

OpenAI의 대형 모델을 탑재한 로봇이 늦은 밤에 찾아옵니다!
이름은 Figure 01이며 유연하게 듣고 말하고 움직일 수 있습니다.

눈앞에 보이는 모든 것을 설명할 수 있습니다.
탁자 위에 빨간 사과가 있고, 그 옆에 손으로 섰던 배수대에 여러 개의 접시와 컵이 있었습니다. 조심스럽게 테이블 위에 올려 놓으십시오.
 사진
사진
사람이 "먹고 싶다"고 하면 바로 사과를 건네줍니다.
 Pictures
Pictures
그리고 나는 사과를 테이블 위에 있는 유일한 먹을 수 있는 것이기 때문에 명확하게 이해하고 있습니다.
또한 물건을 정리하고 두 가지 작업을 동시에 처리할 수 있습니다.
 Pictures
Pictures
가장 중요한 점은 이러한 시연이 가속되지 않고 로봇의 원래 움직임이 매우 빠르다는 것입니다.
(운전석 뒤에는 아무도 없습니다)

이제 네티즌들은 가만히 앉아있을 수가 없습니다. @Boston Dynamics:
아저씨들, 이 사람 정말 신나네요. 우리는 연구실로 돌아가서 오래된 로봇(Boston Dynamics)이 좀 더 춤추도록 해야 합니다.
 사진
사진
OpenAI가 대형 언어 모델을 출시하고 Vincent의 동영상을 본 후 로봇을 저격하며 감동적으로 말했습니다.
이것은 OpenAI와 협력하여 치열한 경쟁입니다. Tesla Pull을 능가합니다.
하지만 하드웨어 측면에서는 옵티머스 프라임이 더 아름다워 보이지만 Figure 01에는 여전히 "성형 수술"이 필요합니다. (doge)
 Pictures
Pictures
다음으로 계속해서 Figure 01의 세부 사항을 살펴보겠습니다.
창업자의 소개에 따르면 Figure 01은 엔드투엔드 신경망을 통해 인간과 자유롭게 대화할 수 있습니다.
OpenAI가 제공하는 시각적 이해, 언어 이해 기능을 기반으로 빠르고 간단하며 능숙한 작업을 완료할 수 있습니다.
모델은 대형 시각적 언어 모델일 뿐이라고 하는데, GPT-4V인지는 알 수 없습니다.
 Pictures
Pictures
또한 행동을 계획하고, 단기 기억 능력을 갖고, 추론 과정을 언어로 설명할 수 있습니다.
 그림
그림
예를 들어 대화에서 "그들 거기에 넣어줄래?"
"그들", "저기"와 같은 모호한 표현의 이해는 로봇의 단기 기억 능력을 반영합니다.
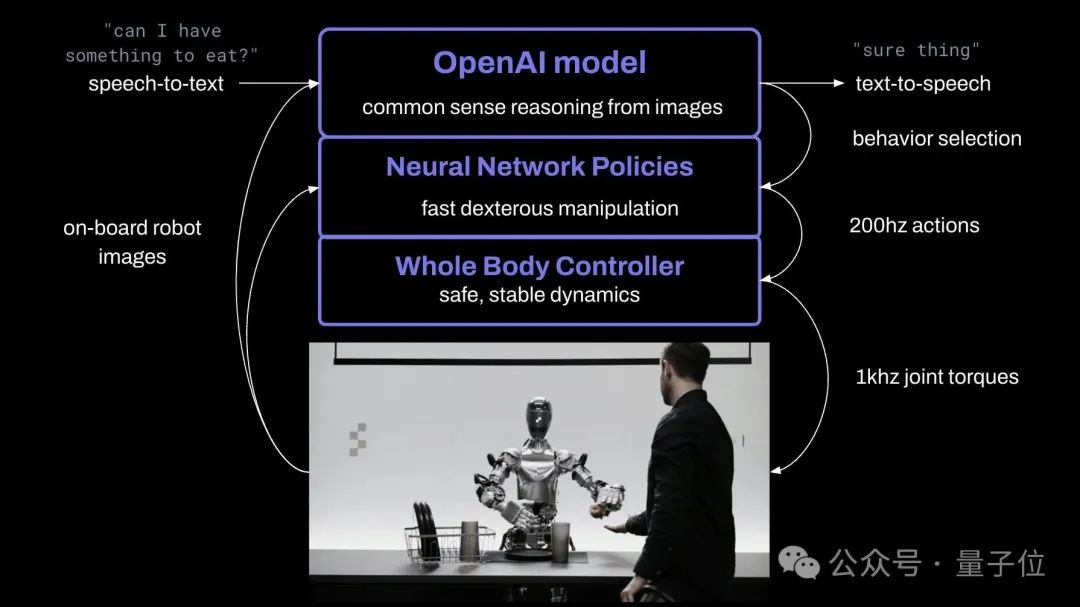
OpenAI로 훈련된 시각적 언어 모델을 사용합니다. 로봇 카메라는 10Hz에서 이미지를 캡처한 다음 신경망은 200Hz에서 24도 자유도 모션(손목 + 손가락 관절 각도)을 출력합니다.
구체적인 업무 분업 측면에서 로봇의 전략도 인간의 전략과 매우 유사합니다.
복잡한 행동은 대형 AI 모델에게 넘겨집니다. 미리 훈련된 모델은 이미지와 텍스트에 대해 상식적인 추론을 수행하고 행동 계획을 제시합니다.
비닐봉지 잡기(어디서나 잡을 수 있음), 로봇은 학습된 비전을 기반으로 합니다. 액션 실행 전략을 사용하면 "잠재의식적"인 빠른 반응 액션을 만들 수 있습니다.
동시에 전신 컨트롤러는 몸의 균형을 유지하고 안정적인 움직임을 담당하게 됩니다.
 Pictures
Pictures
로봇의 음성 기능은 대형 텍스트 음성 모델을 기반으로 미세 조정되었습니다.
 Pictures
Pictures
가장 진보된 AI 모델 외에도 Figure 01을 개발한 회사인 Figure의 창립자이자 CEO는 트윗에서 Figure가 로봇의 모든 핵심 구성 요소를 통합한다고 언급했습니다.
모터, 미들웨어 운영 체제, 센서, 기계 구조 등을 포함하여 모두 Figure 엔지니어가 설계했습니다.
이 로봇 스타트업 회사는 OpenAI와의 협력을 공식적으로 발표한 지 2주가 지났는데, 13일이 지나서야 이렇게 큰 성과를 거둔 것으로 알고 있습니다. 많은 사람들이 후속 협력을 기대하기 시작했습니다.
 Pictures
Pictures
이렇게 구현지능 분야의 또 한 명의 신예가 주목을 받았습니다.
피겨라고 하면 이 회사는 2022년에 설립되었습니다. 앞서 언급했듯이 불과 십여일 전에도 다시 한 번 외부 세계의 주목을 받았습니다-
공식 발표는 다음과 같습니다. 신규 라운드에서는 6억 7,500만 달러의 자금 조달이 이루어졌으며, 가치 평가액은 26억 달러에 이르렀습니다. Microsoft, OpenAI, Nvidia, Amazon 창립자 Bezos 등을 포함한 실리콘 밸리의 거의 절반이 투자자들이 모였습니다.
더 중요한 것은 OpenAI가 Figure와의 추가 협력 계획도 공개했습니다. 다중 모드 대형 모델의 기능을 로봇 인식, 추론 및 상호 작용으로 확장하고 "육체 노동에서 인간을 대체할 수 있는 휴머노이드 로봇을 개발"하는 것입니다.
지금 가장 핫한 기술 용어를 사용하려면 체화된 지능을 개발하기 위해 함께 노력해야 합니다.
 Pictures
Pictures
당시 Figure01의 최신 진행 상황은 Jiang 이모의 것이었습니다.
인간 시연 영상을 보고 Figure01은 단 10시간 만에 캡슐 커피 머신으로 커피 만드는 법을 배울 수 있었습니다. 끝까지 훈련 .
 Pictures
Pictures
Figure와 OpenAI의 협력이 공개되자마자 네티즌들은 이미 미래의 혁신에 대한 기대로 가득 차 있었습니다.
 Pictures
Pictures
결국 브렛 애드콕은 자신의 개인 홈페이지에 "유일한 초점은 인류의 미래에 긍정적인 영향을 미칠 수 있는 30년 관점에서 피규어를 만드는 것"이라고 적었습니다.
하지만 아마도 단 2주 만에 새로운 진전이 있을 것이라고는 누구도 상상하지 못했을 것입니다.
지금까지는 정말 빠릅니다. 그리고 계속해서 일반화되고 규모가 확장될 수 있습니다.
 Pictures
Pictures
폭격 현장 데모와 동시에 Figure의 채용 정보가 공개되었다는 점을 언급할 가치가 있습니다.
우리는 인간형 로봇에 생명을 불어넣고 있습니다. 우리와 함께하세요.
 Pictures
Pictures
참조 링크:
[1]//m.sbmmt.com/link/59bbfbe0d3922ccd1d167661a26d8353
[2]//m.sbmmt.com/link/a3fc34 dce 15cda93287496c84af5203c
[3]//m.sbmmt.com/link/194585b5215aea447389c5fefca09c61
위 내용은 OpenAI 대형모형 상체 로봇이 폭발 현장을 최고 속도로 시연합니다!의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



