

대형 모델을 구현하는 과정에서 엔드사이드 AI는 매우 중요한 방향입니다.
최근 스탠포드 대학 연구진이 출시한 Octopus v2가 인기를 끌며 개발자 커뮤니티로부터 큰 주목을 받았습니다. 해당 모델의 다운로드 수가 하룻밤 사이에 2,000건을 넘었습니다.
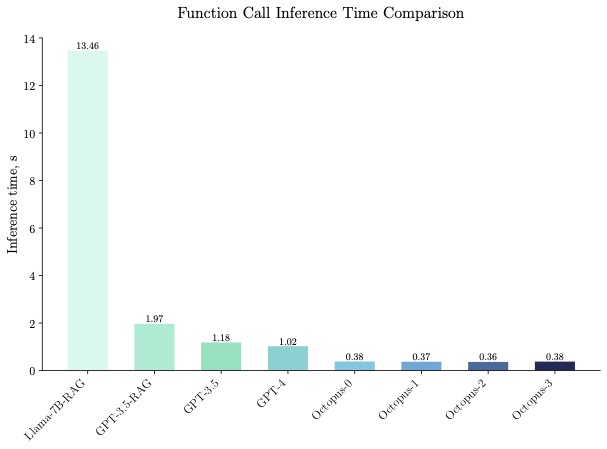
20억 개의 매개변수 Octopus v2는 스마트폰, 자동차, PC 등에서 실행될 수 있으며 정확도와 대기 시간이 GPT-4를 능가하고 컨텍스트 길이를 95% 줄입니다. 또한 Octopus v2는 Llama7B + RAG 방식보다 36배 빠릅니다. 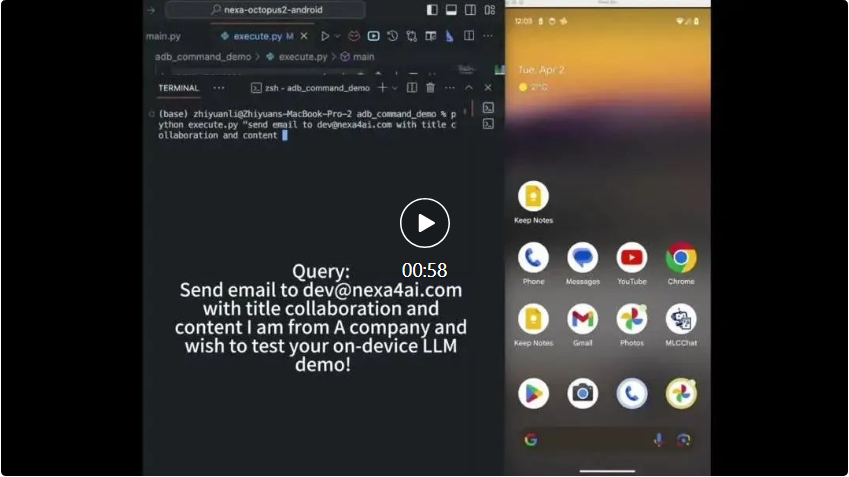

Paper: Octopus v2: 슈퍼 에이전트를 위한 온디바이스 언어 모델
Paper 주소: https://arxiv.org/abs/2404.01744
모델 홈페이지: https://huggingface .co/NexaAIDev/Octopus-v2
모델 개요
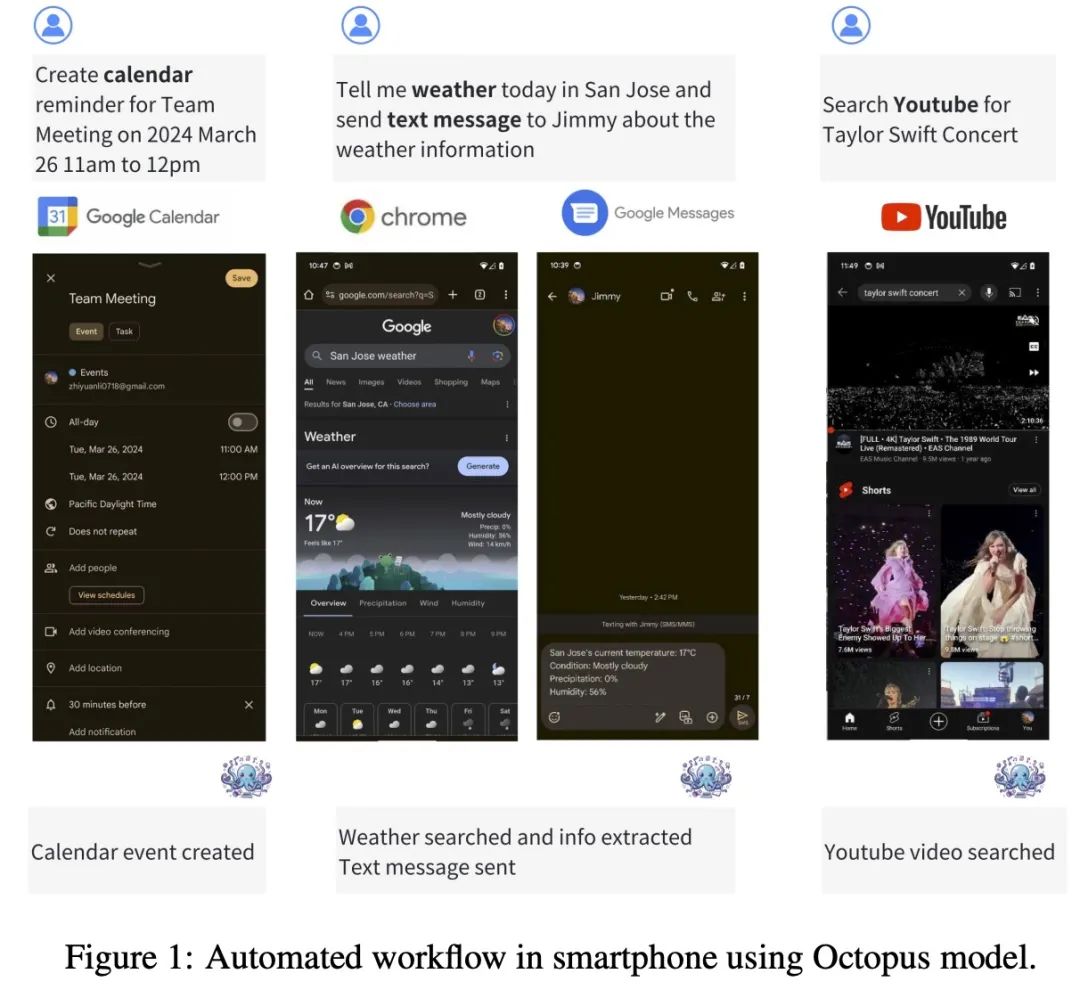
Octopus-V2-2B+는 Android API에 맞춰진 20억 개의 매개변수를 갖춘 오픈 소스 언어 모델입니다. Android 기기에서 원활하게 실행되며 Android 시스템 관리부터 여러 기기의 오케스트레이션에 이르기까지 다양한 애플리케이션으로 유틸리티를 확장합니다.
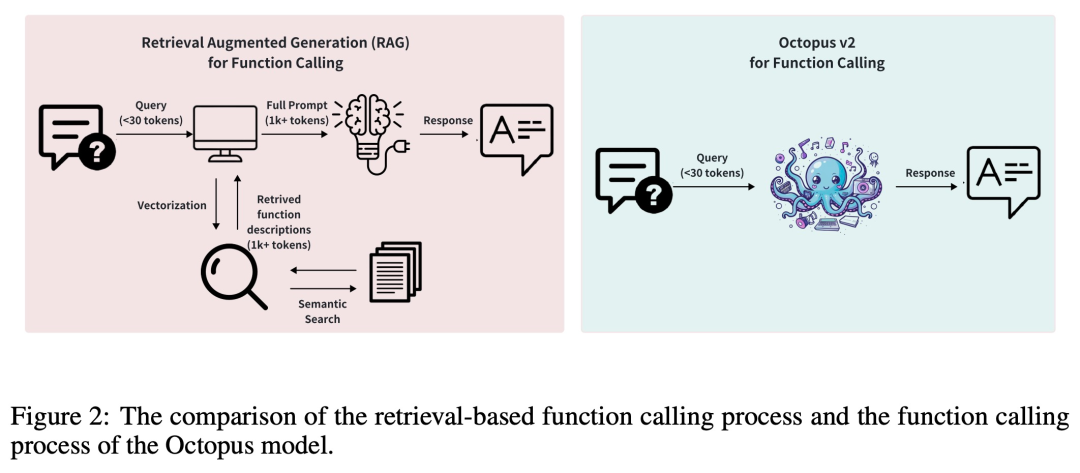
일반적으로 RAG(검색 증강 생성) 방법에는 잠재적인 함수 매개변수에 대한 자세한 설명이 필요합니다(때로는 최대 수만 개의 입력 토큰이 필요함). 이를 기반으로 Octopus-V2-2B는 훈련 및 추론 단계에서 고유한 기능 토큰 전략을 도입하여 GPT-4에 필적하는 성능 수준을 달성할 수 있을 뿐만 아니라 추론 속도를 크게 향상시켜 RAG 기반을 능가합니다. 이는 엣지 컴퓨팅 장치에 특히 유용합니다.
Octopus-V2-2B는 다양하고 복잡한 시나리오에서 개별, 중첩 및 병렬 함수 호출을 생성할 수 있습니다.
Dataset
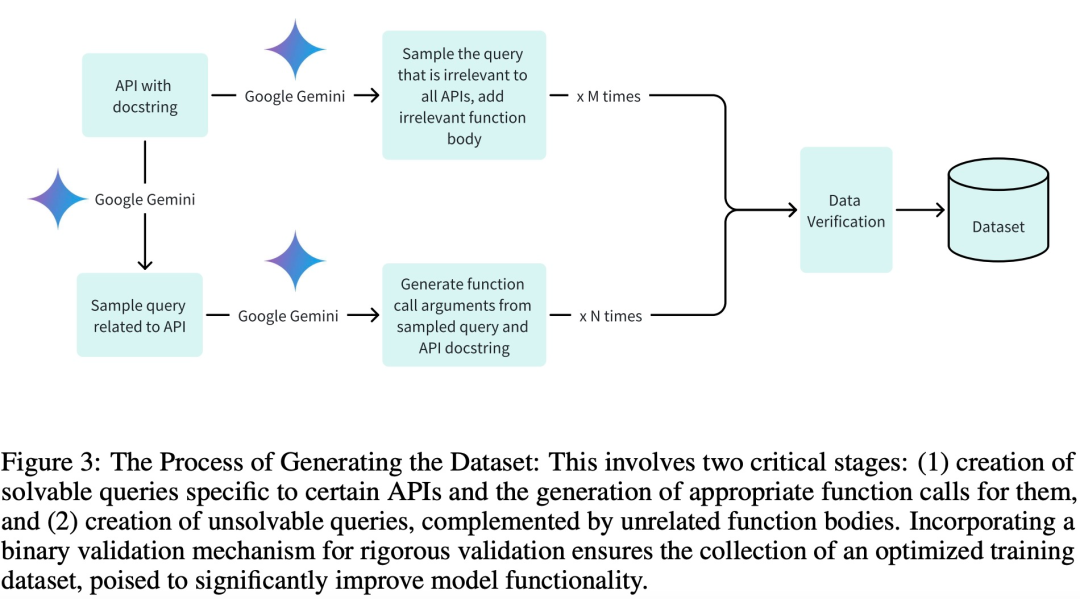
훈련, 검증 및 테스트 단계에 고품질 데이터 세트를 채택하고 특히 효율적인 훈련을 달성하기 위해 연구팀은 세 가지 주요 단계로 데이터 세트를 만들었습니다.
관련 쿼리 생성 및 관련 함수 호출 인수
적절한 함수 구성요소에 의한 관련 없는 쿼리 생성
Google Gemini를 통한 바이너리 검증 지원.
연구팀은 훈련 모델을 위한 20개의 Android API 설명을 작성했습니다. 다음은 Android API 설명의 예입니다.
def get_trending_news (category=None, region='US', language='en', max_results=5):"""Fetches trending news articles based on category, region, and language.Parameters:- category (str, optional): News category to filter by, by default use None for all categories. Optional to provide.- region (str, optional): ISO 3166-1 alpha-2 country code for region-specific news, by default, uses 'US'. Optional to provide.- language (str, optional): ISO 639-1 language code for article language, by default uses 'en'. Optional to provide.- max_results (int, optional): Maximum number of articles to return, by default, uses 5. Optional to provide.Returns:- list [str]: A list of strings, each representing an article. Each string contains the article's heading and URL. """
모델 개발 및 훈련
이 연구에서는 Google Gemma-2B 모델을 프레임워크의 사전 훈련된 모델로 사용하고 두 가지 다른 훈련 방법인 전체 모델 훈련을 채택합니다. LoRA 모델 훈련.
전체 모델 훈련에서 본 연구에서는 AdamW 최적화 프로그램을 사용하고, 학습률은 5e-5로 설정하고, 준비 단계 수는 10으로 설정하고, 선형 학습률 스케줄러를 사용했습니다.
LoRA 모델 훈련은 전체 모델 훈련과 동일한 옵티마이저 및 학습률 구성을 사용하며 LoRA 순위는 16으로 설정되고 LoRA는 q_proj, k_proj, v_proj, o_proj, up_proj, down_proj 모듈에 적용됩니다. 그 중 LoRA 알파 매개변수는 32로 설정되어 있다.
두 훈련 방법 모두 Epoch 수는 3으로 설정됩니다.
다음 코드를 사용하여 단일 GPU에서 Octopus-V2-2B 모델을 실행하세요.
from transformers import AutoTokenizer, GemmaForCausalLMimport torchimport timedef inference (input_text):start_time = time.time ()input_ids = tokenizer (input_text, return_tensors="pt").to (model.device)input_length = input_ids ["input_ids"].shape [1]outputs = model.generate (input_ids=input_ids ["input_ids"], max_length=1024,do_sample=False)generated_sequence = outputs [:, input_length:].tolist ()res = tokenizer.decode (generated_sequence [0])end_time = time.time ()return {"output": res, "latency": end_time - start_time}model_id = "NexaAIDev/Octopus-v2"tokenizer = AutoTokenizer.from_pretrained (model_id)model = GemmaForCausalLM.from_pretrained (model_id, torch_dtype=torch.bfloat16, device_map="auto")input_text = "Take a selfie for me with front camera"nexa_query = f"Below is the query from the users, please call the correct function and generate the parameters to call the function.\n\nQuery: {input_text} \n\nResponse:"start_time = time.time () print ("nexa model result:\n", inference (nexa_query)) print ("latency:", time.time () - start_time,"s")평가
Octopus-V2-2B는 벤치마크 테스트에서 단일 A100 GPU의 "Llama7B + RAG 솔루션"보다 36배 빠른 뛰어난 추론 속도를 보여주었습니다. 또한 Octopus-V2-2B는 클러스터링된 A100/H100 GPU를 사용하는 GPT-4-turbo에 비해 168% 더 빠릅니다. 이러한 효율성 혁신은 Octopus-V2-2B의 기능적 토큰 설계에 기인합니다.
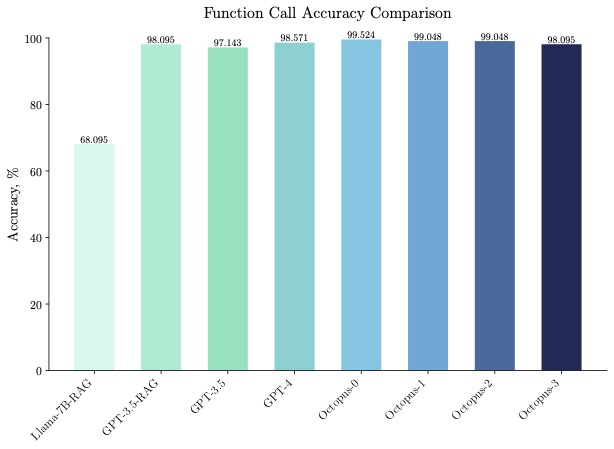
Octopus-V2-2B는 속도뿐만 아니라 정확도에서도 뛰어난 성능을 발휘하여 함수 호출 정확도에서 "Llama7B + RAG 솔루션"을 31% 능가합니다. Octopus-V2-2B는 GPT-4 및 RAG + GPT-3.5에 필적하는 함수 호출 정확도를 달성합니다.
관심 있는 독자는 논문 원문을 읽고 연구 내용에 대해 자세히 알아볼 수 있습니다.
위 내용은 GPT-4를 넘어 휴대전화에서 실행할 수 있는 스탠포드팀의 대형 모델이 인기를 끌면서 하루아침에 2,000건이 넘는 다운로드를 기록했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



