

LoRA(Low-Rank Adaptation)는 LLM(대형 언어 모델)을 미세 조정하기 위해 설계된 인기 있는 기술입니다. 이 기술은 원래 Microsoft 연구원이 제안했으며 "LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS" 논문에 포함되었습니다. LoRA는 신경망의 모든 매개변수를 조정하는 대신 소수의 하위 행렬을 업데이트하는 데 중점을 두고 모델 학습에 필요한 계산량을 크게 줄인다는 점에서 다른 기술과 다릅니다.
LoRA의 미세 조정 품질은 전체 모델 미세 조정과 비슷하기 때문에 많은 사람들이 이 방법을 미세 조정 아티팩트라고 부릅니다. 출시 이후 많은 사람들이 이 기술에 대해 호기심을 갖고 연구를 더 잘 이해하기 위해 코드를 작성하고 싶어했습니다. 과거에는 적절한 문서가 부족한 것이 문제였지만 이제는 도움이 될 수 있는 튜토리얼이 있습니다.
이 튜토리얼의 저자는 유명한 기계 학습 및 AI 연구원인 Sebastian Raschka입니다. 그는 다양한 효과적인 LLM 미세 조정 방법 중에서 LoRA가 여전히 그의 첫 번째 선택이라고 말했습니다. 이를 위해 Sebastian은 LoRA를 처음부터 구축하기 위해 블로그 "Code LoRA From Scratch"를 작성했습니다. 그의 의견으로는 이것이 좋은 학습 방법입니다.
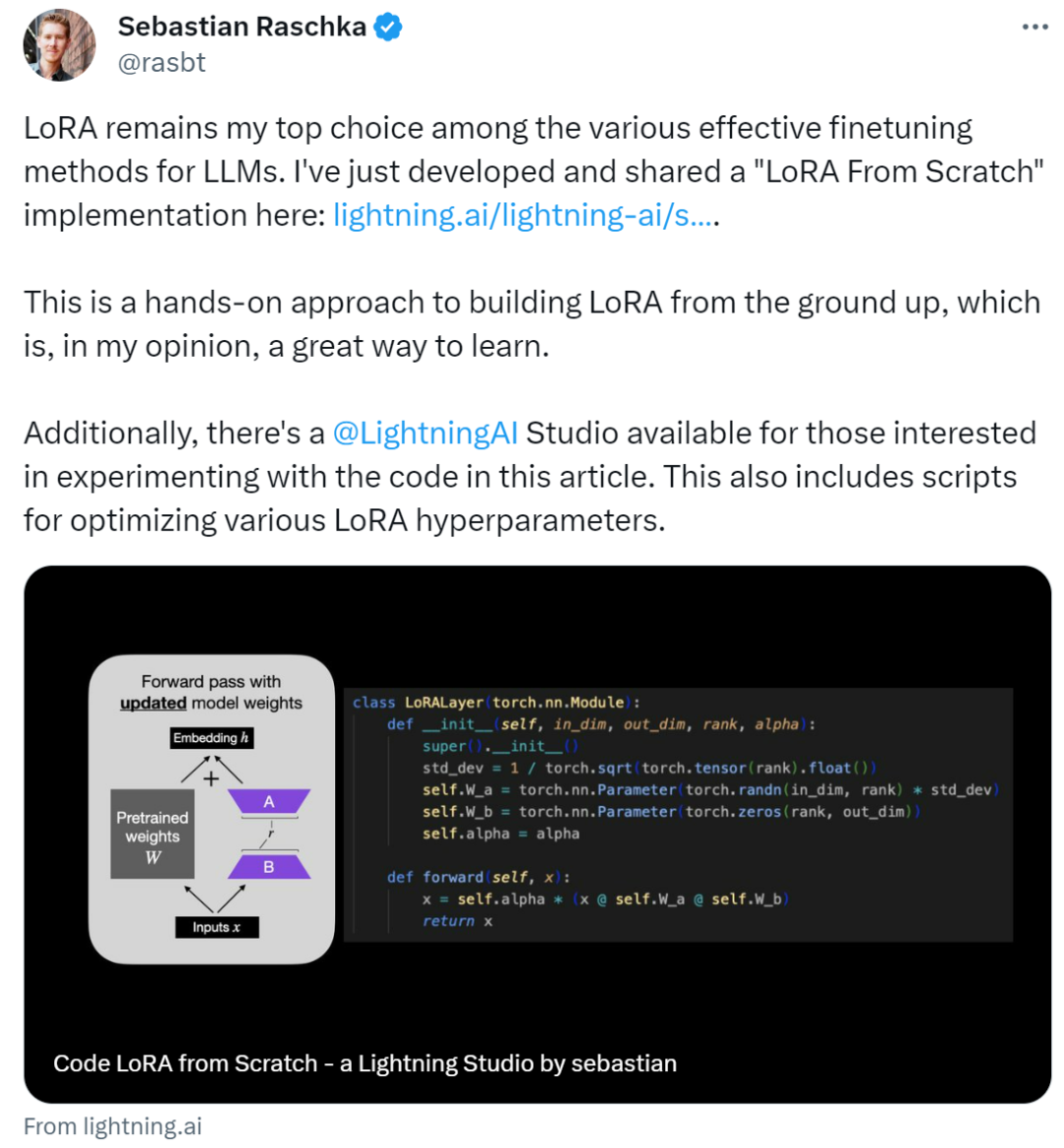
이 기사에서는 처음부터 코드를 작성하여 LoRA(낮은 순위 적응)를 소개합니다. Sebastian은 실험에서 DistilBERT 모델을 미세 조정하고 이를 분류 작업에 적용했습니다.
LoRA 방법과 기존의 미세 조정 방법을 비교한 결과, LoRA 방법은 테스트 정확도가 92.39%에 달하며, 이는 모델의 마지막 몇 레이어만 미세 조정한 것(86.22% 테스트 정확도)보다 우수합니다. ) 성능. 이는 LoRA 방법이 모델 성능을 최적화하는 데 분명한 이점이 있고 모델의 일반화 능력과 예측 정확도를 더 잘 향상시킬 수 있음을 보여줍니다. 이 결과는 더 나은 성능과 결과를 얻기 위해 모델 훈련 및 조정 중에 고급 기술과 방법을 채택하는 것이 중요함을 강조합니다.
Sebastian이 어떻게 이를 달성했는지 비교하면서 아래를 살펴보겠습니다.
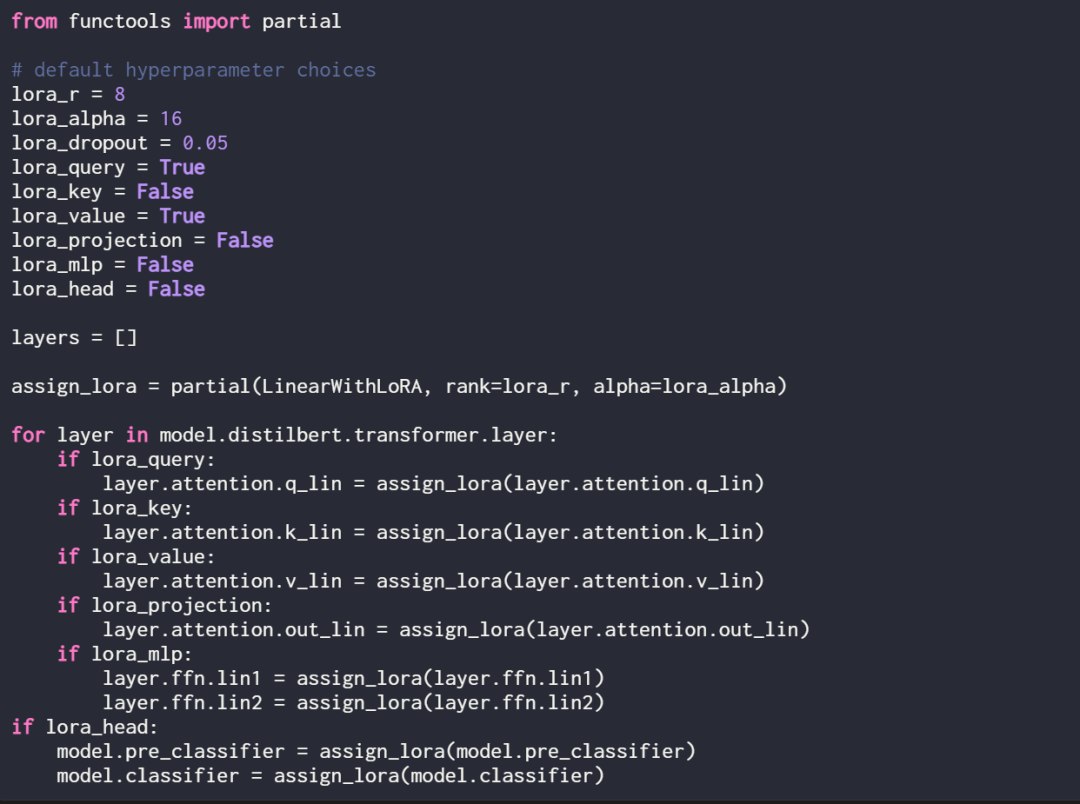
코드에서 LoRA 레이어를 설명하는 방법은 다음과 같습니다.
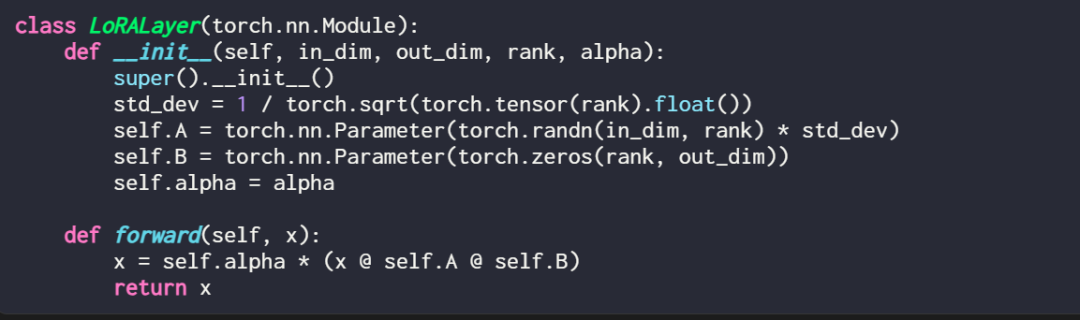
여기서 in_dim은 LoRA를 사용하여 수정하려는 레이어의 입력 차원이며, 이 out_dim에 해당합니다. 레이어의 출력 차원 알파 값이 높을수록 모델 동작에 대한 조정이 더 커짐을 의미하고 값이 낮을수록 그 반대를 의미합니다. 또한 이 기사에서는 무작위 분포에서 더 작은 값으로 행렬 A를 초기화하고 행렬 B를 0으로 초기화합니다.
LoRA가 작동하는 곳은 일반적으로 신경망의 선형(피드포워드) 계층이라는 점을 언급할 가치가 있습니다. 예를 들어, 두 개의 선형 레이어가 있는 간단한 PyTorch 모델 또는 모듈(예: Transformer 블록의 피드포워드 모듈일 수 있음)의 경우 전달 방법은 다음과 같이 표현될 수 있습니다.

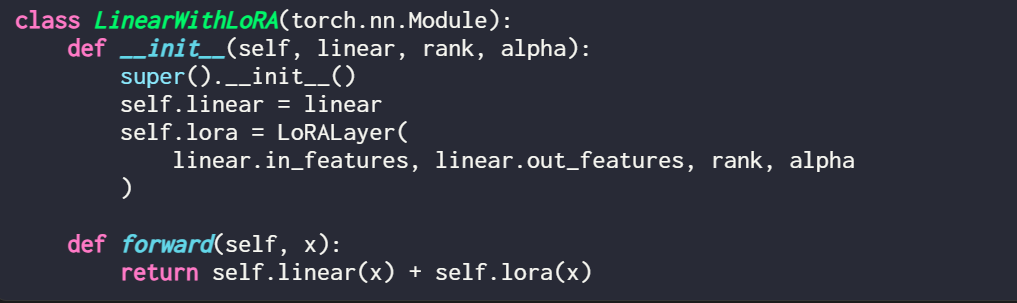
이러한 선형 레이어의 출력에 LoRA 업데이트를 추가하는 것이 일반적이며 결과 코드는 다음과 같습니다.

기존 PyTorch 모델을 수정하여 LoRA를 구현하려는 경우 간단한 방법은 각 선형 레이어
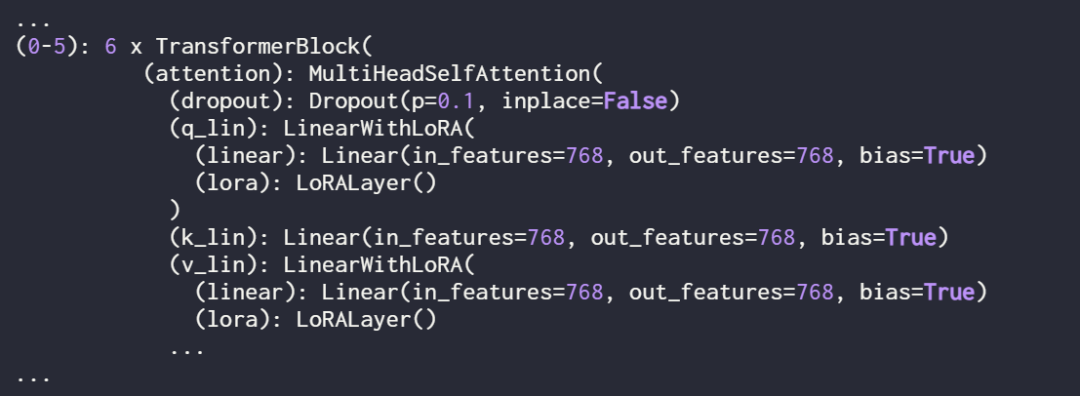
이러한 개념은 아래 그림에 요약되어 있습니다.
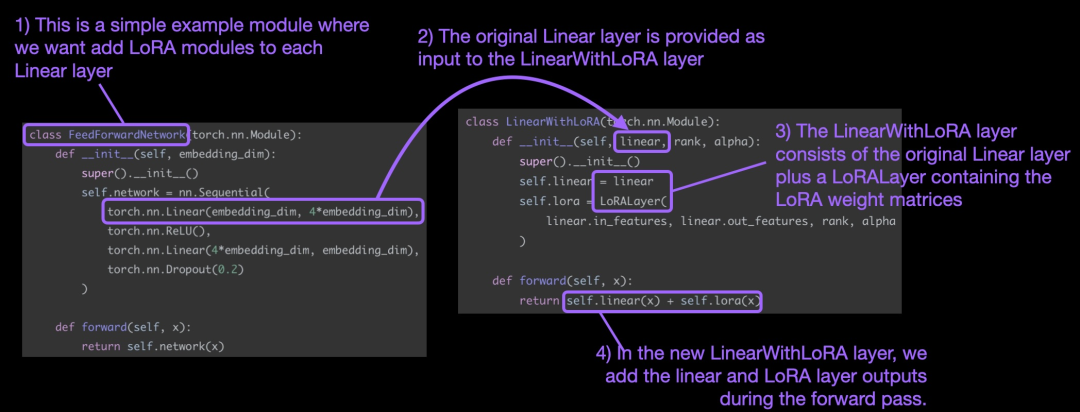
이 기사에서는 LoRA를 적용하기 위해 신경망의 기존 선형 레이어를 결합된 레이어로 대체합니다. 원본 선형 레이어와 LoRALayer의 LinearWithLoRA 레이어.
LoRA는 GPT나 이미지 생성과 같은 모델에 사용할 수 있습니다. 간단한 설명을 위해 이 기사에서는 텍스트 분류를 위해 소규모 BERT(DistilBERT) 모델을 사용합니다.

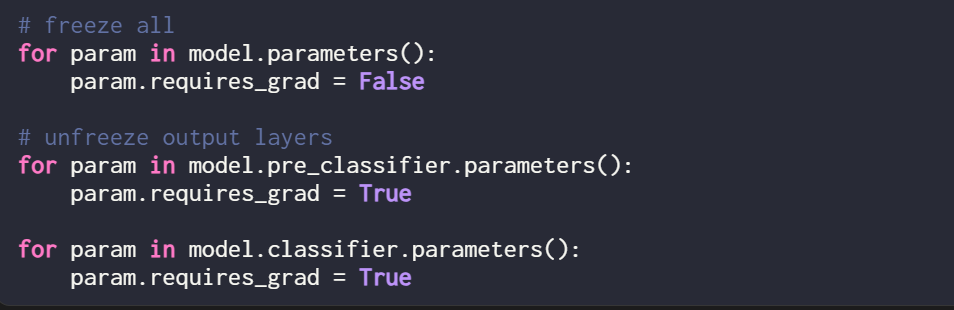
이 문서에서는 새로운 LoRA 가중치만 훈련하므로 모든 모델 매개변수를 고정하려면 모든 훈련 가능한 매개변수의 require_grad를 False로 설정해야 합니다.

다음으로 print(model)를 사용하여 모델을 확인합니다.

 업데이트된 구조를 확인하려면 인쇄(모델)를 사용하여 모델을 다시 확인하세요.
업데이트된 구조를 확인하려면 인쇄(모델)를 사용하여 모델을 다시 확인하세요.
위에서 볼 수 있듯이 Linear 레이어가 LinearWithLoRA 레이어로 성공적으로 대체되었습니다. 
위에 표시된 기본 하이퍼 매개변수를 사용하여 모델을 훈련하면 IMDb 영화 리뷰 분류 데이터 세트에서 다음과 같은 성능이 나타납니다.
검증 정확도: 89.98%
테스트 정확도: 89.44%
다음 섹션에서 이 문서에서는 이러한 LoRA 미세 조정 결과를 기존 미세 조정 결과와 비교합니다.
마지막 두 레이어만 훈련하여 얻은 분류 성능은 다음과 같습니다.
검증 정확도: 87.26%
테스트 정확도: 86.22%
결과에 따르면 LoRA는 마지막 두 레이어를 미세 조정하는 기존 방법보다 성능이 뛰어나지만 4배 적은 매개 변수를 사용합니다. . 모든 레이어를 미세 조정하려면 LoRA 설정보다 450배 더 많은 매개변수를 업데이트해야 했지만 테스트 정확도는 2%만 향상되었습니다.
이 구성에서 결과는 다음과 같습니다. 
LoRA 설정(500k VS 66M)에서 훈련 가능한 매개변수의 작은 세트만 있더라도 정확도는 전체 미세 조정으로 얻은 정확도보다 여전히 약간 높습니다.
원본 링크: https://lightning.ai/lightning-ai/studios/code-lora-from-scratch?cnotallow=f5fc72b1f6eeeaf74b648b2aa8aaf8b6
위 내용은 LoRA 코드를 처음부터 작성하는 방법은 다음과 같습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



