1,'吃': 2,'苹果': 3,'。': 4}어휘의 순서에 있는 각 토큰의 인덱스를 찾을 수 있습니다.
indexed_tokens = [vocabulary[token] for token in token_sequence]print(indexed_tokens)
출력: [0, 1, 2, 3, 4].
위 내용은 하나의 기사로 토큰화를 이해해보세요!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



