

최근 연구에서 비전-언어-액션(VLA, 비전-언어-액션) 모델의 입력은 보다 일반적인 3D 물리적 세계를 통합하지 않고 기본적으로 2D 데이터입니다.
또한 기존 모델은 세계의 역동성과 행동과 역동성의 관계를 무시하고 "인식된 행동의 직접 매핑"을 학습하여 행동 예측을 수행합니다.
반면 인간은 생각할 때 미래 시나리오에 대한 상상을 설명하고 다음 행동을 계획할 수 있는 세계 모델을 도입합니다.
이를 위해 University of Massachusetts Amherst, MIT 및 기타 기관의 연구자들은 새로운 차원의 구체화된 기초 모델을 도입하여 생성된 세계 모델을 기반으로 3D 인식을 원활하게 연결할 수 있는 3D-VLA 모델을 제안했습니다. 추론과 행동. 
프로젝트 홈페이지: https://vis-www.cs.umass.edu/3dvla/
논문 주소: https://arxiv.org/abs/2403.09631
구체적으로 3D-VLA는 3D 기반 LLM(대형 언어 모델)을 기반으로 구축되었으며 구현된 환경에 참여할 수 있는 상호 작용 토큰 세트를 도입합니다.
Qianchuang 팀은 일련의 구체화된 확산 모델을 훈련하고 모델에 생성 기능을 주입한 다음 이를 LLM에 정렬하여 대상 이미지와 포인트 클라우드를 예측했습니다.
3D-VLA 모델을 훈련하기 위해 기존 로봇 데이터세트에서 대량의 3D 관련 정보를 추출하고 거대한 3D 구현 명령 데이터세트를 구축했습니다.
연구 결과에 따르면 3D-VLA는 구현된 환경에서 추론, 다중 모드 생성 및 계획 작업을 처리하는 데 탁월한 성능을 발휘하여 실제 시나리오에서의 잠재적인 적용 가치를 강조합니다.
3D Embodied Instruction Tuning Dataset
인터넷에 있는 수십억 규모의 데이터 세트로 인해 VLM은 여러 작업에서 뛰어난 성능을 입증했으며 수백만 개의 비디오 동작 데이터 세트는 로봇 제어를 위한 구체적인 VLM의 토대를 마련합니다. .
그러나 대부분의 현재 데이터 세트는 로봇 작업에 대한 충분한 깊이나 3D 주석 및 정밀한 제어를 제공할 수 없습니다. 이를 위해서는 데이터 세트에 3D 공간 추론 및 상호 작용 콘텐츠가 포함되어야 합니다. 3차원 정보가 부족하면 "가장 먼 컵을 가운데 서랍에 넣으세요"와 같이 3차원 공간 추론이 필요한 지시를 로봇이 이해하고 실행하기가 어렵습니다.

이 격차를 해소하기 위해 연구원들은 모델을 훈련하는 데 충분한 "3D 관련 정보"와 "해당 텍스트 지침"을 제공하는 대규모 3D 명령 튜닝 데이터 세트를 구축했습니다.
연구원들은 기존의 구현된 데이터 세트에서 3D 언어 동작 쌍을 추출하고 포인트 클라우드, 깊이 맵, 3D 경계 상자, 로봇의 7D 동작 및 텍스트 설명에 대한 주석을 얻는 파이프라인을 설계했습니다.
3D-VLA는 구현된 환경에서 3차원 추론, 목표 생성 및 의사결정에 사용되는 세계 모델입니다.
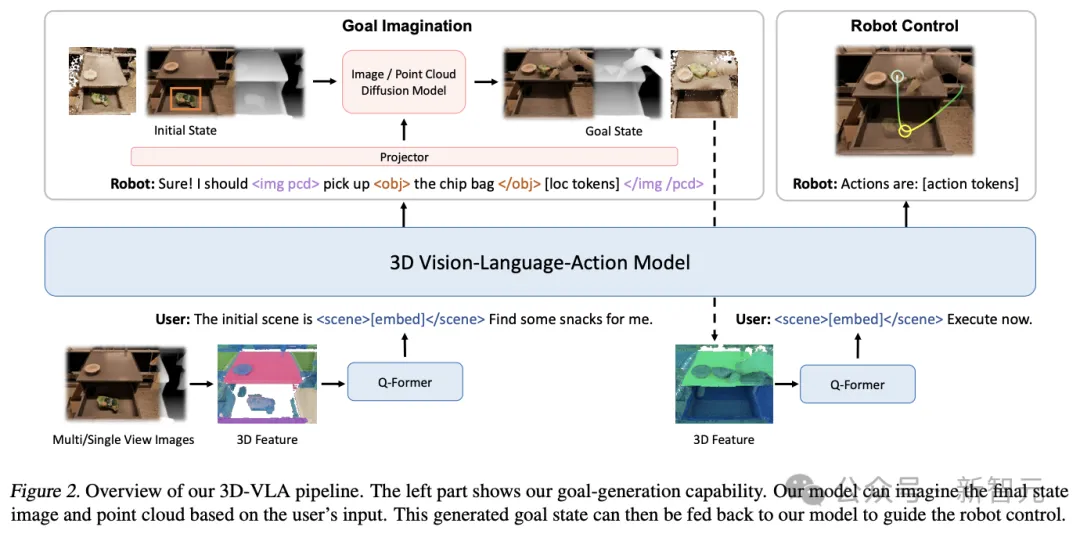
먼저 3D-LLM 위에 백본 네트워크를 구축하고 일련의 상호 작용 토큰을 추가하여 모델의 3D 세계와 상호 작용하는 능력을 더욱 강화한 다음 확산 모델을 사전 훈련하고 투영을 사용합니다. LLM과 확산 모델을 정렬하여 3D-VLA
백본 네트워크
에 타겟 생성 기능을 주입합니다. 첫 번째 단계에서 연구원들은 3D-LLM 방법을 따라 3D-VLA 기본 모델을 개발했습니다. 수집된 데이터 세트가 도달하지 못했습니다. 다중 모드 LLM을 처음부터 교육하는 데 필요한 10억 수준 규모에는 시각적 기능을 사전 교육된 VLM에 원활하게 통합할 수 있도록 멀티뷰 기능을 사용하여 3D 장면 기능을 생성해야 합니다. 적응을 위해.
동시에 3D-LLM의 훈련 데이터 세트에는 특정 설정과 직접적으로 일치하지 않는 객체와 실내 장면이 주로 포함되어 있으므로 연구자들은 사전 훈련 모델로 BLIP2-PlanT5XL을 사용하기로 결정했습니다.
훈련 과정에서 토큰의 입력 및 출력 임베딩과 Q-Former의 가중치를 고정 해제합니다.
상호작용 토큰
환경 내 3D 장면과 상호 작용에 대한 모델의 이해를 높이기 위해 연구원들은 새로운 상호 작용 토큰 세트를 도입했습니다
먼저, 구문 분석된 문장의 개체 명사(예: <)를 포함하여 개체 토큰이 입력에 추가되었습니다. ; obj> 초콜릿 바 [loc tokens] 모델이 조작되거나 언급되는 객체를 더 잘 포착할 수 있도록 합니다.
두 번째로, 공간 정보를 언어로 더 잘 표현하기 위해 연구원들은 AABB 형태의 6개 마커를 사용하여 3차원 경계 상자를 나타내는 위치 토큰 세트
셋째, 동적 인코딩을 더 잘 수행하기 위해 프레임워크에
로봇 동작을 나타내는 특수 마커 세트를 확장하여 아키텍처가 더욱 향상되었습니다. 로봇의 동작에는 7개의 자유도가 있으며,
목표 생성 기능 주입
인간은 장면의 최종 상태를 사전 시각화하여 행동 예측이나 의사 결정의 정확성을 높일 수 있습니다. 이는 세계 모델 구축의 핵심 측면이기도 합니다. 예비 실험에서 연구자들은 현실적인 최종 상태를 제공하면 모델의 추론 및 계획 능력을 향상시킬 수 있다는 사실도 발견했습니다.
그러나 이미지, 깊이 및 포인트 클라우드를 생성하기 위해 MLLM을 훈련시키는 것은 간단하지 않습니다.
우선, 비디오 확산 모델은 "오픈"의 미래 프레임을 생성하는 활주로와 같은 구현된 장면에 맞게 맞춤화되지 않았습니다. 서랍"을 사용하면 장면에서 뷰 변경, 개체 변형, 이상한 텍스처 교체, 레이아웃 왜곡 등의 문제가 발생합니다.
그리고 다양한 모드의 확산 모델을 어떻게 하나의 기본 모델로 통합할지는 여전히 어려운 문제입니다.
그래서 연구진이 제안한 새로운 프레임워크는 먼저 이미지, 깊이, 포인트 클라우드 등 다양한 형태를 기반으로 특정 확산 모델을 사전 학습한 다음 확산 모델의 디코더를 3D-VLA의 임베딩 공간에 정렬합니다. 정렬 단계에서.

3D-VLA는 3D 세계에서 추론 및 위치 파악을 수행하고 다중 모드 대상 콘텐츠를 상상하며 로봇 작업을 생성할 수 있는 다목적 3D 기반 생성 세계 모델입니다. 액션, 연구원 주로 3D 추론 및 현지화, 다중 모드 목표 생성 및 구체화된 행동 계획의 세 가지 측면에서 3D-VLA를 평가했습니다.
3D 추론 및 위치 파악
3D-VLA는 언어 추론 작업에서 모든 2D VLM 방법보다 성능이 뛰어납니다. 연구자들은 이를 3D 정보의 활용으로 인해 보다 정확한 추론 공간 정보를 제공할 수 있다고 생각합니다.
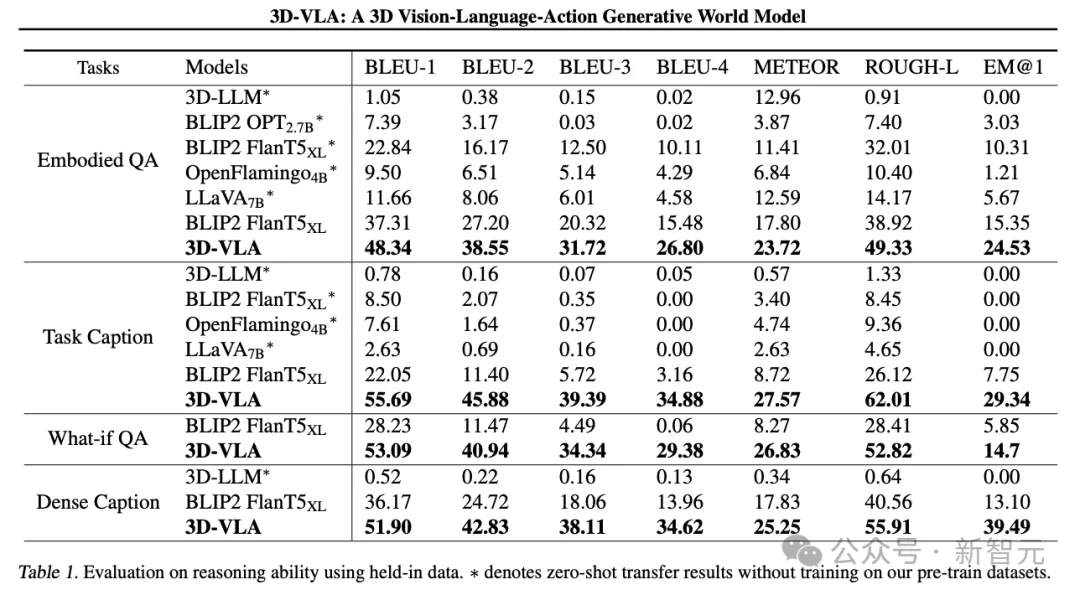
또한 데이터 세트에는 3D 위치 지정 주석 세트가 포함되어 있으므로 3D-VLA는 관련 개체를 찾는 방법을 학습하여 모델이 추론을 위해 주요 개체에 더 집중할 수 있도록 도와줍니다.
연구원들은 3D-LLM이 이러한 로봇 추론 작업에서 제대로 수행되지 않는다는 사실을 발견했으며, 이는 로봇 관련 3D 데이터 세트를 수집하고 교육할 필요성을 보여줍니다.
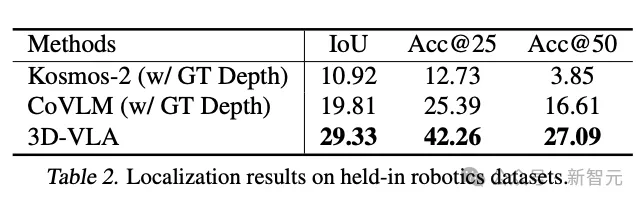
그리고 3D-VLA는 위치 파악 성능에서 2D 기준 방법보다 훨씬 더 나은 성능을 발휘했습니다. 또한 이 발견은 주석 프로세스의 효율성에 대한 설득력 있는 증거를 제공하여 모델이 강력한 3D 위치 지정 기능을 얻는 데 도움이 됩니다.
로봇 공학 영역으로의 제로 샷 전송을 위한 기존 생성 방법과 비교할 때 3D-VLA는 대부분의 측정 항목에서 더 나은 성능을 달성하여 "로봇 응용 분야를 위해 특별히 설계된" 사용을 확인합니다. 세계 모델을 훈련하기 위한 데이터 세트를 설계합니다.
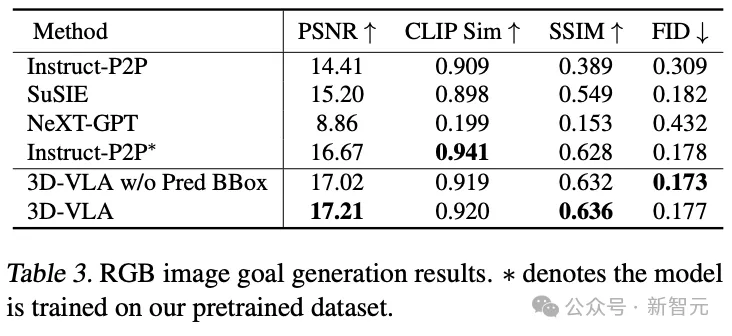
Instruct-P2P*와의 직접적인 비교에서도 3D-VLA는 일관되게 더 나은 성능을 발휘하며, 결과에 따르면 대규모 언어 모델을 3D-VLA에 통합하면 로봇 작동 지침을 보다 포괄적이고 깊이 이해할 수 있으므로 결과적으로 성능이 향상됩니다. 목표 이미지 생성 성능.
또한 입력 프롬프트에서 예측 경계 상자를 제외하면 약간의 성능 저하가 관찰되어 모델이 전체 장면을 이해하는 데 도움이 될 수 있는 중간 예측 경계 상자를 사용하는 효과를 확인하여 모델이 통합할 수 있도록 합니다. 주어진 명령에서 언급된 특정 개체에 더 많은 주의가 할당되어 궁극적으로 최종 대상 이미지를 상상하는 능력이 향상됩니다.
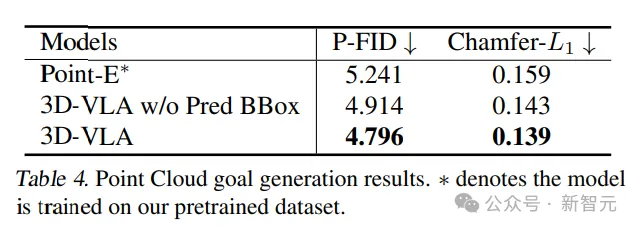
포인트 클라우드에서 생성된 결과를 비교하면 중간 예측 경계 상자가 있는 3D-VLA가 가장 잘 수행되어 지침과 장면을 이해하는 맥락에서 대규모 언어 모델과 정확한 객체 위치 파악의 결합이 중요함을 확인했습니다.
Embodied Action Planning
3D-VLA는 RLBench 동작 예측의 대부분 작업에서 기준 모델의 성능을 능가하여 계획 기능을 보여줍니다.
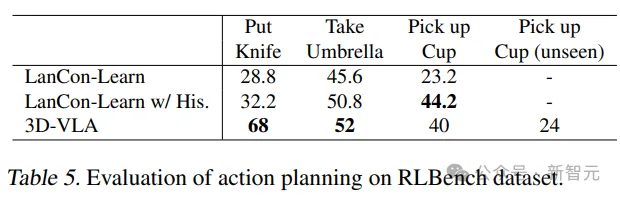
기본 모델은 과거 관찰, 객체 상태 및 현재 상태 정보를 사용해야 하는 반면 3D-VLA 모델은 개방 루프 제어를 통해서만 실행된다는 점에 주목할 가치가 있습니다.
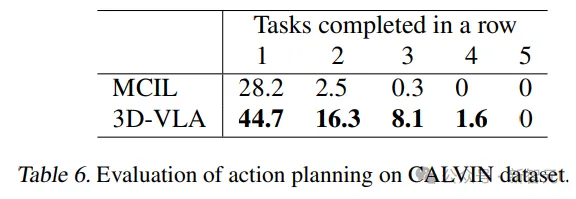
또한, 3D-VLA는 픽업 컵 작업에서도 좋은 결과를 얻었습니다. 연구원들은 이러한 이점을 물체를 찾는 능력에 기인했습니다. 관심을 갖고 목표 상태를 상상하며 행동 추론을 위한 풍부한 정보를 제공합니다.
위 내용은 Sora의 3D 버전이 나오나요? UMass, MIT 등이 3D 세계 모델을 제안하고, 구현된 지능형 로봇이 새로운 이정표를 달성함의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



