

대형모델의 환상이 드디어 끝난다구요?
오늘 소셜미디어 플랫폼 레딧(Reddit)에는 한 게시물이 네티즌들 사이에서 열띤 토론을 불러일으켰습니다. 이 게시물은 어제 Google DeepMind가 제출한 논문 "Long-form Factuality in Large Language Models"에 대해 논의한 것입니다. 기사에서 제안된 방법과 결과는 사람들로 하여금 대규모 언어 모델의 환상이 더 이상 문제가 되지 않는다는 결론을 내리게 했습니다.

우리는 대규모 언어 모델이 공개 주제에 대한 사실 탐구 질문에 응답할 때 사실 오류가 포함된 콘텐츠를 생성하는 경우가 많다는 것을 알고 있습니다. DeepMind는 이 현상에 대해 몇 가지 탐색적 연구를 수행했습니다.
공개 도메인에서 모델의 긴 사실성을 벤치마킹하기 위해 연구원들은 GPT-4를 사용하여 38개 주제와 수천 개의 질문이 포함된 프롬프트 세트인 LongFact를 생성했습니다. 그런 다음 SAFE(Search Augmented Fact Evaluator)를 사용하여 LLM 에이전트를 긴 형식 사실의 자동 평가기로 사용할 것을 제안했습니다. SAFE의 목적은 사실적 신뢰성 평가자의 정확성을 향상시키는 것입니다.
SAFE에 관해서는 LLM을 사용하면 각 인스턴스의 정확도를 더 정확하게 설명할 수 있습니다. 이 다단계 추론 프로세스에는 Google 검색에 검색어를 보내고 검색 결과가 특정 인스턴스를 지원하는지 여부를 결정하는 작업이 포함됩니다.

문서 주소: https://arxiv.org/pdf/2403.18802.pdf
GitHub 주소: https://github.com/google-deepmind/long-form-factuality
또한 연구원들은 F1 점수(F1@K)를 긴 형식의 실용적인 집계 지표로 확장할 것을 제안했습니다. 응답에서 지원되는 사실의 비율(정밀도)과 사용자가 선호하는 응답 길이(재현율)를 나타내는 하이퍼 매개변수와 관련하여 제공된 사실의 비율의 균형을 맞춥니다.
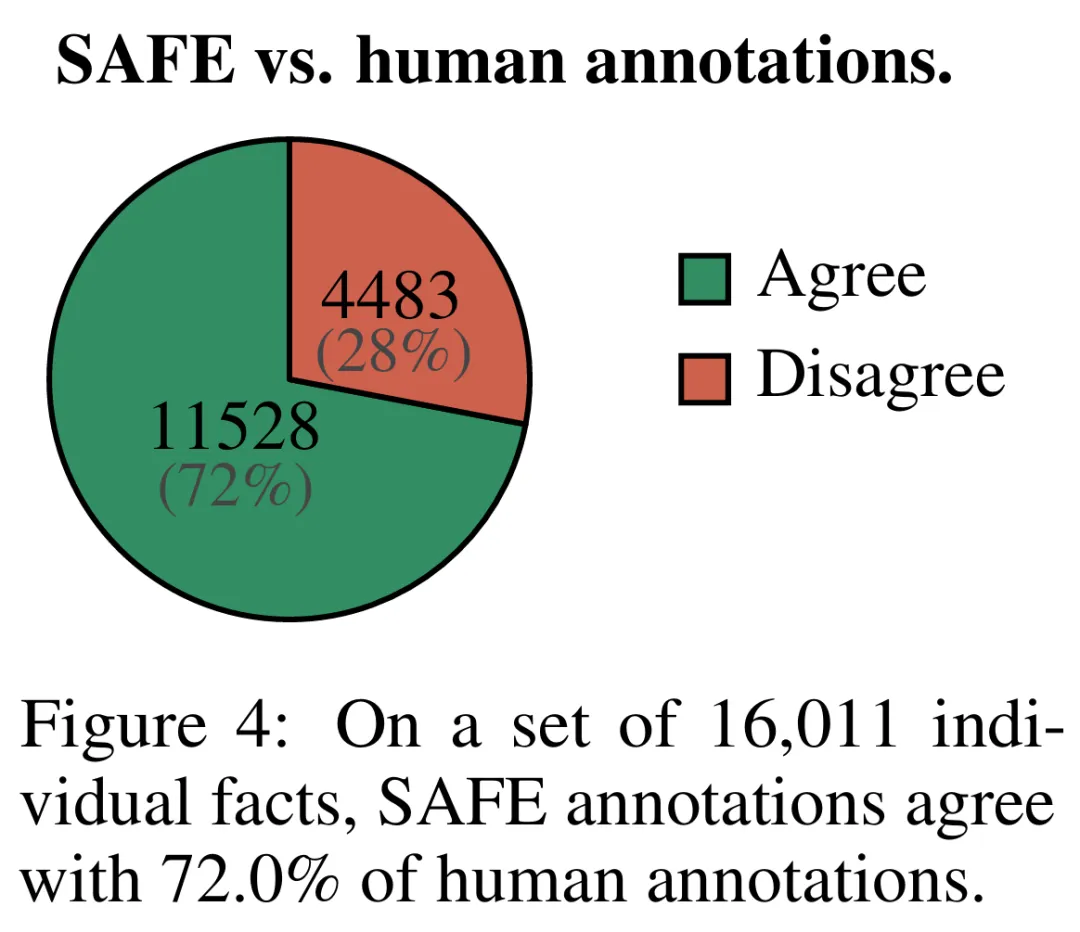
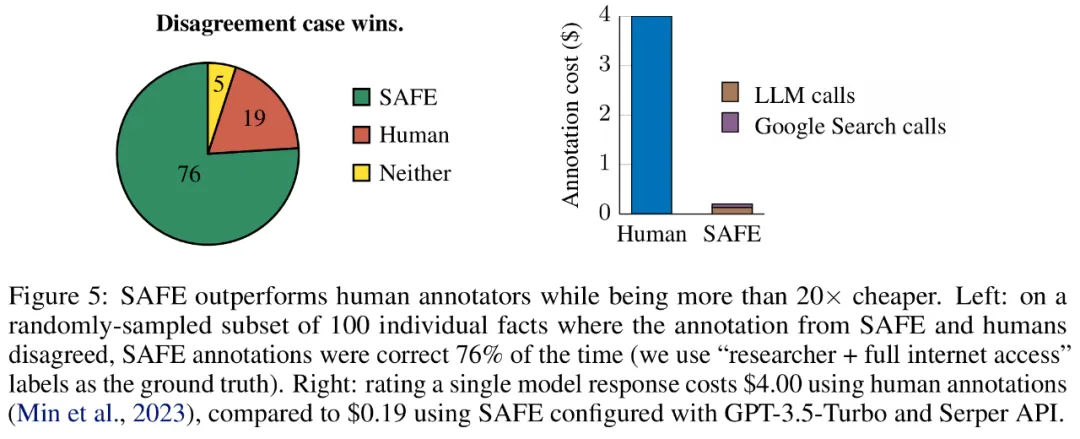
실증적 결과에 따르면 LLM 에이전트는 인간을 능가하는 평가 성과를 달성할 수 있습니다. 최대 16,000개의 개별 팩트에 대해 SAFE는 72%의 시간 동안 사람 주석 작성자와 동의했으며, 100개의 불일치 사례의 무작위 하위 집합에서 SAFE는 76%의 승률을 달성했습니다. 동시에 SAFE는 인간 주석자보다 20배 이상 저렴합니다.
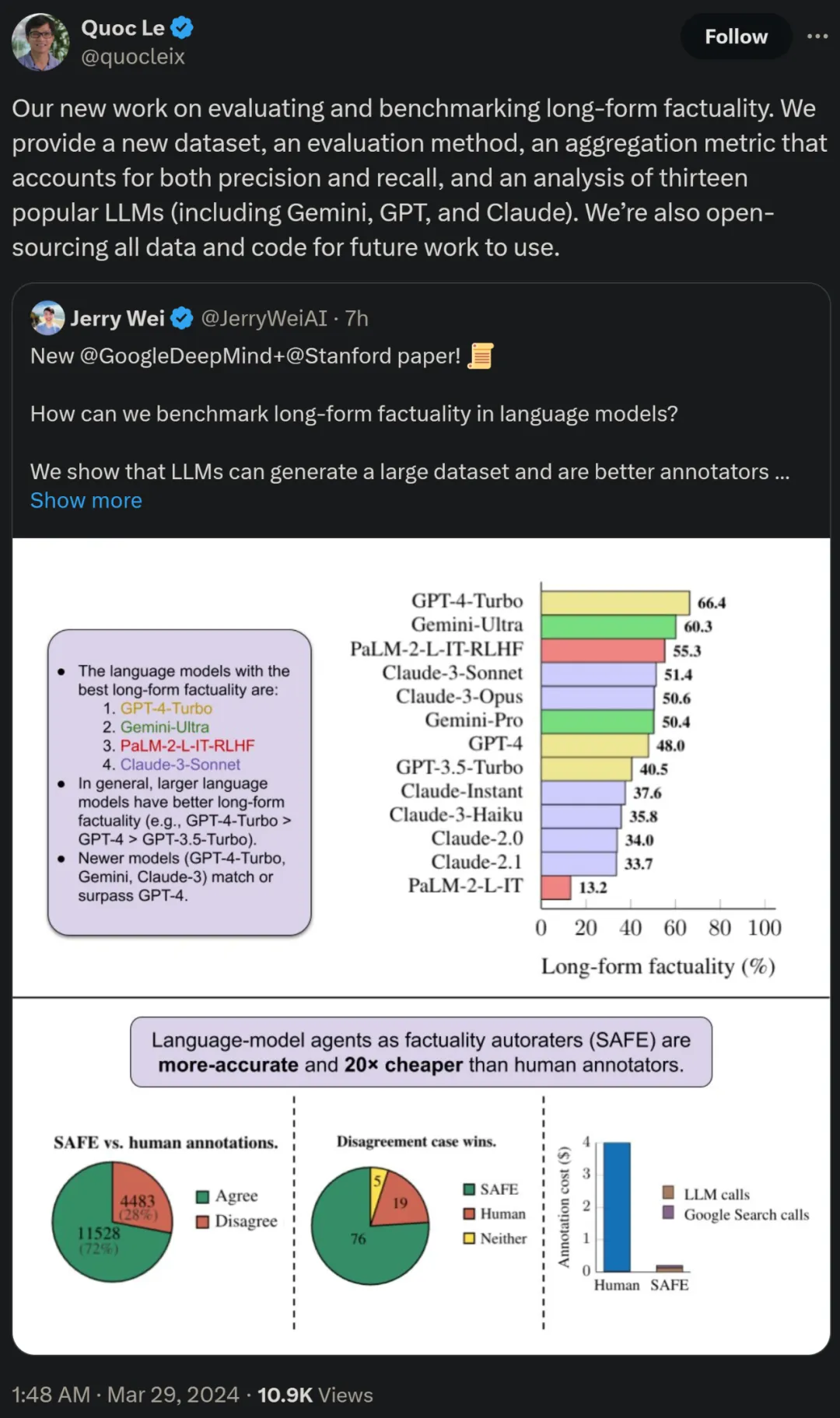
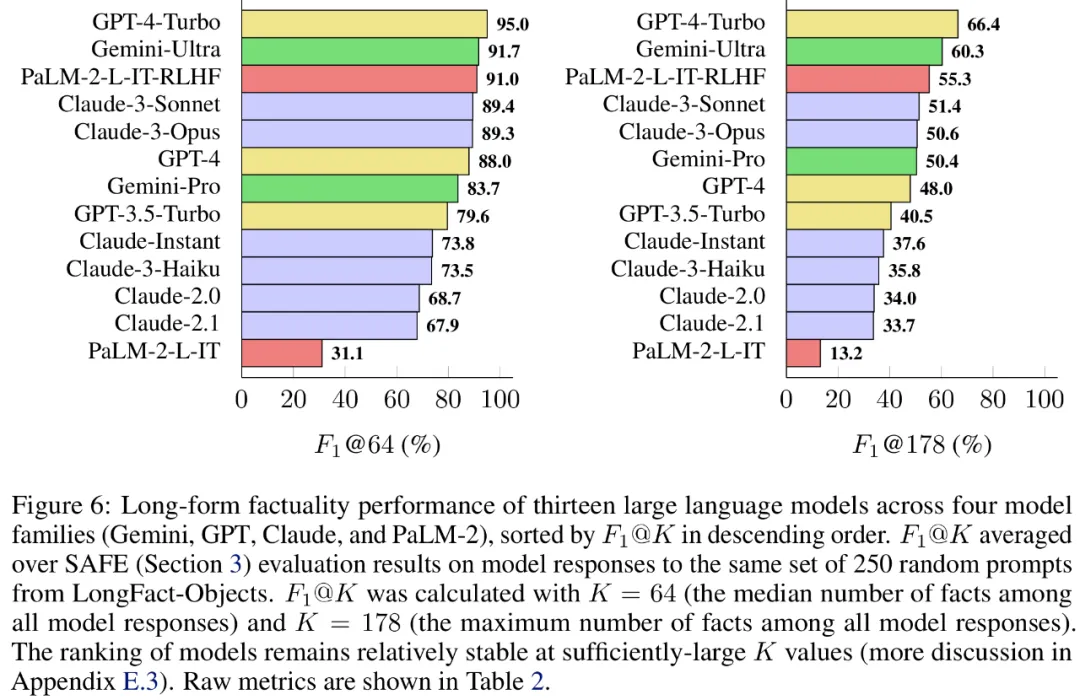
연구원들은 또한 LongFact를 사용하여 4개의 대형 모델 시리즈(Gemini, GPT, Claude 및 PaLM-2)에서 13개의 인기 있는 언어 모델을 벤치마킹했으며 더 큰 언어 모델이 일반적으로 더 나은 결과를 얻을 수 있음을 발견했습니다.
논문 저자 중 한 명이자 Google의 연구 과학자인 Quoc V. Le는 긴 형식의 사실성을 평가하고 벤치마킹하는 이 새로운 작업이 새로운 데이터 세트, 새로운 평가 방법 및 방법을 제안한다고 말했습니다. 정확성과 집계된 재현율 측정항목의 균형을 유지합니다. 동시에 모든 데이터와 코드는 향후 작업을 위해 오픈 소스로 제공될 것입니다.
LONGFACT: LLM을 사용하여 긴 사실 기반 다중 주제 벤치마크 생성
먼저 GPT-4를 사용하여 생성된 LongFact 프롬프트 세트를 살펴보세요. 여기에는 2280개의 사실 탐색 프롬프트가 포함되어 있습니다. 수동으로 선택한 38개 주제에 대해 긴 형식의 응답이 필요했습니다. 연구원들은 LongFact가 다양한 분야에서 장문의 사실성을 평가하기 위한 최초의 프롬프트 세트라고 말합니다.
LongFact에는 LongFact-Concepts와 LongFact-Objects라는 두 가지 작업이 포함되어 있으며, 질문이 개념에 대해 묻는지 아니면 개체에 대해 묻는지 여부로 구분됩니다. 연구자들은 각 주제에 대해 30개의 고유한 단서를 생성하여 각 작업에 대해 1140개의 단서를 생성했습니다.

SAFE: 사실 자동 평가자로서의 LLM 에이전트
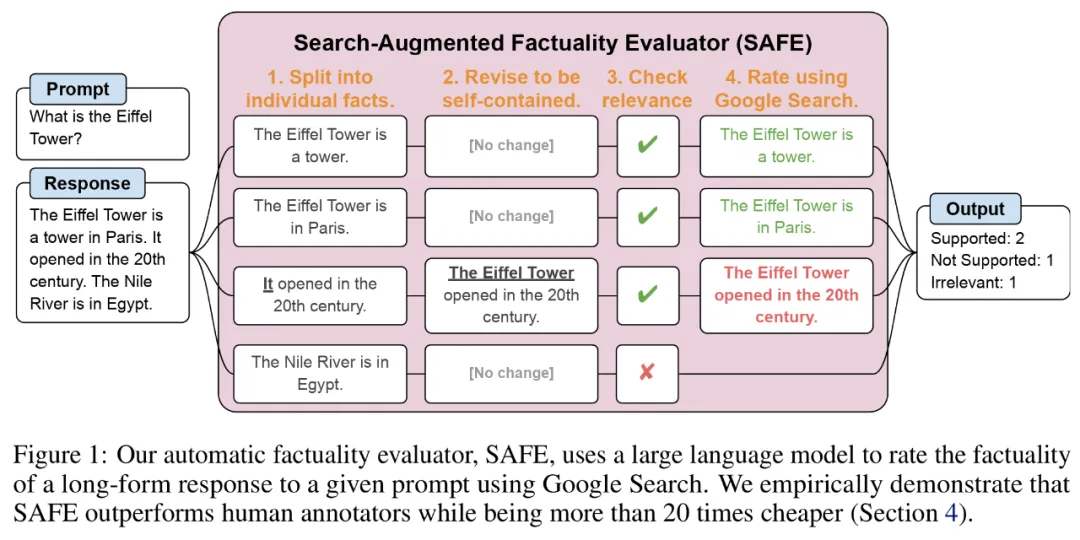
연구원들은 SAFE(Search Augmented Fact Evaluator)를 제안했으며, 그 작동 원리는 다음과 같습니다.
a) 분할 개별적인 독립적인 사실에 대한 긴 응답
b) 각 개별 사실이 문맥에 따라 프롬프트에 응답하는 것과 관련이 있는지 확인합니다. c) 각 관련 사실에 대해 다단계 프로세스를 통해 Google 검색어를 반복적으로 발행하고 검색 결과가 해당 사실을 뒷받침하는지 추론합니다. SAFE의 핵심 혁신은 언어 모델을 에이전트로 사용하여 다단계 Google 검색 쿼리를 생성하고 검색 결과가 사실을 뒷받침하는지 신중하게 추론하는 것이라고 믿습니다. 아래 그림 3은 추론 체인의 예를 보여줍니다. 긴 응답을 별도의 독립적인 사실로 분할하기 위해 연구원은 먼저 언어 모델에 긴 응답의 각 문장을 별도의 사실로 분할하도록 지시한 다음 대명사와 같은 모호한 참조를 분리하도록 모델에 지시했습니다. 응답 컨텍스트에서 참조하는 올바른 엔터티를 확인하고 각 개별 사실을 독립적으로 수정합니다. 각각의 독립적인 사실에 점수를 매기기 위해 언어 모델을 사용하여 해당 사실이 응답 컨텍스트의 프롬프트 답변과 관련이 있는지 추론한 다음 다단계 방법을 사용하여 나머지 관련 사실을 "지원됨"으로 평가합니다. 또는 "지원되지 않음". 자세한 내용은 아래 그림 1에 나와 있습니다. 각 단계에서 모델은 점수를 매길 사실과 이전에 얻은 검색 결과를 기반으로 검색 쿼리를 생성합니다. 특정 단계를 거친 후 모델은 추론을 수행하여 위의 그림 3과 같이 검색 결과가 해당 사실을 뒷받침하는지 여부를 결정합니다. 모든 사실이 평가된 후 지정된 프롬프트-응답 쌍에 대한 SAFE의 출력 메트릭은 "지원" 사실의 수, "관련 없는" 사실의 수 및 "지원되지 않는" 사실의 수입니다. LLM 에이전트는 인간보다 더 나은 사실 주석자가 됩니다. SAFE를 사용하여 얻은 주석의 품질을 정량적으로 평가하기 위해 연구원들은 크라우드소싱된 인간 주석을 사용했습니다. 데이터에는 496개의 프롬프트-응답 쌍이 포함되어 있으며, 여기서 응답은 수동으로 개별 사실(총 16,011개 개별 사실)로 분할되었으며 각 개별 사실은 지원됨, 관련 없음 또는 지원되지 않음으로 수동으로 레이블이 지정되었습니다. 아래 그림 4에 표시된 것처럼 SAFE 주석과 각 사실에 대한 인간 주석을 직접 비교한 결과 SAFE가 개별 사실의 72.0%에 대해 인간과 동의한다는 사실을 발견했습니다. 이는 SAFE가 대부분의 개별 사실에 대해 인간 수준의 성과를 달성했음을 보여줍니다. 그런 다음 무작위 인터뷰에서 얻은 100개의 개별 사실 중 SAFE의 주석이 인간 평가자의 주석과 일치하지 않는지 조사했습니다. 연구원들은 각 사실에 수동으로 주석을 다시 달고(더 포괄적인 주석을 위해 Wikipedia뿐만 아니라 Google 검색에 액세스할 수 있도록 허용) 이러한 라벨을 근거 자료로 사용했습니다. 그들은 이러한 불일치 사례에서 SAFE 주석이 76%의 확률로 올바른 반면, 사람의 주석은 19%만 정확하다는 사실을 발견했습니다. 이는 SAFE의 승률이 4대1임을 나타냅니다. 자세한 내용은 아래 그림 5에 나와 있습니다. 여기서 두 가지 애너테이션 요금제의 가격에 주목할 필요가 있습니다. 사람의 주석을 사용하여 단일 모델 응답을 평가하는 비용은 4달러인 반면, GPT-3.5-Turbo 및 Serper API를 사용하는 SAFE는 0.19달러에 불과합니다. Gemini, GPT, Claude 및 PaLM-2 시리즈 벤치마크 테스트 마지막으로 연구원들은 표 1의 4개 모델 시리즈(Gemini, GPT, Claude 및 PaLM-2)에 대해 LongFact를 수행했습니다. 2) 13개의 대규모 언어 모델에 대해 광범위한 벤치마크 테스트를 수행했습니다. 구체적으로 그들은 LongFact-Objects에서 250개 단서의 동일한 무작위 하위 집합을 사용하여 각 모델을 평가한 다음 SAFE를 사용하여 각 모델 응답의 원시 평가 지표를 얻고 F1@K 중합 지표를 사용했습니다. 일반적으로 더 큰 언어 모델이 더 나은 긴 형식의 사실성을 달성하는 것으로 나타났습니다. 아래 그림 6과 표 2에서 보듯이 GPT-4보다 GPT-4-Turbo가 좋고, GPT-3.5-Turbo보다 GPT-4가 좋고, Gemini-Pro보다 Gemini-Ultra가 좋고, PaLM-2-L이 좋습니다. -IT-RLHF PaLM-2-L-IT보다 우수합니다. 자세한 기술적 세부사항과 실험 결과는 원본 논문을 참조하세요. 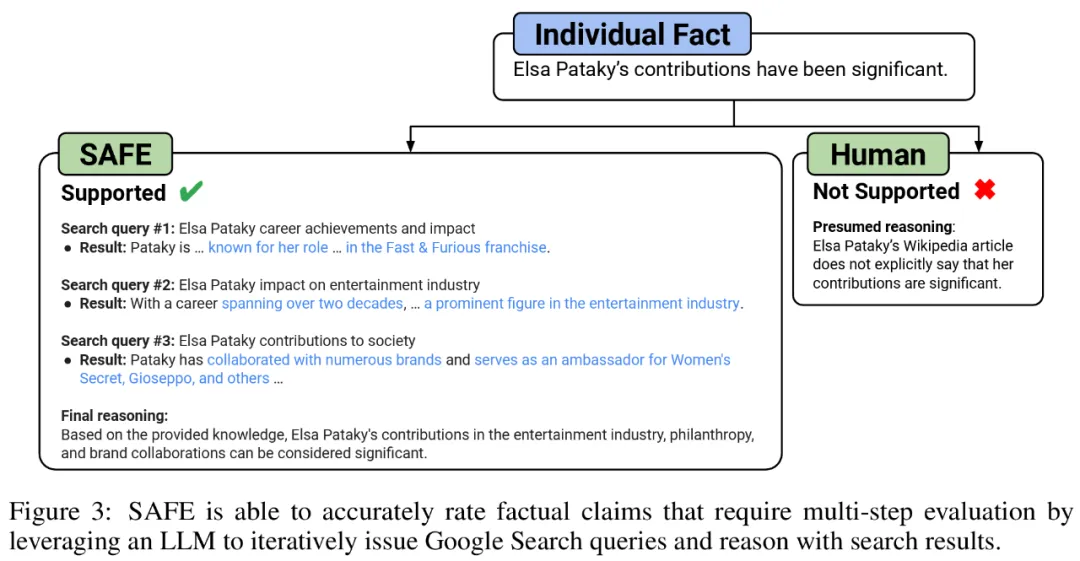
실험 결과

위 내용은 DeepMind는 대형 모델의 환상을 종식시킨다? 라벨링 사실은 인간보다 더 신뢰할 수 있고, 20배 저렴하며, 완전한 오픈 소스입니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



