현재 지능형 대화 모델 개발에서는 강력한 기본 모델이 중요한 역할을 합니다. 이러한 고급 모델의 사전 학습은 고품질의 다양한 말뭉치에 의존하는 경우가 많으며 이러한 말뭉치를 구축하는 방법은 업계에서 주요 과제가 되었습니다. 수학용 AI라는 세간의 이목을 끄는 분야에서는 고품질 수학 코퍼스가 상대적으로 부족하기 때문에 수학 응용 분야에서 생성 인공 지능의 잠재력이 제한됩니다. 이 문제를 해결하기 위해 Shanghai Jiao Tong University의 생성 인공 지능 연구소는 "MathPile"을 출시했습니다. 이는 특히 수학 분야를 대상으로 하는 고품질의 다양한 사전 학습 코퍼스로, 약 95억 개의 토큰을 포함하고 수학적 추론에서 대형 모델의 기능을 향상시키도록 설계되었습니다. 또한 연구실에서는 MathPile의 상용 버전인 "MathPile_Commercial"을 출시하여 응용 범위와 상업적 잠재력을 더욱 확대했습니다. 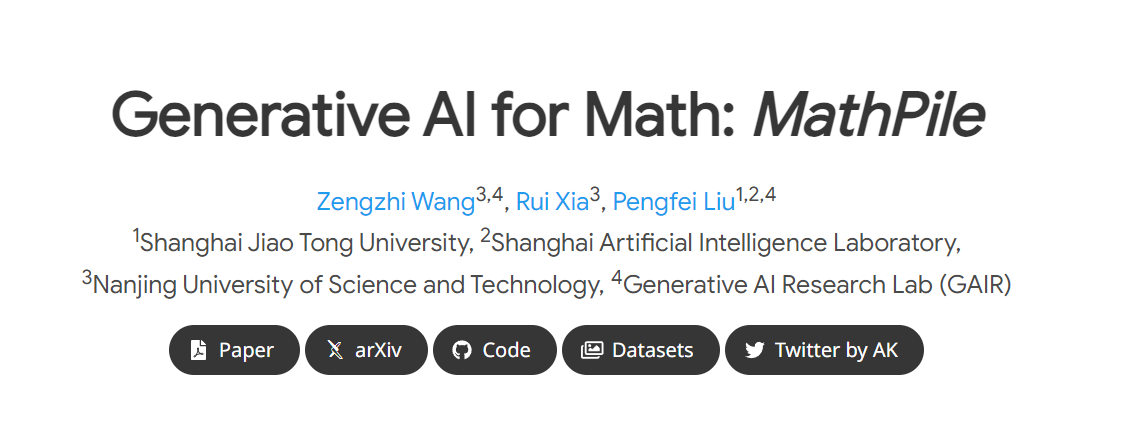
- 연구용도: https://huggingface.co/datasets/GAIR/MathPile
- 상업용 버전: https://huggingface.co/datasets/GAIR/MathPile_Commercial
MathPile에는 다음과 같은 기능이 있습니다. 1. 수학 중심으로
: 과거 Pile, RedPajama, 다국어 코퍼스 ROOTS 등 일반 분야에 집중했던 코퍼스와 달리, MathPile은 수학 분야에 중점을 두고 있습니다. 이미 몇 가지 특수화된 수학 말뭉치가 있지만 오픈 소스가 아니거나(Google이 Minerva를 교육하기 위해 사용하는 말뭉치, OpenAI의 MathMix 등) 풍부하고 다양하지 않습니다(예: ProofPile 및 최근 OpenWebMath). 
Diversity
: MathPile에는 오픈 소스 수학 교과서, 수업 노트, 합성 교과서, arXiv의 수학 관련 논문, Wikipedia의 수학 관련 항목 및 ProofWiki Lemma와 같은 광범위한 데이터 소스가 있습니다. 에 대한 증명 및 정의, 커뮤니티 Q&A 사이트인 StackExchange의 고품질 수학 질문 및 답변, Common Crawl의 수학 웹 페이지. 위 콘텐츠는 초중등학교, 대학교, 대학원생, 수학경시대회 등에 적합한 콘텐츠를 다루고 있습니다. MathPile은 처음으로 고품질 수학 교과서의 0.19B 토큰을 다룹니다.
고품질
: 연구팀은 수집 과정에서 "적을수록 좋다"는 개념을 따르며 사전 훈련 단계에서도 데이터 품질이 양보다 낫다고 굳게 믿습니다. 약 5200억 개의 토큰(약 2.2TB)으로 구성된 데이터 소스에서 엄격하고 복잡한 사전 처리, 사전 필터링, 언어 식별, 정리, 필터링 및 중복 제거 단계를 거쳐 말뭉치의 높은 품질을 보장했습니다. OpenAI에서 사용하는 MathMix에는 15억 개의 토큰만 있다는 점은 언급할 가치가 있습니다.
데이터 문서
: 투명성을 높이기 위해 연구팀은 MathPile을 문서화하고 데이터 세트 시트를 제공했습니다. 연구팀은 데이터 처리 과정에서 웹상의 문서에 '품질 주석'도 수행했다. 예를 들어, 언어 인식 점수와 문서의 기호 대 단어 비율을 통해 연구자는 자신의 필요에 따라 문서를 추가로 필터링할 수 있습니다. 또한 MATH 및 MMLU-STEM과 같은 벤치마크 테스트 세트에서 샘플을 제거하기 위해 코퍼스에서 다운스트림 테스트 세트 오염 감지를 수행했습니다. 동시에 연구팀은 OpenWebMath에 다수의 다운스트림 테스트 샘플이 있다는 사실도 발견했습니다. 이는 잘못된 다운스트림 평가를 피하기 위해 사전 훈련 코퍼스를 생성할 때 특별한 주의를 기울여야 함을 보여줍니다.
MathPile의 데이터 수집 및 처리 프로세스. 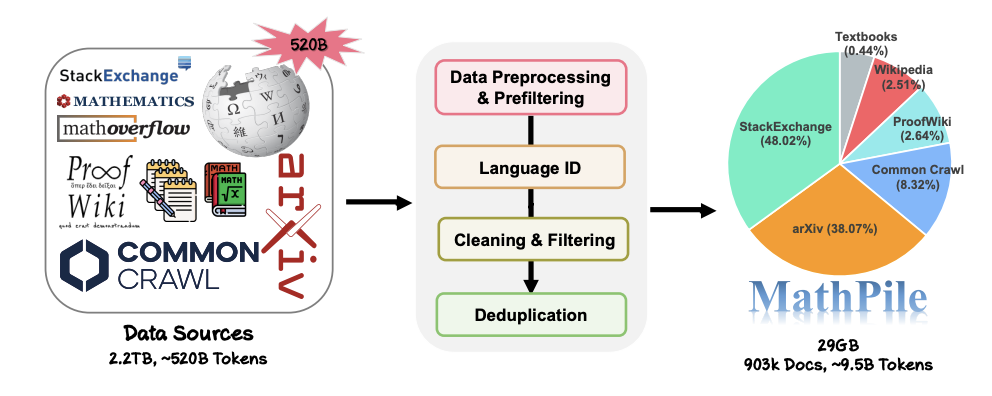
오늘날 대형 모델 분야의 경쟁이 심화됨에 따라 많은 기술 회사에서는 자세한 전처리 세부 정보는 물론 데이터 소스와 비율은 물론 데이터를 더 이상 공개하지 않습니다. 이에 반해 MathPile은 이전 탐색을 바탕으로 Math 분야에 적합한 일련의 데이터 처리 방법을 요약합니다. 데이터 정리 및 필터링 부분에서 연구팀이 채택한 구체적인 단계는 다음과 같습니다.
- 행의 "lorem ipsum"이 less로 대체된 경우. 5자 미만인 경우 줄을 제거합니다.
- "javescript"를 포함하고 "enable", "disable" 또는 "browser"도 포함하고 줄의 문자 수가 200자 미만인 줄을 감지한 다음 필터링합니다. 라인 아웃
- 10단어 미만의 라인을 필터링하고 "로그인", "자세히 보기..." 또는 "장바구니에 있는 항목"을 포함합니다. 대문자 단어가 40% 이상을 차지하는 문서
- 줄임표로 끝나는 줄이 전체 문서의 30% 이상을 차지하는 문서를 필터링합니다.
- 문자가 아닌 단어가 더 많은 문서를 필터링합니다. 80% 이상;
- 평균 영어 단어 길이가 (3, 10) 범위를 벗어나는 문서를 필터링합니다.
- 불용어가 두 개 이상 포함되지 않은 문서를 필터링합니다(예: the, be , to, of, that, have 등 );
- 글머리 기호로 시작하는 줄이 90개를 초과하는 문서를 필터링합니다. %;
- 구두점 뒤의 공백과 200자 미만의 문서를 필터링하고 제거합니다.
- 자세한 처리 세부 사항은 논문에서 확인할 수 있습니다.
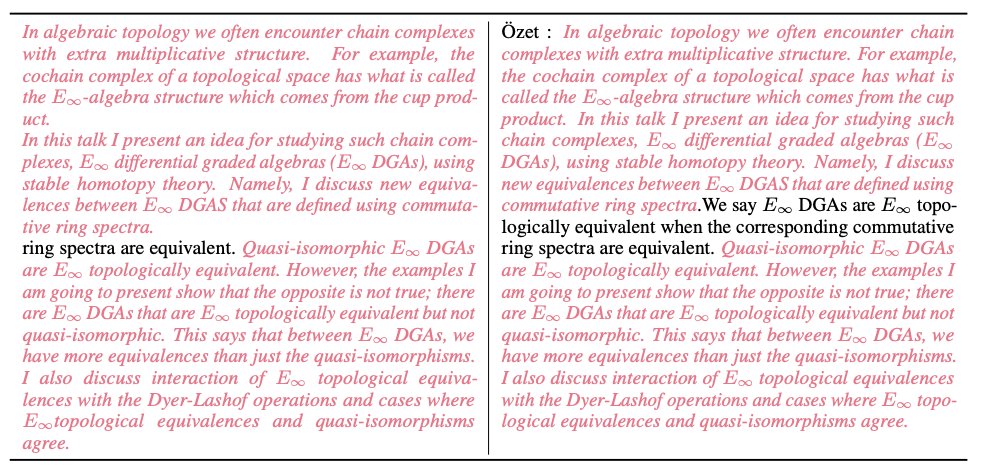
또한 연구팀은 청소 과정에서 많은 데이터 샘플을 제공했습니다. 아래 그림은 MinHash LSH 알고리즘에 의해 감지된 Common Crawl의 거의 중복된 문서를 보여줍니다(분홍색 강조 표시).
아래 그림과 같이 연구팀은 데이터 유출 감지 과정에서 MATH 테스트 세트(노란색으로 표시된 부분)에서 문제점을 발견했습니다.
 데이터 세트 통계 및 예제
데이터 세트 통계 및 예제

다음 표는 MathPile의 각 구성 요소에 대한 통계 정보를 보여줍니다. arXiv 논문과 교과서는 일반적으로 문서 길이가 더 긴 반면, Wiki에 있는 문서는 상대적으로 짧습니다. .
아래 사진은 MathPile 코퍼스의 교과서 샘플 문서입니다. 문서 구조가 비교적 명확하고 품질이 높다는 것을 알 수 있습니다.
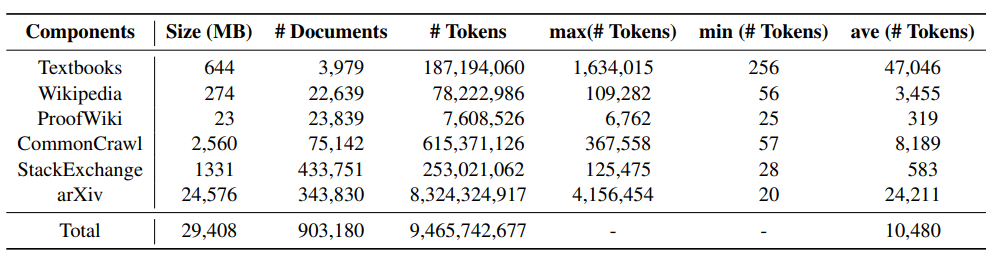
실험 결과 연구팀은 예비 실험 결과도 일부 공개했습니다. 그들은 현재 인기 있는 Mistral-7B 모델을 기반으로 추가 사전 훈련을 수행했습니다. 그런 다음 몇 번의 프롬프트 방법을 통해 몇 가지 일반적인 수학적 추론 벤치마크 데이터 세트에 대해 평가되었습니다. 지금까지 얻은 예비 실험 데이터는 다음과 같습니다.

이 테스트 벤치마크는 초등학교 수학(예: GSM8K, TAL-SCQ5K-EN 및 MMLU-Math)을 포함한 모든 수준의 수학적 지식을 포괄합니다. 학교 수학(예: MATH, SAT -Math, MMLU-Math, AQuA 및 MathQA) 및 대학 수학(예: MMLU-Math). 연구팀이 발표한 예비 실험 결과에 따르면 MathPile에서 교과서와 Wikipedia 하위 집합에 대한 사전 훈련을 계속함으로써 언어 모델이 다양한 난이도 수준에서 수학적 추론 능력이 크게 향상되었음을 보여줍니다.
연구팀도 관련 실험이 아직 진행 중이라는 점을 강조했습니다.
결론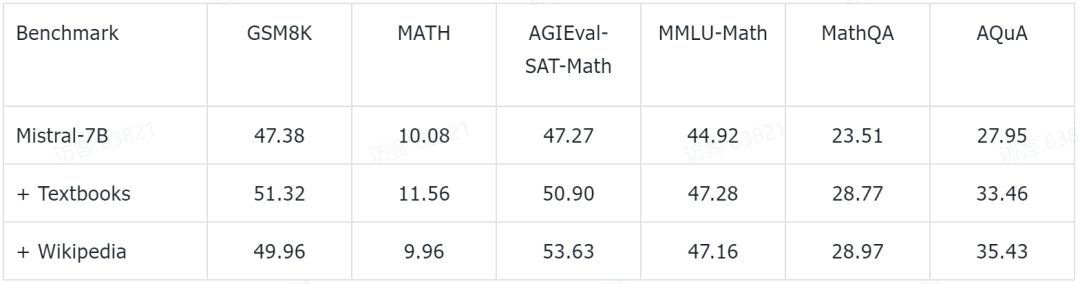
MathPile은 출시 이후 폭넓은 관심을 받았으며 현재 Huggingface Datasets 트렌드 목록에 포함되어 있습니다. 연구팀은 데이터 품질을 더욱 향상시키기 위해 계속해서 데이터 세트를 최적화하고 업그레이드할 것이라고 밝혔습니다. 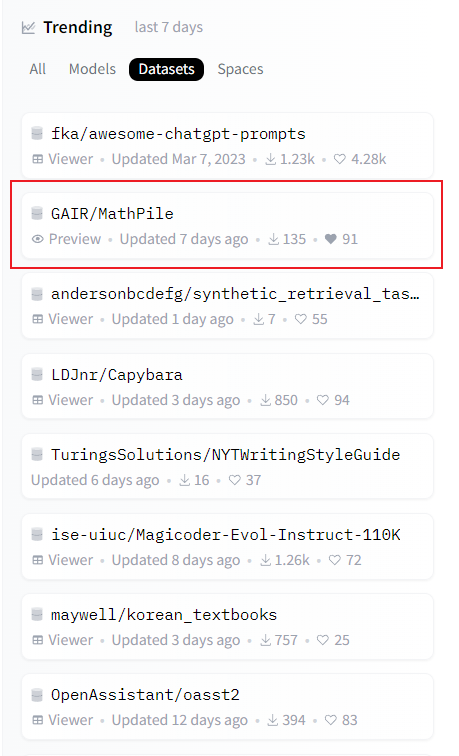
MathPile은 Huggingface 데이터 세트의 인기 목록에 있습니다.  MathPile은 유명한 AI 블로거 AK에 의해 전달되었습니다. 출처: https://twitter.com/_akhaliq/status/1740571256234057798.
MathPile은 유명한 AI 블로거 AK에 의해 전달되었습니다. 출처: https://twitter.com/_akhaliq/status/1740571256234057798.
현재 MathPile은 오픈 소스 커뮤니티의 연구 개발에 기여하는 것을 목표로 두 번째 버전으로 업데이트되었습니다. 동시에 데이터 세트의 상용 버전도 대중에게 공개되었습니다. 위 내용은 대형 모델의 수학을 보완하려면 상업적으로도 사용할 수 있는 95억 개의 토큰이 포함된 오픈 소스 MathPile 코퍼스를 제출하세요.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!



















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



