

대형 모델들이 속속 투입되면서 트랜스포머의 위상도 잇따라 도전받고 있습니다.
최근 RWKV는 최신 RWKV-v5 아키텍처를 기반으로 하는 Eagle 7B 모델을 출시했습니다.
Eagle 7B는 다국어 벤치마크에서 탁월하며 영어 테스트에서도 상위 모델과 동등합니다.
동시에 Eagle 7B는 동일한 크기의 Transformer 모델에 비해 추론 비용이 10~100배 이상 절감되는 가장 환경 친화적인 7B라고 할 수 있습니다. 세계의 모델.
RWKV-v5에 대한 논문은 다음 달까지 공개되지 않을 수 있으므로 매개변수를 수백억 개로 확장할 수 있는 최초의 비 Transformer 아키텍처인 RWKV에 대한 논문을 먼저 제공합니다.
 Pictures
Pictures
문서 주소: https://arxiv.org/pdf/2305.13048.pdf
EMNLP 2023에서 이 작품을 승인했습니다. 저자는 전 세계 최고의 대학, 연구 기관 및 기술 분야에서 왔습니다. 세계.회사.
다음은 이 독수리가 트랜스포머 위를 날고 있는 모습을 담은 이글 7B의 공식 사진입니다.
 Pictures
Pictures
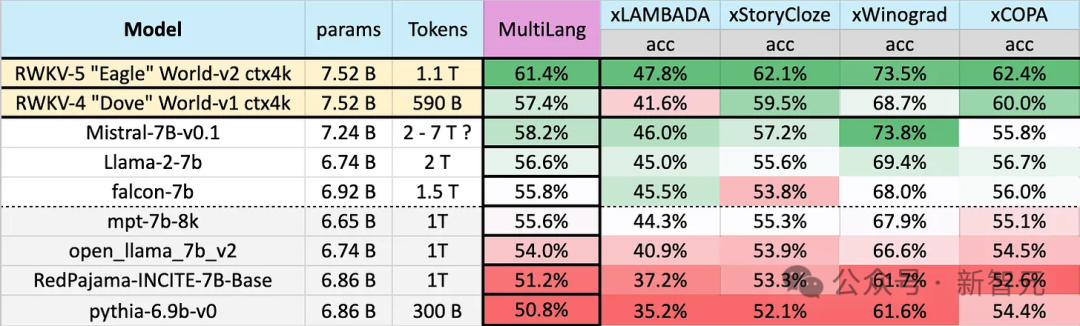
Eagle 7B는 100개 이상의 언어에서 얻은 1.1T(조) 토큰의 학습 데이터를 사용합니다. 아래 다중 언어 벤치마크 테스트에서 Eagle 7B가 평균 1위를 차지했습니다.
벤치마크에는 xLAMBDA, xStoryCloze, xWinograd 및 xCopa가 포함되어 있으며 23개 언어와 각 언어의 상식적 추론을 다루고 있습니다.
Eagle 7B는 그 중 3개에서 1위를 차지했습니다. 그 중 한 개가 Mistral-7B를 이기지 못하고 2위를 차지했지만, 상대가 사용한 훈련 데이터는 Eagle보다 훨씬 높았습니다.
 Pictures
Pictures
아래 그림의 영어 테스트에는 12개의 개별 벤치마크, 상식 추론, 세계 지식이 포함되어 있습니다.
영어 성능 테스트에서 Eagle 7B의 수준은 Falcon(1.5T), LLaMA2(2T), Mistral(>2T)에 가깝고 약 1T 훈련을 사용하는 MPT-7B와도 비슷합니다. 데이터.
 Pictures
Pictures
그리고 두 테스트 모두에서 새로운 v5 아키텍처는 이전 v4에 비해 전체적으로 크게 도약했습니다.
Eagle 7B는 현재 Linux Foundation에서 호스팅되며 무제한 개인 또는 상업적 용도로 Apache 2.0 라이선스에 따라 라이선스가 부여됩니다.
앞서 언급했듯이 Eagle 7B의 교육 데이터는 100개 이상의 언어에서 나온 반면 위에서 사용된 4개의 다국어 벤치마크에는 23개 언어만 포함됩니다.
 Pictures
Pictures
전체적으로 1위를 달성했지만 전체적으로 Eagle 7B는 손실을 입었습니다. 결국 벤치마크 테스트에서는 70개 이상의 다른 언어에서 모델의 성능을 직접 평가할 수 없습니다.
추가 교육 비용은 순위 향상에 도움이 되지 않습니다. 영어에 집중한다면 지금보다 더 나은 결과를 얻을 수 있습니다.
——그럼 RWKV는 왜 이런 일을 하는 걸까요? 공식은 다음과 같이 말했습니다:
영어뿐만 아니라 이 세계의 모든 사람을 위한 포괄적인 AI 구축
RWKV 모델에 대한 많은 피드백 중에서 가장 일반적인 것은 다음과 같습니다.
다국어 접근 방식은 해를 끼칩니다. 모델의 영어 평가 점수로 인해 선형 Transformer의 개발 속도가 느려졌습니다.
다국어 성능을 순수 영어 모델과 비교하는 것은 불공평합니다.
공식적으로 "대부분의 경우 이러한 의견에 동의합니다. "
"하지만 우리는 전 세계를 위한 AI를 구축하고 있기 때문에 이를 바꿀 계획이 없습니다. 이는 단순한 영어권 세계가 아닙니다."
 Pictures
Pictures
2023년에는 세계 인구 영어를 사용하는 사람(약 13억 명)이 세계 상위 25개 언어를 지원함으로써 모델은 약 40억 명, 즉 세계 인구의 50%에 도달할 수 있습니다.
팀은 모델이 더 많은 언어를 지원하는 등 저렴한 가격으로 저사양 하드웨어에서 실행될 수 있도록 하는 등 미래의 인공지능이 모든 사람에게 도움이 될 수 있기를 바라고 있습니다.
팀은 더 넓은 범위의 언어를 지원하기 위해 다국어 데이터 세트를 점진적으로 확장하고 전 세계 100% 지역으로 적용 범위를 천천히 확장하여 어떤 언어도 제외되지 않도록 할 것입니다.
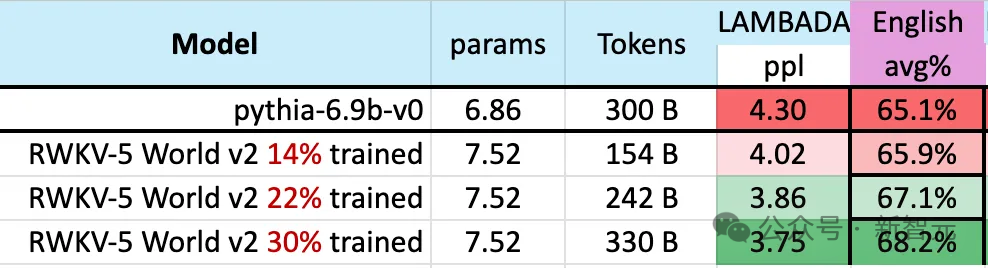
모델 교육 과정에서 주목할 만한 현상이 있습니다.
교육 데이터의 규모가 계속 증가함에 따라 모델 성능이 점차 향상됩니다. 학습 데이터가 약 300B에 도달하면 모델은 학습 데이터 크기가 300B인 python-6.9b와 유사한 성능을 나타냅니다.
 Picture
Picture
이 현상은 이전에 RWKV-v4 아키텍처에서 수행한 실험과 동일합니다. 즉, 훈련 데이터 크기가 동일할 때 RWKV와 같은 선형 변환기의 성능은 동일할 것입니다. 트랜스포머와 비슷하다.
그래서 이것이 사실이라면 모델의 성능 향상에 정확한 아키텍처보다 데이터가 더 중요한지 묻지 않을 수 없습니다.
 Picture
Picture
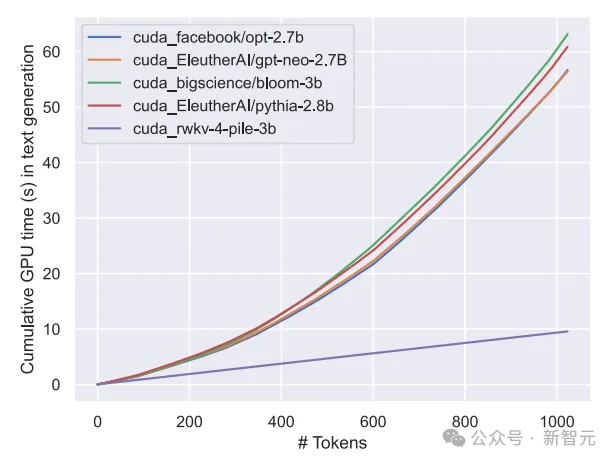
Transformer 클래스 모델의 계산 및 저장 비용은 제곱 수준인 반면, 위 그림에서 RWKV 아키텍처의 계산 비용은 토큰 수에 따라 선형적으로만 증가한다는 것을 알고 있습니다.
아마도 우리는 접근성을 높이고 모든 사람을 위한 AI 비용을 낮추며 환경에 미치는 영향을 줄이기 위해 더 효율적이고 확장 가능한 아키텍처를 찾아야 할 것입니다.
RWKV 아키텍처는 GPT 수준의 LLM 성능을 갖춘 RNN이면서도 Transformer처럼 병렬로 학습할 수 있습니다.
RWKV는 뛰어난 성능, 빠른 추론, 빠른 훈련, VRAM 절약, "무제한" 컨텍스트 길이 및 자유 문장 임베딩 등 RNN과 Transformer의 장점을 결합합니다.
다음 그림은 RWKV와 Transformer 모델의 계산 비용을 비교한 것입니다.
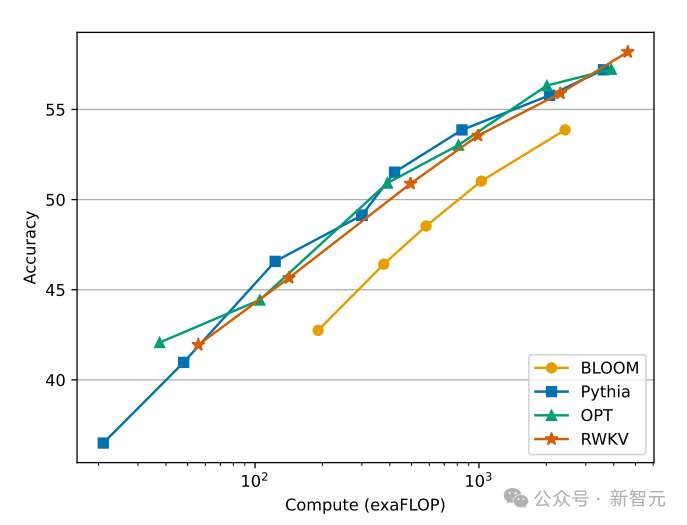 Pictures
Pictures
Transformer의 시간 및 공간 복잡성 문제를 해결하기 위해 연구자들은 다양한 아키텍처를 제안했습니다.
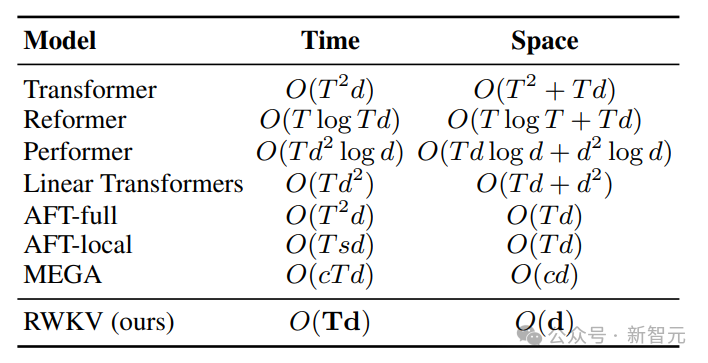 Picture
Picture
RWKV 아키텍처는 일련의 누적된 잔여 블록으로 구성됩니다. 각 잔여 블록은 루프 구조의 시간적 믹싱 하위 블록과 채널 믹싱 하위 블록으로 구성됩니다
왼쪽 아래 그림은 RWKV 블록 요소이며 오른쪽에 RWKV 잔여 블록이 있고 언어 모델링을 위한 최종 헤더가 있습니다.
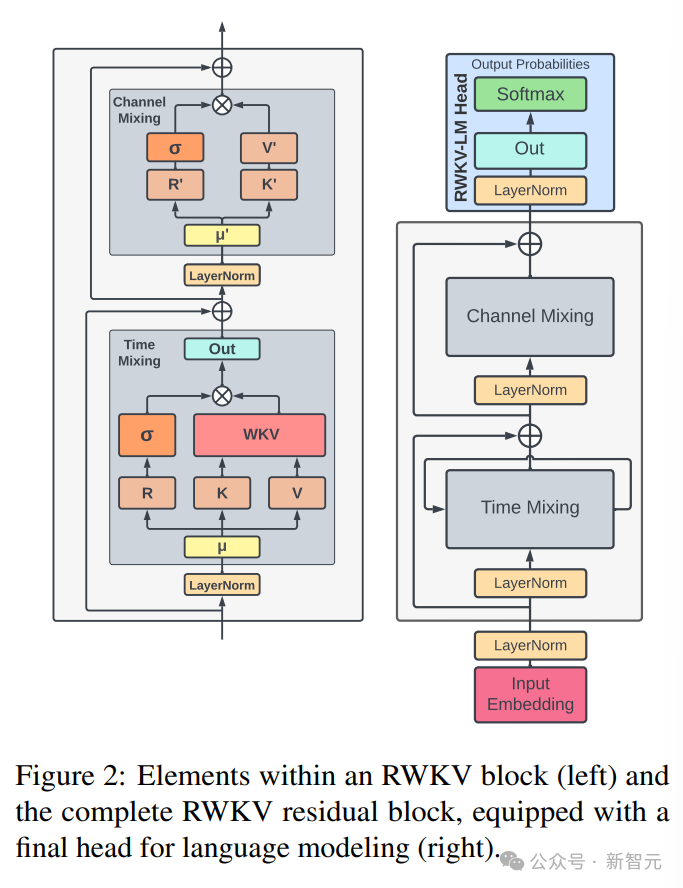 Picture
Picture
재귀는 현재 입력과 이전 시간 단계의 입력 사이의 선형 보간으로 표현될 수 있습니다(아래 그림의 대각선으로 표시됨). 이는 각 선형에 대해 독립적일 수 있습니다. 입력 임베딩 조정의 투영.
현재 토큰을 별도로 처리하는 벡터도 여기에 도입되어 잠재적인 성능 저하를 보상합니다.
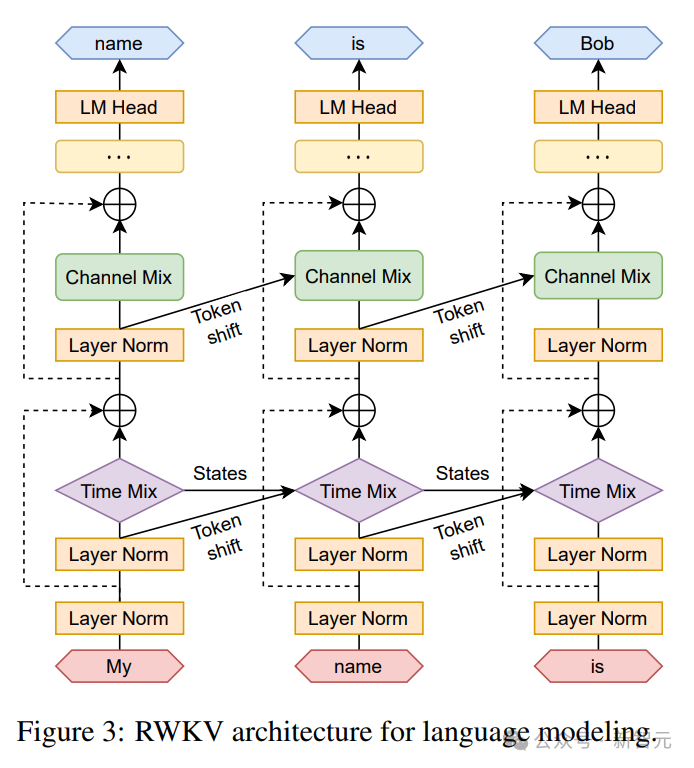 Pictures
Pictures
RWKV는 시간적 병렬 모드라고 부르는 방식으로 효율적으로 병렬화(행렬 곱셈)할 수 있습니다.
순환 네트워크에서는 일반적으로 이전 순간의 출력이 현재 순간의 입력으로 사용됩니다. 이는 다음 단계가 입력되기 전에 각 토큰을 계산해야 하는 언어 모델에 대한 자동 회귀 디코딩 추론에서 특히 두드러지며, 이를 통해 RWKV는 시간 모드라고 하는 RNN과 유사한 구조를 활용할 수 있습니다.
이 경우 RWKV는 추론 중 디코딩을 위해 편리하게 공식화할 수 있습니다. 와 달리 상태의 크기는 일정합니다.
그런 다음 RNN 디코더 역할을 하여 시퀀스 길이에 비해 일정한 속도와 메모리 공간을 제공하여 더 긴 시퀀스를 보다 효율적으로 처리할 수 있습니다.
반대로, self-attention의 KV 캐시는 시퀀스 길이에 비해 지속적으로 증가하므로 시퀀스가 길어짐에 따라 효율성이 감소하고 메모리 공간과 시간이 늘어납니다.
참조:
위 내용은 RNN 모델은 Transformer 헤게모니에 도전합니다! Mistral-7B에 필적하는 1% 비용 및 성능, 세계에서 가장 많은 100개 이상의 언어 지원의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



