

반년 넘게 Meta의 오픈소스 LLaMA 아키텍처는 LLM 테스트를 통과하여 큰 성공을 거두었습니다(안정적인 교육 및 손쉬운 확장).
ViT의 연구 아이디어에 따라 혁신적인 LLaMA 아키텍처의 도움으로 언어와 이미지의 아키텍처 통합을 진정으로 달성할 수 있을까요?
이 제안에 대해 최근 연구 VisionLLaMA가 진전을 이루었습니다. VisionLLaMA는 이미지 생성(Sora가 의존하는 기본 DIT 포함) 및 이해(분류, 분할, 감지, 자체 감독)와 같은 많은 주류 작업에서 원래 ViT 클래스 방법에 비해 크게 향상되었습니다.

이 연구는 이미지와 언어 아키텍처를 통합하려고 시도하며 안정적이고 효과적인 것을 포함하여 LLaMA에 대한 LLM 커뮤니티의 교육 결과를 활용할 수 있습니다. 확장 및 배포.
대형 언어 모델은 현재 학술 연구에서 뜨거운 주제입니다. 그 중 LLaMA는 가장 영향력 있고 대표적인 작품 중 하나입니다. 적용된 솔루션 중 이 시리즈의 오픈 소스 모델을 기반으로 구축되었습니다. 다중 모드 모델이 발전함에 따라 이러한 방법 중 상당수는 텍스트 처리를 위해 LLaMA를 사용하고 시각적 인식을 위해 CLIP과 같은 시각적 변환기를 사용합니다. 동시에 LLaMA의 추론 속도를 높이고 LLaMA의 저장 비용을 줄이기 위해 많은 노력을 기울이고 있습니다. 전체적으로 LLaMA는 이제 사실상 가장 다재다능하고 중요한 대규모 언어 모델 아키텍처입니다.

이 기사의 저자는 LLaMA 아키텍처의 성공으로 인해 간단하고 흥미로운 아이디어를 제안하게 되었습니다. 이 아키텍처가 시각적 양식에서도 똑같이 성공할 수 있습니까? 대답이 '예'라면 시각적 모델과 언어 모델 모두 동일한 통합 아키텍처를 사용할 수 있으며 LLaMA용으로 설계된 다양한 동적 배포 기술의 이점을 누릴 수 있습니다. 그러나 두 양식 사이에는 몇 가지 명백한 차이점이 있기 때문에 이는 복잡한 문제입니다.
텍스트 시퀀스와 시각적 작업이 데이터를 처리하는 방식에는 상당한 차이가 있습니다. 한편, 텍스트 시퀀스는 1차원 데이터인 반면, 비전 작업은 보다 복잡한 2차원 또는 다차원 데이터를 처리해야 합니다. 반면, 시각적 작업의 경우 일반적으로 성능 향상을 위해 피라미드 구조의 백본 네트워크를 사용해야 하는 반면, LLaMA 인코더는 비교적 간단한 구조를 가지고 있습니다. 또한 다양한 해상도의 이미지 및 비디오 입력을 효율적으로 처리하는 것도 어려운 과제입니다. 보다 효과적인 솔루션을 찾기 위해서는 텍스트 영역과 시각적 영역 간의 교차 연구에서 이러한 차이점을 완전히 고려해야 합니다.
이 문서의 목적은 이러한 과제를 해결하고 다양한 양식 간의 아키텍처 격차를 줄여 비전 작업에 적합한 LLaMA 아키텍처를 제안하는 것입니다. 이 아키텍처를 사용하면 모달 차이와 관련된 문제를 해결할 수 있으며 시각적, 언어적 데이터를 균일하게 처리하여 더 나은 결과를 얻을 수 있습니다.
이 기사의 주요 기여는 다음과 같습니다.
1 이 기사에서는 언어와 비전 간의 아키텍처 차이를 줄이기 위해 LLaMA와 유사한 시각적 변환기 아키텍처인 VisionLLaMA를 제안합니다.
2. 이 문서에서는 VisionLLaMA를 이미지 이해 및 생성을 포함한 일반적인 비전 작업에 적용하는 방법을 조사합니다(그림 1). 본 논문에서는 잘 알려진 두 가지 비전 아키텍처 체계(정규 구조와 피라미드 구조)를 조사하고 지도 학습 및 자기 지도 학습 시나리오에서 이들의 성능을 평가합니다. 또한 본 논문에서는 회전 위치 인코딩을 1D에서 2D로 확장하고 보간 스케일링을 활용하여 임의의 해상도를 수용하는 AS2DRoPE(즉, Autoscaling 2D RoPE)를 제안합니다.
3. 정밀한 평가를 통해 VisionLLaMA는 이미지 생성, 분류, 의미 분할 및 개체 감지와 같은 여러 대표적인 작업에서 현재의 주류 및 정밀하게 조정된 비전 변환기보다 훨씬 뛰어난 성능을 발휘합니다. 광범위한 실험을 통해 VisionLLaMA는 기존 비전 변환기보다 더 빠른 수렴 속도와 더 나은 성능을 갖는 것으로 나타났습니다.
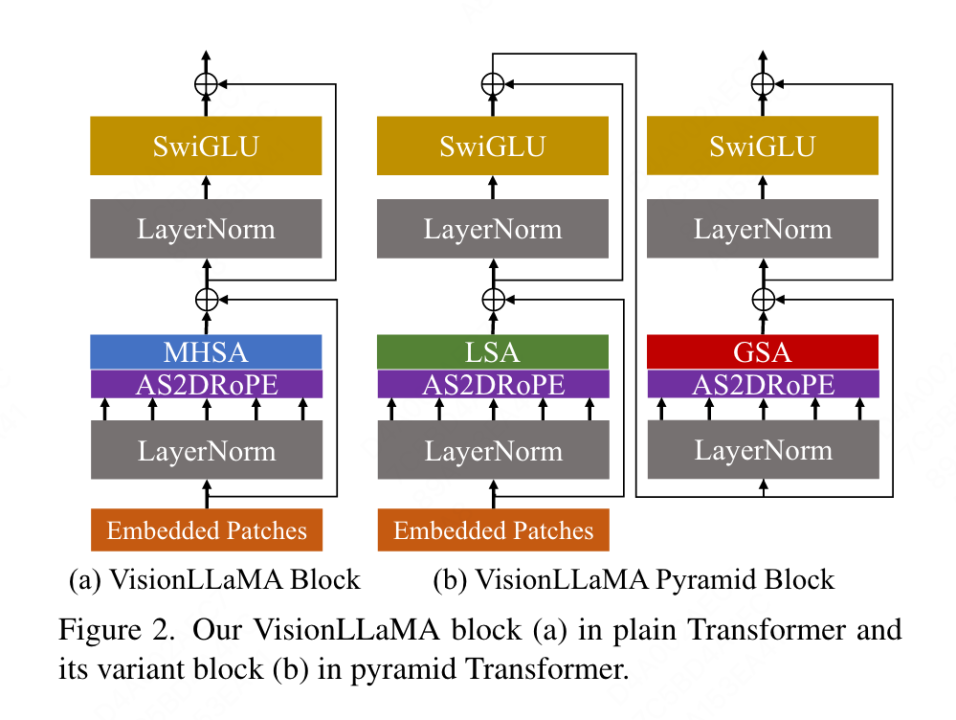
Conventional Transformer
본 글에서 제안하는 기존의 VisionLLaMA는 ViT의 프로세스를 따르며 LLaMA의 아키텍처 디자인을 최대한 그대로 유지하고 있다. 이미지의 경우 먼저 시퀀스로 변환 및 평면화된 다음 시퀀스 시작 부분에 카테고리 토큰이 추가되고 전체 시퀀스는 L VisionLLaMA 블록을 통해 처리됩니다. ViT와 달리 VisionLLaMA는 입력 시퀀스에 위치 인코딩을 추가하지 않습니다. VisionLLaMA의 블록에는 위치 인코딩이 포함되어 있기 때문입니다. 특히 이 블록은 RoPE(위치 인코딩을 통한 self-attention) 및 SwiGLU 활성화라는 두 가지 측면에서 표준 ViT 블록과 다릅니다. 이 기사에서는 여전히 RMSNorm 대신 LayerNorm을 사용합니다. 왜냐하면 이 기사에서는 전자가 더 나은 성능을 발휘한다는 것을 실험적으로 발견했기 때문입니다(표 11g 참조). 블록의 구조는 그림 2(a)에 나와 있습니다. 이 논문에서는 비전 작업에 1D RoPE를 직접 적용하는 것이 다른 해상도로 잘 일반화되지 않으므로 2D 형식으로 확장합니다.

Pyramid Structure Transformer
VisionLLaMA는 매우 간단합니다. Swin과 같은 창 기반 변환기에 적용하기 위해 이 기사에서는 더 강력한 기본 Twins에 강력한 피라미드 구조 변환기를 구축하는 방법을 탐색하기로 선택했습니다. Twins의 원래 아키텍처는 조건부 위치 코딩, 로컬-글로벌 관심의 형태로 인터리브된 로컬-글로벌 정보 교환을 활용합니다. 이러한 구성 요소는 변압기 전반에 걸쳐 공통적이므로 VisionLLaMA를 다양한 변압기 변형에 적용하는 것이 어렵지 않습니다.
이 글의 목표는 새로운 피라미드 구조의 비전 트랜스포머를 고안하는 것이 아니라 기존 디자인을 기반으로 VisionLLaMA의 기본 디자인을 조정하는 방법입니다. 따라서 이 글에서는 아키텍처와 디자인에 대한 최소한의 수정을 원칙으로 합니다. 하이퍼파라미터. ViT의 명명 방법에 따라 두 개의 연속 블록은 다음과 같이 작성할 수 있습니다.

여기서 LSA는 그룹 내 로컬 self-attention 작업이고 GSA는 각 블록의 대표 키 값과 상호 작용하여 수행됩니다. 하위 창 관심의 글로벌 하위 샘플링. 위치 정보가 AS2DRoPE에 이미 포함되어 있으므로 이 기사에서는 피라미드 구조 VisionLLaMA에서 조건부 위치 인코딩을 제거합니다. 또한 분류 헤드 이전에 카테고리 토큰을 제거하고 GAP(Global Average Pooling)를 사용합니다. 이 설정의 블록 구조는 그림 2(b)와 같습니다.
1차원 RoPE를 2차원으로 확장: 다양한 입력 해상도를 처리하는 것은 비전 작업의 일반적인 요구 사항입니다. 컨벌루션 신경망은 슬라이딩 윈도우 메커니즘을 사용하여 가변 길이를 처리합니다. 대조적으로, 대부분의 시각적 변환기는 로컬 창 작업 또는 보간을 적용합니다. 예를 들어 DeiT는 다양한 해상도로 훈련할 때 쌍삼차 보간을 사용하고 CPVT는 컨볼루션 기반 위치 인코딩을 사용합니다. 본 논문에서는 1D RoPE의 성능을 평가하여 224×224 해상도에서 가장 높은 정확도를 보였지만, 해상도가 448×448로 증가하면 정확도가 급격히 떨어지며 심지어 0에 도달합니다. 따라서 본 논문에서는 1차원 RoPE를 2차원으로 확장한다. 다중 헤드 self-attention 메커니즘의 경우 2D RoPE가 여러 헤드 간에 공유됩니다.
위치 보간은 2D RoPE의 일반화를 향상시킵니다. LLaMA의 컨텍스트 창을 확장하기 위해 보간을 사용하는 일부 작업에서 영감을 받은 VisionLLaMA는 더 높은 해상도의 참여로 2D 컨텍스트 창을 확장하는 유사한 방법을 채택합니다. 고정된 컨텍스트 길이가 확대된 언어 작업과 달리 객체 감지와 같은 시각적 작업은 종종 다양한 반복에서 다양한 샘플링 해상도를 처리합니다. 이 기사에서는 224×224의 입력 해상도를 사용하여 작은 모델을 훈련하고 재훈련 없이 더 큰 해상도의 성능을 평가하여 보간 또는 헤테로다인 전략을 더 잘 적용하도록 안내합니다. 실험 끝에 이 기사에서는 "앵커 해상도"를 기반으로 자동 크기 조정 보간(AS2DRoPE)을 적용하기로 결정했습니다. H × H의 정사각형 이미지와 B × B의 앵커 포인트 해상도를 처리하는 계산 방법은 다음과 같습니다.
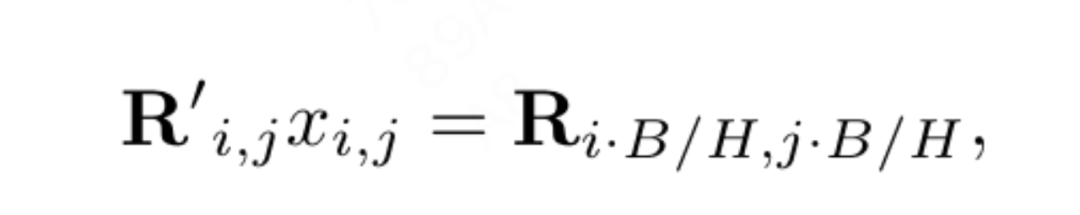
이 계산 방법은 효율적이며 추가 비용이 발생하지 않습니다. 훈련 해상도가 변경되지 않으면 AS2DRoPE는 2D RoPE로 변환됩니다.

요약된 키 값에 위치 정보를 추가해야 하기 때문에 이 문서에서는 피라미드 구조 설정에서 GSA에 대한 특수 처리를 수행합니다. 이러한 서브샘플링된 키는 기능 맵의 추상화를 통해 생성됩니다. 이 논문에서는 커널 크기 k×k 및 스트라이드 k의 컨볼루션을 사용합니다. 그림 3과 같이 생성된 키 값의 좌표는 샘플링된 특징의 평균으로 표현될 수 있다.
본 논문은 이미지 생성, 분류, 분할, 감지 등의 작업에 대한 VisionLLaMA의 효율성을 종합적으로 평가합니다. 기본적으로 이 문서의 모든 모델은 8개의 NVIDIA Tesla A100 GPU에서 교육됩니다.
이미지 생성
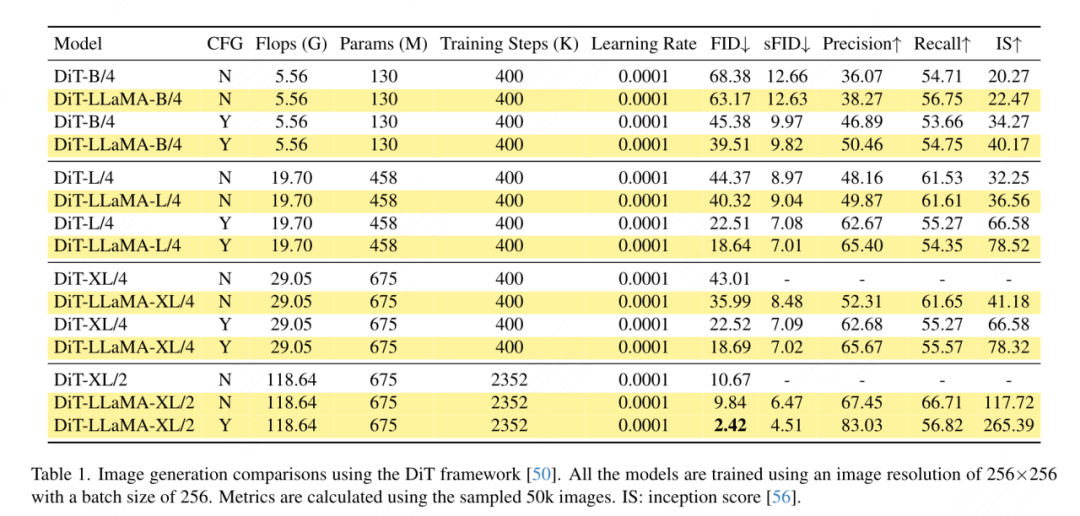
DiT 프레임워크 기반 이미지 생성: DiT는 Visual Transformer 및 DDPM을 사용한 이미지 생성의 대표적인 작업이므로 이 기사에서는 DiT 프레임워크에서 VisionLLaMA를 적용하기로 선택했습니다. 이 기사에서는 DiT의 원래 비전 변환기를 VisionLLaMA로 대체하고 다른 구성요소와 하이퍼파라미터는 변경하지 않습니다. 이 실험은 이미지 생성 작업에 대한 VisionLLaMA의 다양성을 보여줍니다. DiT와 마찬가지로 이 기사에서는 DDPM의 샘플 단계를 250으로 설정하고 실험 결과를 표 1에 표시합니다. 대부분의 방법론에 따라 FID는 기본 지표로 간주되며 sFID, 정밀도/재현율, 개시 점수와 같은 다른 보조 지표로 평가됩니다. 결과는 VisionLLaMA가 다양한 모델 크기에서 DiT보다 훨씬 뛰어난 성능을 보인다는 것을 보여줍니다. 또한 이 기사에서는 XL 모델의 훈련 단계 수를 2352k로 확장하여 모델이 더 빠른 수렴의 이점을 가지고 있는지 또는 더 긴 훈련 기간 설정에서 여전히 더 나은 성능을 발휘하는지 평가합니다. DiT-LLaMA-XL/2의 FID는 DiT-XL/2보다 0.83 낮습니다. 이는 VisionLLaMA가 DiT보다 계산 효율성이 더 좋을 뿐만 아니라 성능도 더 높다는 것을 나타냅니다. XL 모델을 사용하여 생성된 일부 예가 그림 1에 나와 있습니다.
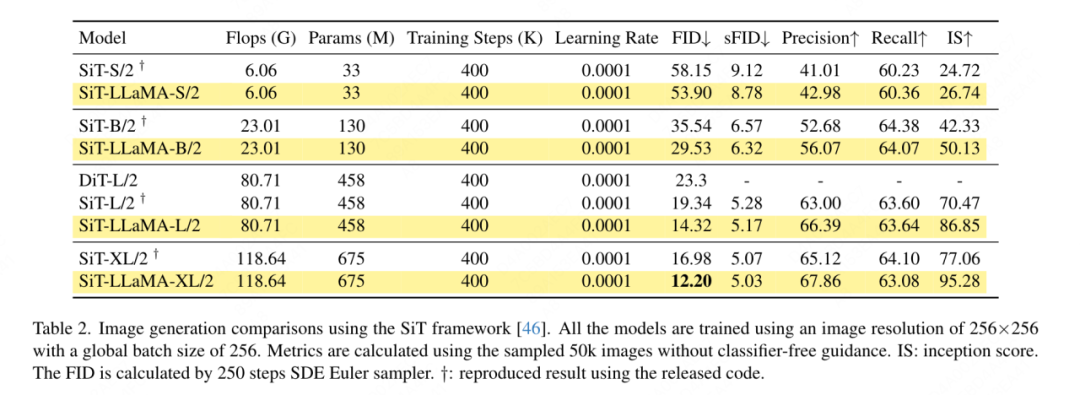
SiT 프레임워크 기반 이미지 생성: SiT 프레임워크는 시각적 변환기를 사용하여 이미지 생성 성능을 크게 향상시킵니다. 이 기사에서는 SiT-LLaMA라고 하는 더 나은 모델 아키텍처의 이점을 평가하기 위해 SiT의 비전 변환기를 VisionLLaMA로 대체합니다. 실험은 SiT의 나머지 모든 설정과 하이퍼파라미터를 유지했으며 모든 모델은 동일한 단계 수를 사용하여 훈련되었으며 선형 보간 및 속도 모델이 모든 실험에 사용되었습니다. 공정한 비교를 위해 공개된 코드를 다시 실행하고 250단계의 SDE 샘플러(Euler)를 사용하여 50k 256×256 이미지를 샘플링했으며 결과는 표 2에 나와 있습니다. SiT-LLaMA는 다양한 용량 수준에서 모델 전반에 걸쳐 SiT보다 성능이 뛰어납니다. SiT-L/2와 비교하여 SiT-LLaMA-L/2는 5.0 FID를 감소시키며 이는 새로운 프레임워크(4.0 FID)로 인한 개선보다 더 큽니다. 이 논문은 또한 표 13에서 보다 효율적인 ODE 샘플러(dopri5)를 보여 주며, 우리 방법과의 성능 격차는 여전히 존재합니다. SiT 논문에서와 유사한 결론을 도출할 수 있습니다. 즉, SDE는 ODE보다 더 나은 성능을 갖습니다.
ImageNet의 이미지 분류
이 섹션에서는 다른 항목을 제외하고 ImageNet-1K 데이터 세트에서 모델의 완전 감독 학습에 중점을 둡니다. 또는 증류 기술의 영향에 대해 모든 모델은 ImageNet-1K 훈련 세트를 사용하여 훈련되었으며 검증 세트의 정확도 결과는 표 3에 나와 있습니다.
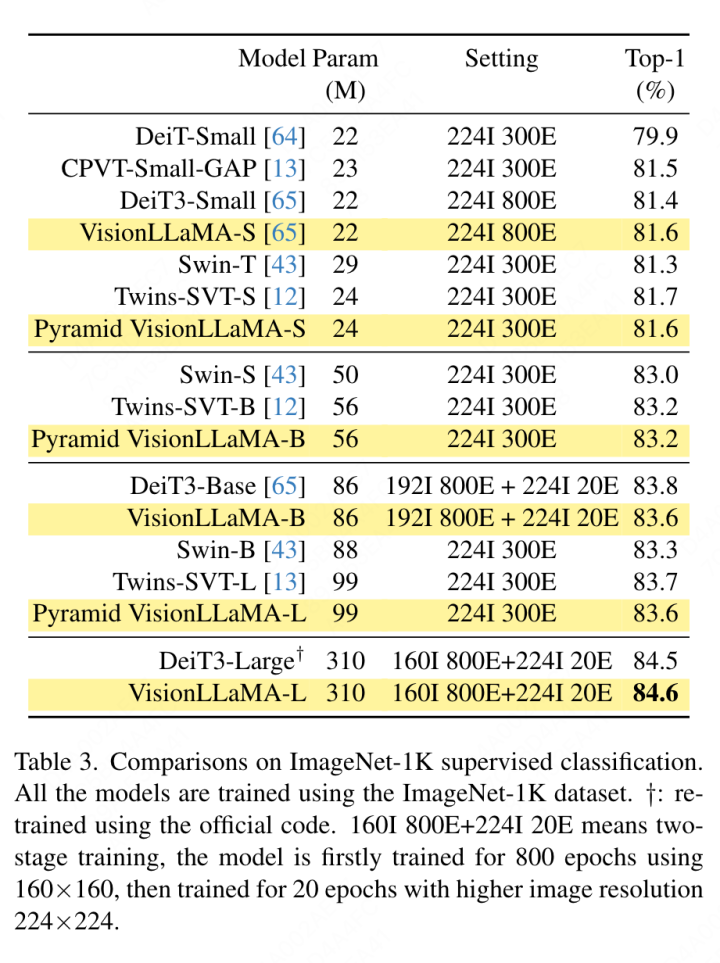
기존 비전 변환기 비교: DeiT3는 특별한 데이터 증강을 제안하고 성능 향상을 위해 광범위한 하이퍼파라미터 검색을 수행하는 최신 최첨단 기존 비전 변환기입니다. DeiT3는 하이퍼파라미터에 민감하며 과적합이 발생하기 쉽습니다. 카테고리 토큰을 GAP(전역 평균 풀링)로 대체하면 DeiT3-Large 모델의 정확도가 800세대 교육 후 0.7% 감소합니다. 따라서 이 기사에서는 일반 변환기에서 GAP 대신 카테고리 토큰을 사용합니다. 결과는 표 3에 나와 있으며, 여기서 VisionLLaMA는 DeiT3에 필적하는 상위 1위 정확도를 달성합니다. 단일 해상도에서의 정확도는 포괄적인 비교를 제공하지 않습니다. 본 논문에서는 다양한 이미지 해상도에서의 성능도 평가하며 그 결과는 표 4에 나와 있습니다. DeiT3의 경우 학습 가능한 위치 인코딩을 위해 쌍삼차 보간법을 사용합니다. 두 모델은 224×224 해상도에서 비슷한 성능을 가지지만 해상도가 증가하면 격차가 넓어집니다. 이는 우리의 방법이 다양한 해상도에서 더 나은 일반화 능력을 가지며 이는 표적 탐지 및 기타 많은 다운스트림 작업에 더 좋습니다.
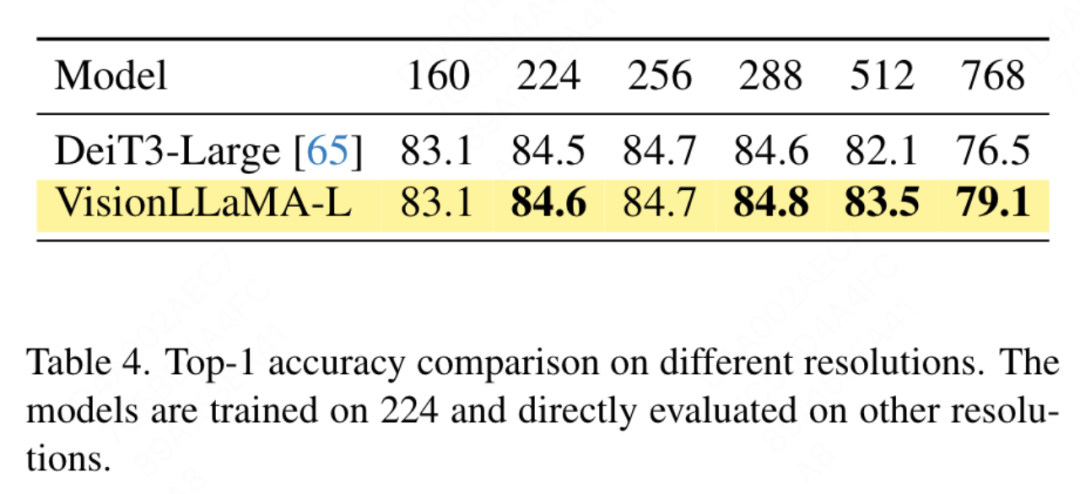
피라미드 구조의 비주얼 트랜스포머 비교: 이 글은 Twins-SVT와 동일한 아키텍처를 사용하며, 자세한 구성은 표 17에 나열되어 있습니다. VisionLLaMA에는 이미 회전 위치 인코딩이 포함되어 있으므로 이 문서에서는 조건부 위치 인코딩을 제거합니다. 따라서 VisionLLaMA는 컨볼루션이 없는 아키텍처입니다. 이 글은 Twins-SVT와 일치하는 Twins-SVT의 하이퍼파라미터를 포함한 모든 설정을 따릅니다. 이 글은 카테고리 토큰을 사용하지 않고 GAP를 적용합니다. 결과는 표 3에 나와 있습니다. 우리의 방법은 모든 모델 수준에서 Twins와 비슷한 성능을 달성하며 항상 Swin보다 우수합니다.
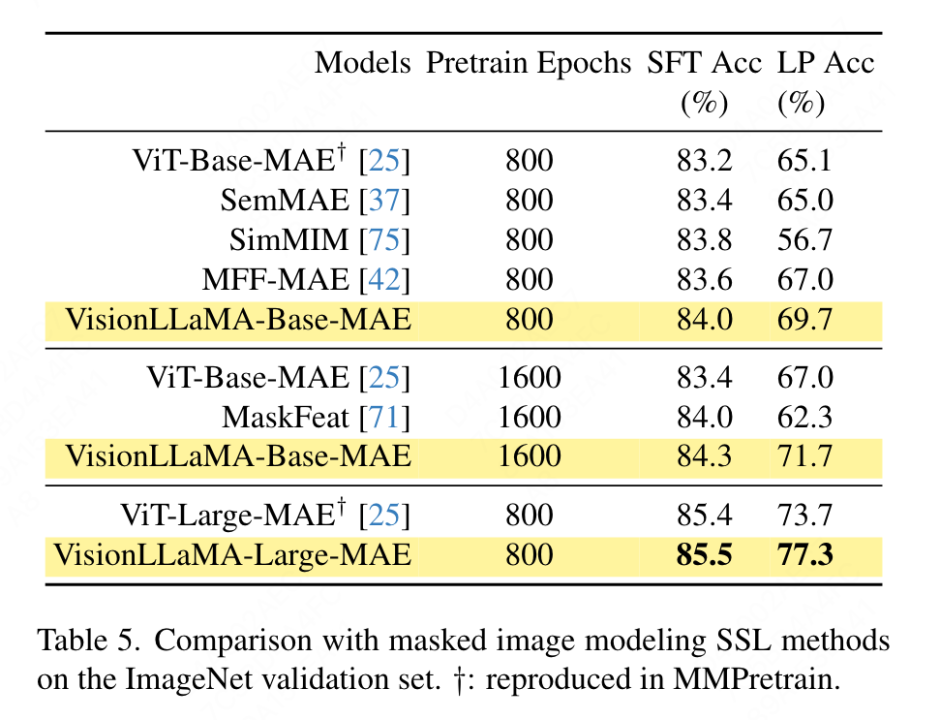
이 기사에서는 ImageNet 데이터 세트를 사용하여 자기 감독 시각적 변환기의 두 가지 일반적인 방법을 평가하는 동시에 훈련 데이터를 ImageNet-1K로 제한하고 CLIP, DALLE 또는 CLIP의 사용을 제거합니다. 성능을 향상시킬 수 있는 구성 요소, 이 기사의 구현은 MMPretrain 프레임워크를 기반으로 하며 MAE 프레임워크를 활용하고 VisionLLaMA를 사용하여 인코더를 교체하는 동시에 다른 구성 요소는 변경하지 않습니다. 이 대조 실험은 이 방법의 효율성을 평가할 수 있습니다. 또한 비교 방법과 동일한 하이퍼 매개변수 설정을 사용하여 강력한 기준에 비해 여전히 상당한 성능 향상을 달성합니다.
전체 미세 조정 설정: 현재 설정에서는 모델이 먼저 사전 훈련된 가중치로 초기화된 다음 완전히 훈련 가능한 매개변수로 추가로 훈련됩니다. VisionLLaMA-Base는 ImageNet에서 800세대 동안 훈련되었으며 ViT-Base보다 0.8% 높은 84.0%의 상위 1 정확도를 달성했습니다. 이 문서의 방법은 SimMIM보다 약 3배 빠르게 학습됩니다. 또한 본 논문에서는 VisionLLaMA가 충분한 훈련 자원으로 장점을 유지할 수 있는지 검증하기 위해 훈련 기간을 1600회로 늘립니다. VisionLLaMA-Base는 ViT-Base에 비해 0.9% 향상된 84.3%의 상위 1 정확도로 MAE 변형 중에서 새로운 SOTA 결과를 달성합니다. Full Fine-Tuning은 성능 포화의 위험이 있다는 점을 고려하면, 이 방법의 개선은 매우 중요합니다.
선형 프로빙: 최근 연구에서는 선형 프로빙 측정항목을 표현 학습에 대한 보다 신뢰할 수 있는 평가로 간주합니다. 현재 설정에서는 모델이 SSL 단계에서 사전 훈련된 가중치로 초기화됩니다. 그런 다음 훈련 중에 분류기 헤드를 제외한 전체 백본 네트워크가 고정됩니다. 결과는 표 5에 나와 있습니다. 800 epoch의 훈련 비용에서 VisionLLaMA-Base는 ViTBase-MAE보다 4.6% 더 나은 성능을 보입니다. 또한 1600세대 동안 훈련된 ViT-Base-MAE보다 성능이 뛰어납니다. VisionLLaMA가 1600 epoch 동안 훈련되면 VisionLLaMA-Base는 71.7%의 최고 정확도를 달성합니다. 이 방법은 VisionLLaMA-Large에도 확장되어 ViT-Large에 비해 3.6% 향상되었습니다.
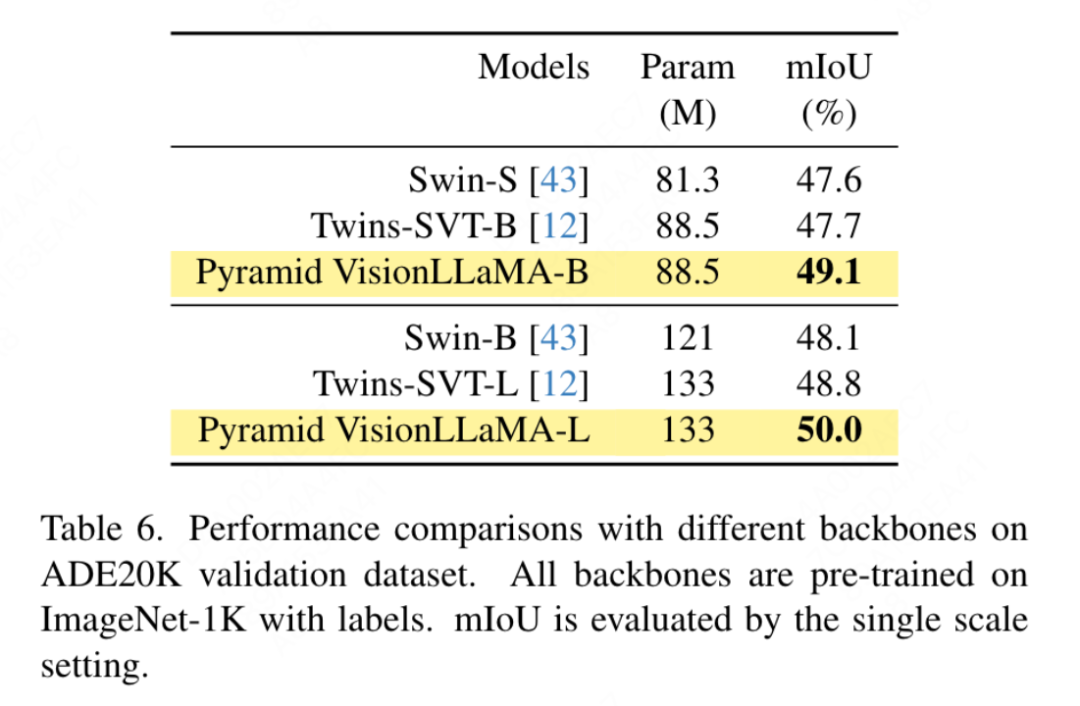
ADE20K 데이터세트의 의미론적 분할
Swin 설정에 따라 이 문서에서는 의미론적 분할을 사용합니다. 이 방법을 평가하기 위한 ADE20K 데이터 세트 효율성의. 공정한 비교를 위해 이 문서에서는 기본 모델을 사전 훈련에만 ImageNet-1K를 사용하도록 제한합니다. 이 기사에서는 UpperNet 프레임워크를 사용하고 백본 네트워크를 피라미드 구조 VisionLLaMA로 대체합니다. 이 문서의 구현은 MMSegmentation 프레임워크를 기반으로 합니다. 모델 훈련 단계 수는 160,000개로 설정되고 전역 배치 크기는 16입니다. 결과는 표 6에 나와 있습니다. 유사한 FLOP에서 우리의 방법은 Swin 및 Twins보다 1.2% mIoU 이상 성능이 뛰어납니다.
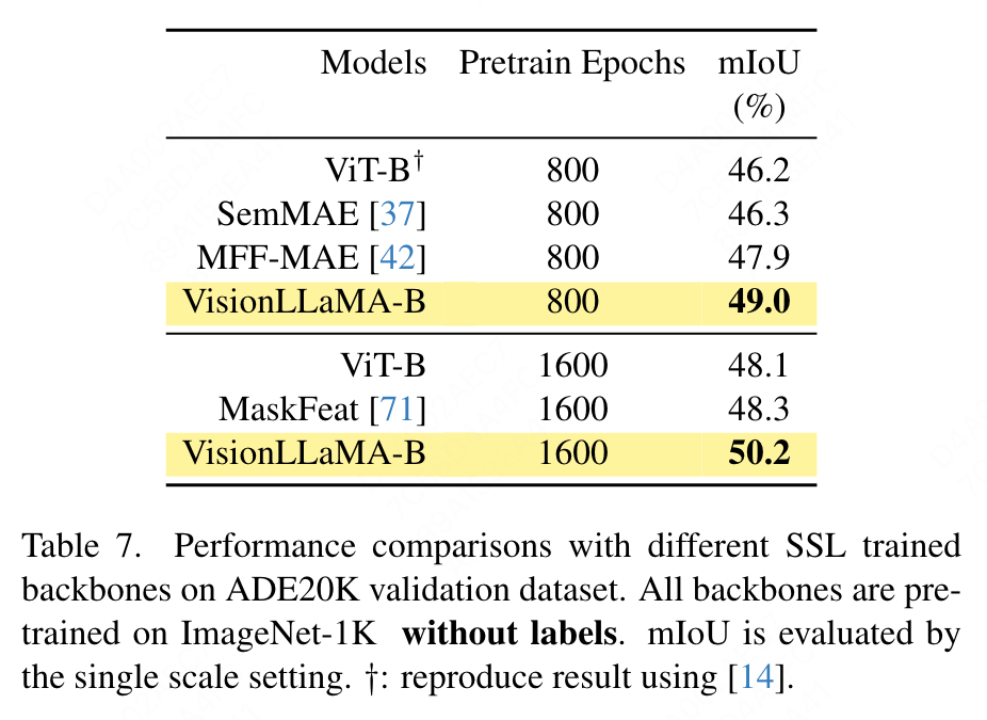
이 문서에서는 ADE20K 데이터세트의 의미론적 분할을 위해 UpperNet 프레임워크를 사용하여 ViT 백본을 VisionLLaMA로 교체하고 다른 구성 요소와 하이퍼 매개변수는 변경하지 않습니다. 본 기사의 구현은 MMSegmentation을 기반으로 하며 그 결과는 표 7에 나와 있습니다. 800개 epoch의 사전 훈련 세트에서 VisionLLaMA-B는 ViT-Base를 2.8% mIoU까지 크게 개선했습니다. 우리의 방법은 또한 추가 훈련 목표 또는 기능을 도입하여 훈련 프로세스에 추가 오버헤드를 가져오고 훈련 속도를 줄이는 등의 다른 개선 사항보다 훨씬 낫습니다. 반면 VisionLLaMA는 기본 모델만 교체하고 학습 속도가 빠릅니다. 이 논문에서는 1600개의 더 긴 사전 훈련 epoch의 성능을 추가로 평가하고 VisionLLaMA-B는 ADE20K 검증 세트에서 50.2% mIoU를 달성하여 ViT-B의 성능을 2.1% mIoU 향상시킵니다.
COCO 데이터 세트의 객체 감지
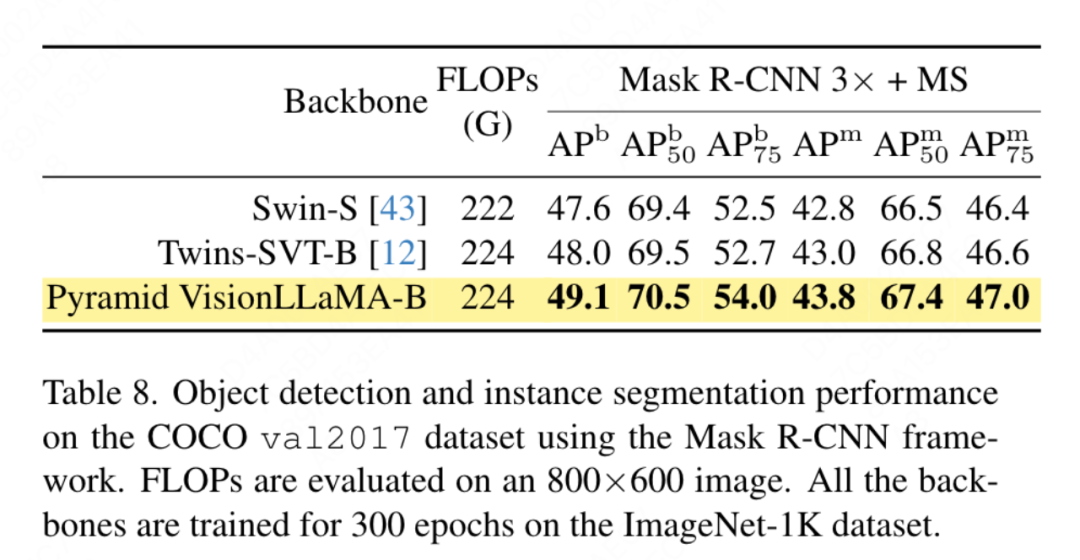
이 문서에서는 CO의 객체 감지 작업에서 피라미드 구조 VisionLLaMA의 성능을 평가합니다. CO 데이터 세트 . 이 백서는 Mask RCNN 프레임워크를 사용하고 Swin의 설정과 유사하게 300 epoch 동안 ImageNet-1K 데이터 세트에서 사전 훈련된 피라미드 구조의 VisionLLaMA로 백본 네트워크를 대체합니다. 따라서 우리 모델은 Twins와 동일한 수의 매개변수 및 FLOP를 갖습니다. 이 실험은 표적 탐지 작업에 대한 이 방법의 효율성을 확인하는 데 사용될 수 있습니다. 이 기사의 구현은 MMDetection 프레임워크를 기반으로 합니다. 표 8은 표준 36 에포크 훈련 주기(3×)의 결과를 보여줍니다. 이 기사의 모델은 Swin 및 Twins보다 낫습니다. 구체적으로 VisionLLaMA-B는 Swin-S보다 1.5% 박스 mAP 및 1.0% 마스크 mAP 성능을 능가합니다. 더 강력한 기준선 Twins-B와 비교하여 우리의 방법은 상자 mAP가 1.1% 더 높고 마스크 mAP가 0.8% 더 높다는 장점이 있습니다.
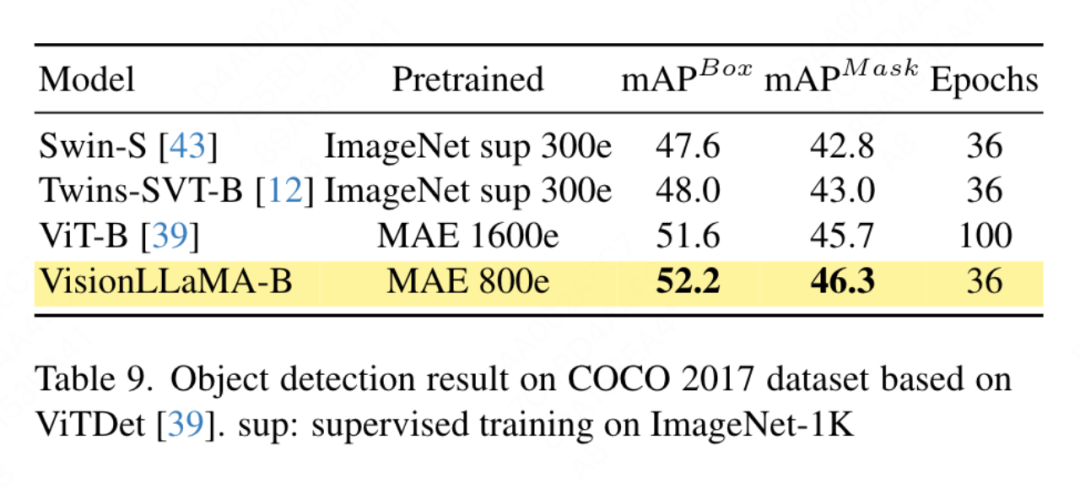
본 논문에서는 ViTDet 프레임워크 기반의 VisionLLaMA를 적용했습니다. ViTDet 프레임워크는 기존 비전 변환기를 활용하여 해당 피라미드 구조 비전 변환기와 비슷한 성능을 달성합니다. 이 논문에서는 Mask RCNN 검출기를 사용하고 vit-Base 백본 네트워크를 800 epoch 동안 MAE로 사전 훈련된 VisionLLaMA-Base 모델로 대체합니다. 원래 ViTDet은 천천히 수렴하며 최적의 성능을 달성하려면 더 긴 훈련 기간과 같은 특수한 훈련 전략이 필요합니다. 훈련 과정에서 VisionLLaMA는 30 epoch 후에 비슷한 성능을 달성했음을 발견했습니다. 따라서 본 논문에서는 표준 3x 훈련 전략을 직접 적용했습니다. 우리 방법의 훈련 비용은 기준선의 36%에 불과합니다. 비교된 방법과 달리 우리의 방법은 최적의 하이퍼파라미터 검색을 수행하지 않습니다. 결과는 표 9에 나와 있습니다. VisionLLaMA는 ViT-B를 박스 mAP에서 0.6%, 마스크 mAP에서 0.8% 능가합니다.
절제 실험
이 기사에서는 기본적으로 ViT-Large 모델에 대한 절제 실험을 수행하는 것으로 설정되었습니다. 실행 분산이 작습니다.
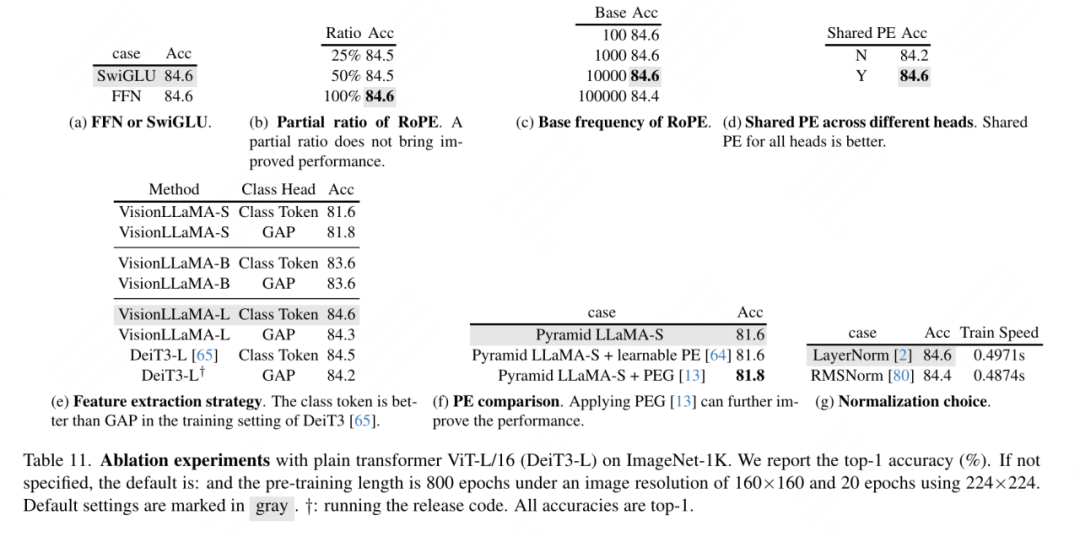
FFN 및 SwiGLU 절제: 이 논문은 FFN을 SwiGLU로 대체하며 결과는 표 11a에 나와 있습니다. 명백한 성능 격차로 인해 이 문서에서는 LLaMA 아키텍처에 대한 추가 수정을 피하기 위해 SwiGLU를 사용하기로 결정했습니다.
정규화 전략 절제: 이 문서에서는 변환기에서 널리 사용되는 두 가지 정규화 방법인 RMSNorm과 LayerNorm을 비교하고 그 결과를 표 11g에 표시합니다. 후자는 더 나은 최종 성능을 가지며, 이는 비전 작업에서 불변성을 다시 중심으로 조정하는 것도 중요하다는 것을 시사합니다. 이 기사에서는 훈련 속도를 측정하기 위해 반복당 소요되는 평균 시간도 계산합니다. 여기서 LayerNorm은 RMSNorm보다 2%만 느립니다. 따라서 이 기사에서는 보다 균형 잡힌 성능을 위해 RMSNorm 대신 LayerNorm을 선택합니다.
부분 위치 인코딩: 이 문서에서는 RoPE를 사용하여 모든 채널의 비율을 조정합니다. 결과는 표 11b에 나와 있습니다. 결과는 비율을 작은 임계값으로 설정하면 좋은 성능을 얻을 수 있으며 서로 다른 채널 간에 큰 차이가 관찰되지 않음을 보여줍니다. 설정 성능 차이. 따라서 이 문서에서는 LLaMA의 기본 설정을 유지합니다.
기본 주파수: 본 논문에서는 기본 주파수를 변경하여 비교하며, 그 결과는 표 11c에 나와 있습니다. 그 결과는 넓은 주파수 범위에서 성능이 견고하다는 것을 보여줍니다. 따라서 이 문서에서는 배포 시 추가적인 특수 처리를 피하기 위해 LLaMA의 기본값을 유지합니다.
각 어텐션 헤드 간 공유 위치 인코딩: 이 논문에서는 서로 다른 헤드 간에 동일한 PE를 공유하는 것(각 헤드의 주파수는 1~10000까지 다양함)이 독립적인 PE(모든 채널의 주파수는 1~10000까지 다양함)보다 낫다는 것을 발견했습니다. ), 결과를 표 11d에 나타내었다.
특성 추상화 전략: 이 문서에서는 대규모 매개변수 규모 모델(-L)에서 두 가지 일반적인 특성 추출 전략인 카테고리 토큰과 GAP를 비교합니다. 결과는 카테고리 토큰을 사용하는 것이 GAP보다 낫습니다. PEG[13]에서 얻은 결론과 다르다. 그러나 두 방법의 훈련 설정은 상당히 다릅니다. 본 논문에서도 DeiT3-L을 사용하여 추가 실험을 수행하여 유사한 결론에 도달했습니다. 이 문서에서는 "소형"(-S) 및 "기본"(-B) 모델의 성능을 추가로 평가합니다. 흥미롭게도, 작은 모델에서는 반대 결론이 관찰되었으며, DeiT3에서 사용된 더 높은 드롭 경로 비율로 인해 GAP와 같은 매개변수 없는 추상화 방법이 원하는 효과를 달성하기 어렵게 만드는 것으로 의심되는 이유가 있습니다.
위치 인코딩 전략: 이 논문에서는 피라미드 구조 VisionLLaMA-S에서 학습 가능한 위치 인코딩 및 PEG와 같은 다른 절대 위치 인코딩 전략도 평가합니다. 강력한 기준이 존재하기 때문에 이 문서에서는 "소형" 모델을 사용하고 결과는 표 11f에 표시됩니다. 학습 가능한 PE는 성능을 향상시키지 않으며 PEG는 기준을 81.6%에서 81.8%로 약간 향상시킵니다. 이 기사에서는 세 가지 이유로 PEG를 필수 구성 요소로 포함하지 않습니다. 첫째, 본 논문에서는 LLaMA에 대한 최소한의 수정을 시도합니다. 둘째, 본 논문의 목적은 ViT와 같은 다양한 업무에 대한 일반적인 접근 방식을 제안하는 것이다. MAE와 같은 마스크된 이미지 프레임워크의 경우 PEG는 교육 비용을 증가시키고 다운스트림 작업의 성능을 저하시킬 수 있습니다. 원칙적으로 MAE 프레임워크에서는 Sparse PEG를 적용할 수 있지만 배포에 적합하지 않은 운영자가 도입됩니다. 희소 컨볼루션이 밀집 버전만큼 많은 위치 정보를 포함하는지 여부는 아직 공개된 질문으로 남아 있습니다. 셋째, 양식이 없는 디자인은 텍스트와 시각적인 것 이상의 다른 양식을 다루는 추가 연구의 길을 열어줍니다.
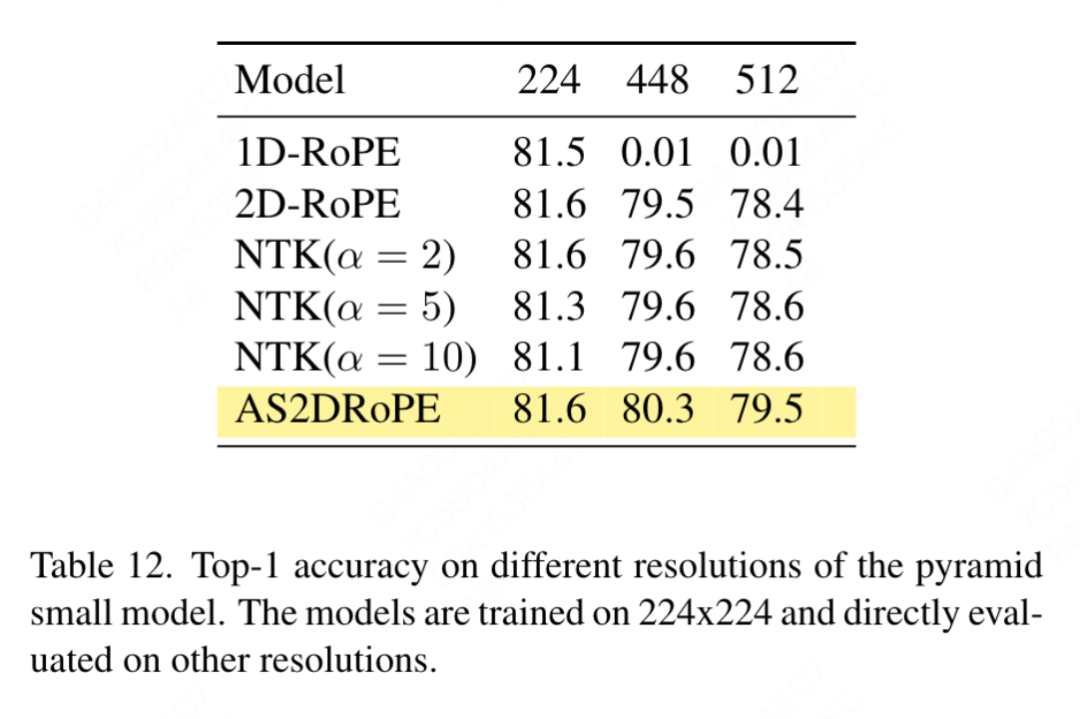
입력 크기에 대한 민감도: 훈련 없이 이 기사에서는 향상된 해상도와 일반 해상도의 성능을 추가로 비교하고 결과를 표 12에 표시합니다. 피라미드 구조 변환기는 상응하는 비계층적 버전보다 다운스트림 작업에 더 널리 사용되기 때문에 여기에서 사용됩니다. 1D-RoPE의 성능이 해상도 변화에 의해 심각한 영향을 받는 것은 놀라운 일이 아닙니다. α = 2인 NTK 인식 보간은 실제로 NTKAware(α = 1)인 2D-RoPE와 유사한 성능을 달성합니다. AS2DRoPE는 더 큰 해상도에서 최고의 성능을 보여줍니다.
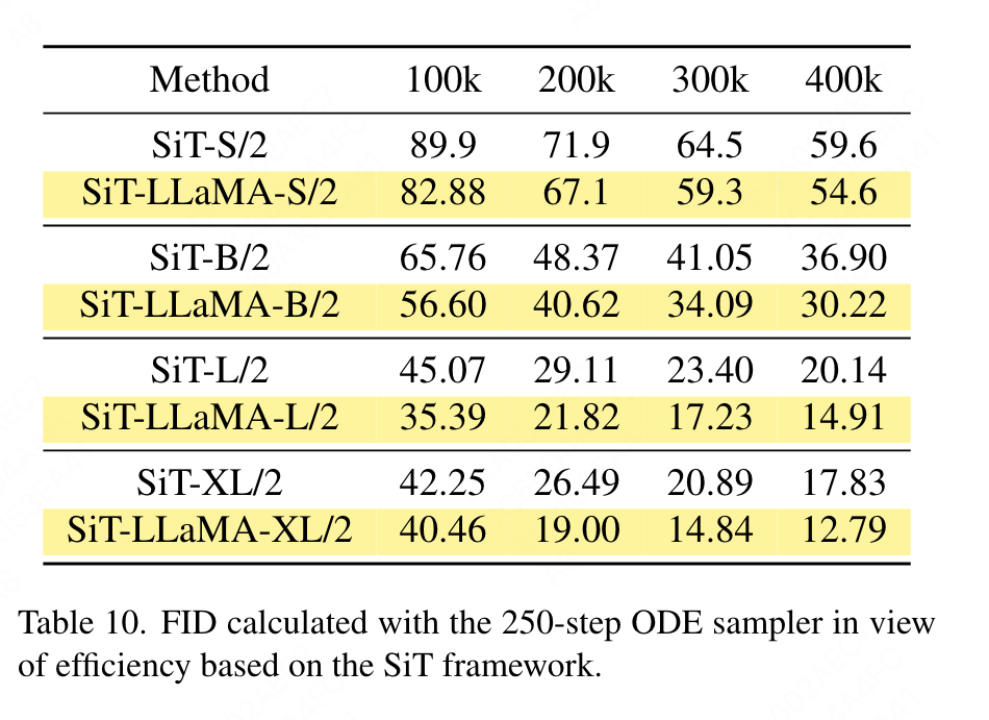
수렴 속도: 이미지 생성의 경우 이 문서에서는 100k, 200k, 300k 및 400k 반복에서 충실도 지수를 계산하기 위해 가중치를 저장하여 다양한 훈련 단계에서 성능을 연구합니다. SDE는 ODE보다 훨씬 느리기 때문에 이 기사에서는 ODE 샘플러를 사용하기로 결정했습니다. 표 10의 결과는 VisionLLaMA가 모든 모델에서 ViT보다 훨씬 빠르게 수렴됨을 보여줍니다. 300,000회 훈련 반복을 수행하는 SiT-LLaMA는 400,000회 훈련 반복을 수행하는 기본 모델보다 성능이 뛰어납니다.
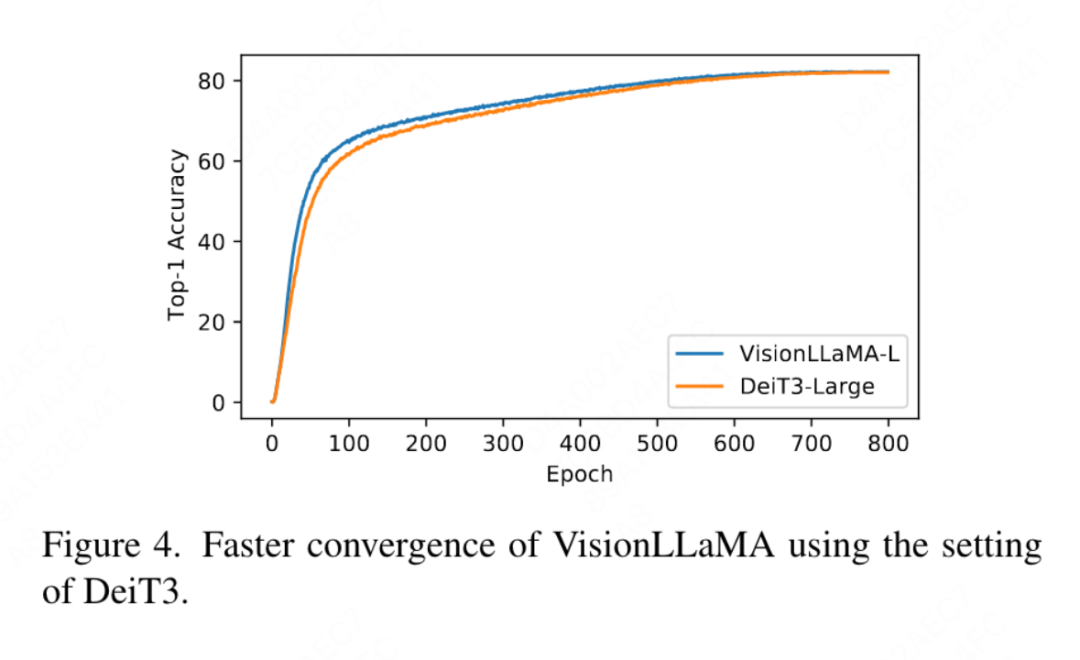
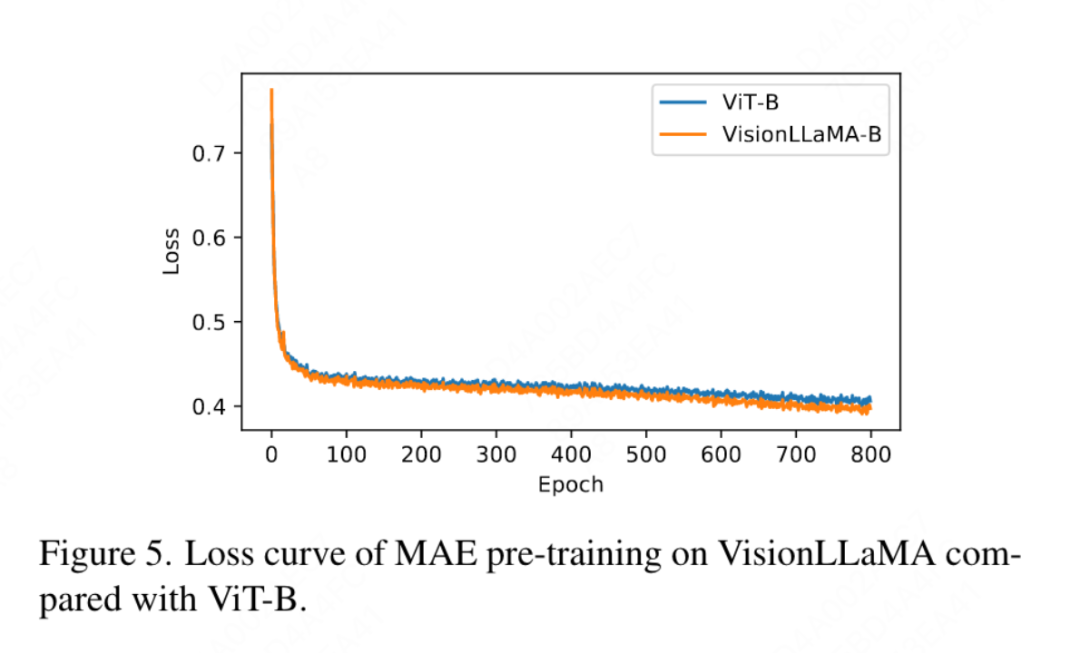
이 문서는 또한 그림 4의 ImageNet에서 DeiT3-Large를 사용한 완전 지도 학습의 800 epoch의 상위 1 정확도와 비교하여 VisionLLaMA가 DeiT3-L보다 빠르게 수렴함을 보여줍니다. 이 논문에서는 MAE 프레임워크에서 ViT-Base 모델의 800 epoch의 훈련 손실을 추가로 비교하고 그림 5에 설명되어 있습니다. VisionLLaMA는 처음에는 훈련 손실이 낮고 끝까지 이러한 추세를 유지합니다.
위 내용은 ViT를 종합적으로 능가하는 Meituan, Zhejiang University 등은 시각적 작업을 위한 통합 아키텍처인 VisionLLAMA를 제안했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



