

Chen Danqi 팀은 방금 새로운 LLM컨텍스트 창 확장방법을 출시했습니다.
훈련용 8k 토큰 문서만 사용하여 Llama-2 창을 128k로 확장할 수 있습니다.
가장 중요한 것은 이 과정에서 모델에 원본 메모리의 1/6만 필요하고 모델이 10배의 처리량을 달성한다는 것입니다.
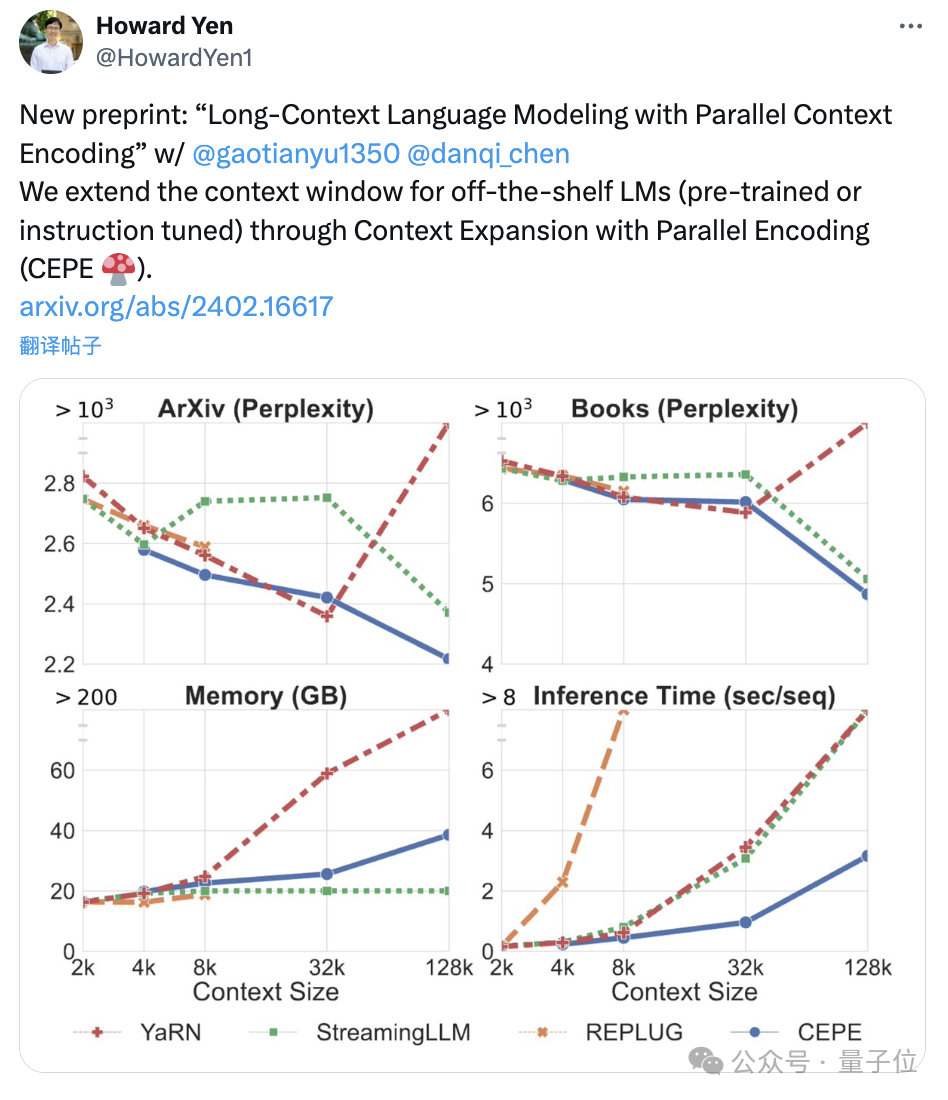
또한 교육 비용을 크게 줄일 수 있습니다:
이 방법을 사용하여 7B 알파카 2를 변환하려면 A100 조각만 필요합니다.
팀에서는 다음과 같이 말했습니다.
이 방법이 유용하고 사용하기 쉬우며 향후 LLM에 저렴하고 효과적인긴 컨텍스트 기능을 제공할 수 있기를 바랍니다.
현재 모델과 코드는 HuggingFace와 GitHub에 게시되어 있습니다.
이 메서드는 CEPE라고 하며, 전체 이름은 "Context Expansion with Parallel Encoding(Context Expansion with Parallel Encoding)"입니다.
경량 프레임워크로서 모든사전 훈련 및 지침 미세 조정모델의 컨텍스트 창을 확장하는 데 사용할 수 있습니다.
사전 훈련된 디코더 전용 언어 모델의 경우 CEPE는 두 개의 작은 구성 요소를 추가하여 이를 확장합니다.하나는 블록 인코딩 긴 컨텍스트를 위한 작은 인코더
하나는 교차 주의 강제 모듈, 삽입됨 디코더의 각 계층에 포함되어 인코더 표현에 초점을 맞추는 데 사용됩니다.
전체 아키텍처는 다음과 같습니다.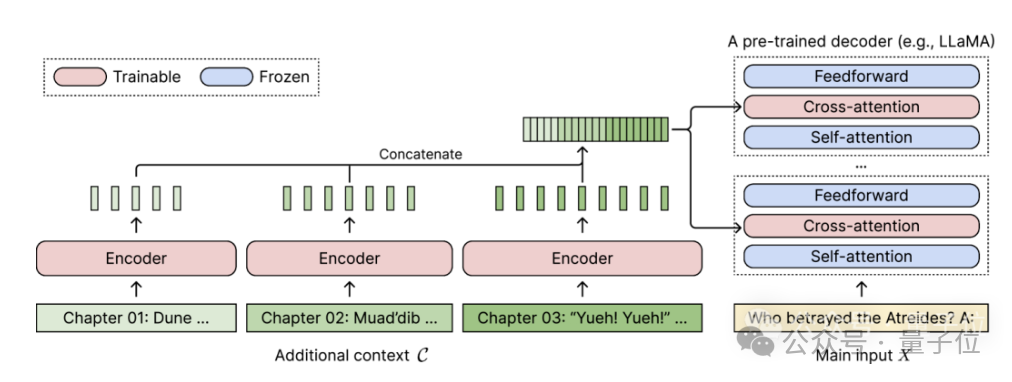
(1) 위치 인코딩에 제약을 받지 않기 때문에 길이가 일반화 가능합니다
. 반대로 컨텍스트가 분할되어 인코딩되며 각 세그먼트는 자체 위치 인코딩이 있습니다.(2) 고효율작은 인코더와 병렬 인코딩을 사용하여 컨텍스트를 처리하면 계산 비용을 줄일 수 있습니다.
(3) 훈련 비용 절감
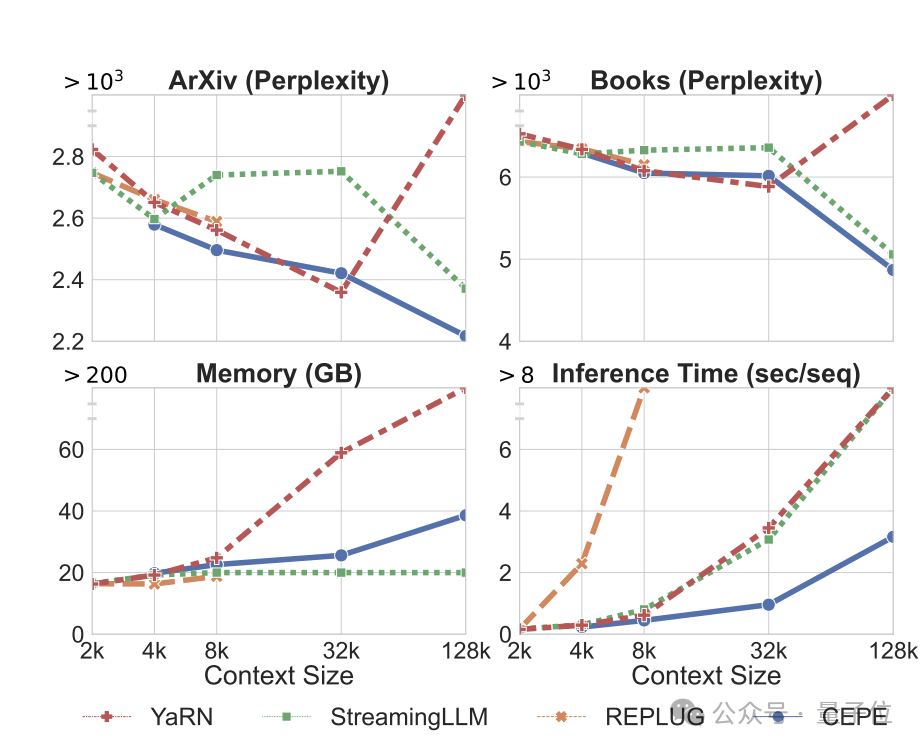
으로 확장하면 80GB A100 GPU로 완성될 수 있다고 소개했습니다. Perplexity는 계속해서 감소합니다
. 첫째, 완전히 미세 조정된 두 모델인 LLAMA2-32K 및 YARN-64K와 비교하여 CEPE는 모든 데이터 세트에서 더 낮거나 비슷한
perplexity를 달성하는 동시에 메모리 사용률은 낮고 처리량은 더 높습니다.
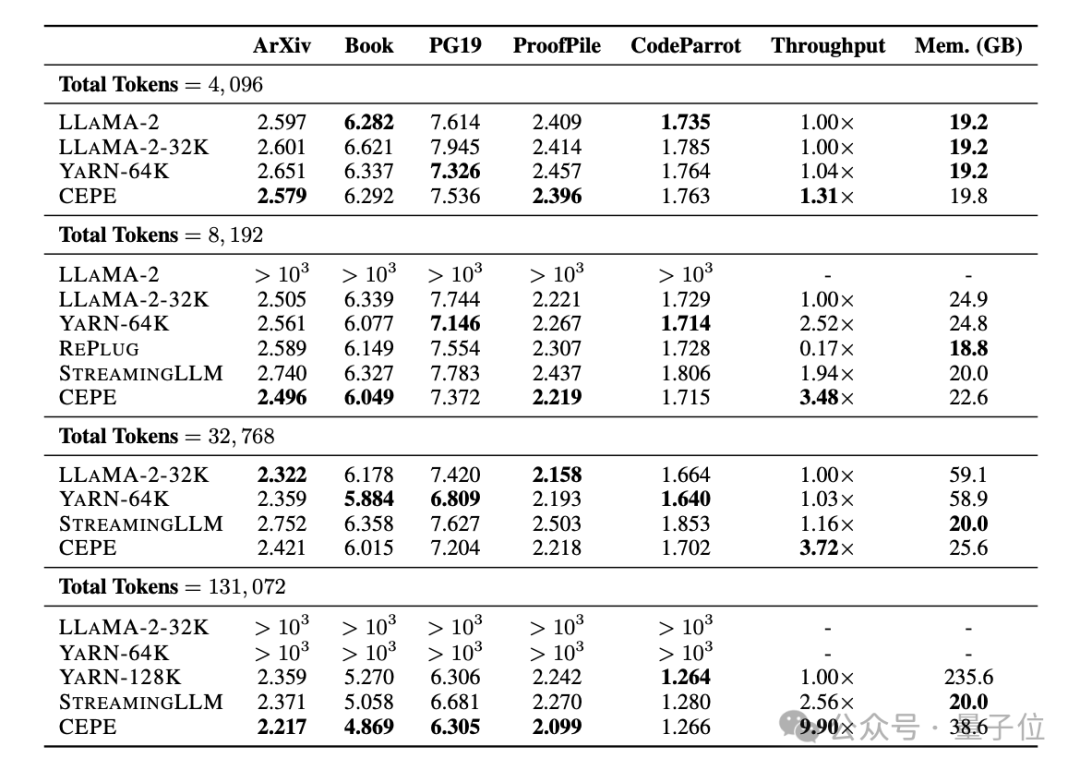 컨텍스트가 128k로 증가하면
컨텍스트가 128k로 증가하면
, CEPE의 혼란은 낮은 메모리 상태를 유지하면서 계속 감소합니다. 반대로, Llama-2-32K와 YARN-64K는 훈련 기간 이상으로 일반화하는 데 실패할 뿐만 아니라 메모리 비용도 크게 증가합니다.
 둘째,
둘째,
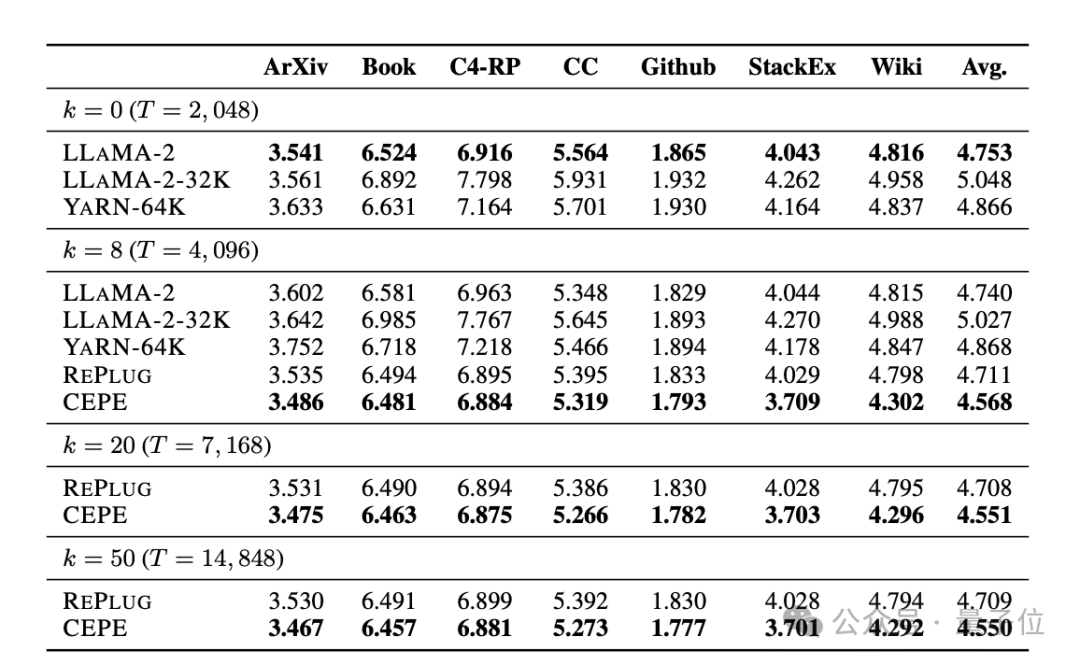
검색 기능이 향상되었습니다. 다음 표에 표시된 대로:
검색된 컨텍스트를 사용하여 CEPE는 모델의 복잡성을 효과적으로 개선하고 RePlug보다 더 나은 성능을 발휘할 수 있습니다.
단락 k=50(훈련은 60)이라 하더라도 CEPE는 계속해서 당혹감을 개선할 것이라는 점에 주목할 필요가 있습니다.
이는 CEPE가 검색 향상 설정으로 잘 전송되는 반면 전체 컨텍스트 디코더 모델은 이 기능이 저하됨을 보여줍니다.
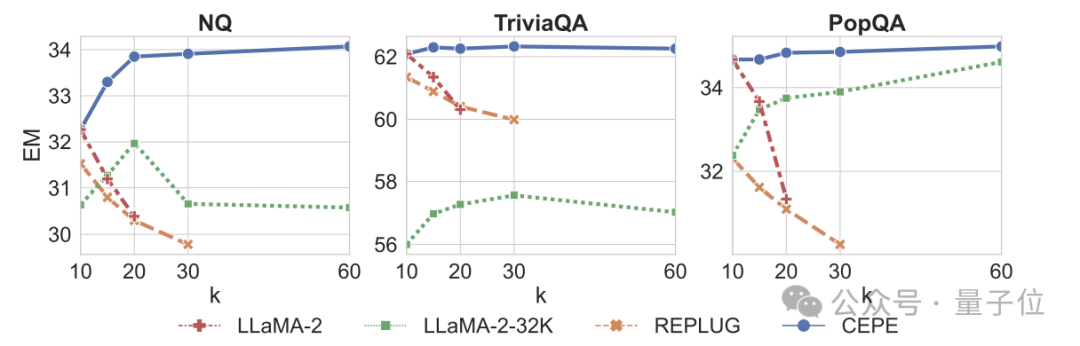
셋째, 오픈 도메인 질문 및 답변 기능을 대폭 뛰어 넘었습니다.
아래 그림에서 볼 수 있듯이 CEPE는 모든 데이터 세트와 k항 매개변수에서 다른 모델보다 월등히 우수하며, 다른 모델과 달리 k 값이 커질수록 성능이 크게 떨어집니다.
이는 또한 CEPE가 많은 양의 중복되거나 관련 없는 단락에 민감하지 않음을 보여줍니다.
요컨대 CEPE는 대부분의 다른 솔루션에 비해 훨씬 낮은 메모리와 계산 비용으로 위의 모든 작업에서 뛰어난 성능을 발휘합니다.
마지막으로 저자는 이러한 기반을 바탕으로 특히 지침 튜닝 모델을 위해 CEPE-Distilled(CEPED)을 제안했습니다.
레이블이 지정되지 않은 데이터만 사용하여 모델의 컨텍스트 창을 확장하고 보조 KL 발산 손실을 통해 원래 명령 조정 모델의 동작을 새로운 아키텍처로 추출하므로 비용이 많이 드는 긴 컨텍스트 명령 추적 데이터를 관리할 필요가 없습니다.
궁극적으로 CEPED는 Llama-2의 컨텍스트 창을 확장하고 지침을 이해하는 능력을 유지하면서 모델의 긴 텍스트 성능을 향상시킬 수 있습니다.
CEPE의 저자는 총 3명입니다.
한 명은 프린스턴 대학에서 컴퓨터 과학 석사 과정을 밟고 있는 Yan Heguang(Howard Yen)입니다.
두 번째 사람은 같은 학교의 박사 과정 학생이자 칭화대학교 학사 학위를 취득한 Gao Tianyu입니다.
모두 교신저자인 Chen Danqi 선생님의 학생들입니다.

논문 원문: https://arxiv.org/abs/2402.16617
참조 링크: https://twitter.com/HowardYen1/status/1762474556101661158
위 내용은 Chen Danqi 팀의 새로운 작업: Llama-2 컨텍스트가 128k로 확장되고 10배 처리량에는 메모리의 1/6만 필요의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



