

연결된 목록은 정렬된 데이터를 구성하는 데 일반적으로 사용되는 데이터 구조입니다. 일련의 데이터 노드를 포인터를 통해 데이터 체인으로 연결하며 선형 테이블의 중요한 구현 방법입니다. 배열에 비해 연결리스트는 더 역동적입니다. 연결리스트를 구축할 때, 데이터의 총량을 미리 알 필요가 없고, 공간을 임의로 할당할 수 있으며, 연결리스트의 어느 위치에나 실시간으로 데이터를 효율적으로 삽입하거나 삭제할 수 있다. 연결 목록의 주요 오버헤드는 액세스의 연속성과 체인 구성에 따른 공간 손실입니다.
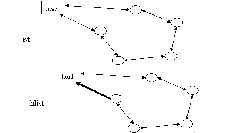
일반적으로 연결된 목록 데이터 구조에는 데이터 필드와 포인터 필드라는 두 개 이상의 필드가 포함되어야 합니다. 데이터 필드는 데이터를 저장하는 데 사용되고 포인터 필드는 다음 노드와의 연결을 설정하는 데 사용됩니다. 연결리스트는 포인터 필드의 구성과 각 노드 간의 연결 형태에 따라 단일 연결리스트, 이중 연결리스트, 순환 연결리스트 등 다양한 유형으로 나눌 수 있다. 다음은 이러한 일반적인 연결 목록 유형의 도식적 다이어그램입니다.
단일 연결 리스트는 가장 간단한 유형의 연결 리스트입니다. 후속 노드(다음)를 가리키는 포인터 필드가 하나만 있다는 것이 특징입니다. 따라서 단일 연결 리스트는 처음부터 끝까지 순차적으로만 탐색할 수 있습니다(보통 NULL 포인터). ).
선행자와 후행자의 두 포인터 필드를 설계함으로써 이중 연결 목록은 두 방향에서 탐색할 수 있으며, 이것이 단일 연결 목록과 구별됩니다. 선행 노드와 후속 노드 간의 종속 관계가 중단되면 첫 번째 노드의 선행 노드가 연결 목록의 꼬리 노드를 가리키고 꼬리 노드의 후속 노드가 첫 번째 노드를 가리키면 "이진 트리"가 형성될 수 있습니다. (그림 2의 점선과 같이) 원형 연결 리스트가 형성되면, 포인터 필드를 더 많이 디자인하면 다양하고 복잡한 트리 형태의 데이터 구조가 형성될 수 있습니다.
순환 연결 리스트의 특징은 꼬리 노드의 후속 노드가 첫 번째 노드를 가리킨다는 것입니다. 이중 원형 연결 목록의 개략도는 이전에 제공되었습니다. 그 특징은 모든 노드에서 시작하여 어느 방향으로든 연결 목록의 모든 데이터를 찾을 수 있다는 것입니다. 선행 포인터가 제거되면 단일 순환 연결 리스트가 됩니다.
Linux 커널에서는 다양한 기능 모듈의 장치 목록 및 데이터 구성을 포함하여 데이터를 구성하기 위해 수많은 연결 목록 구조가 사용됩니다. 이러한 연결 목록의 대부분은 [include/linux/list.h]에 구현된 매우 훌륭한 연결 목록 데이터 구조를 사용합니다. 이 기사의 후속 섹션에서는 예제를 통해 이 데이터 구조의 구성과 사용을 자세히 소개합니다.
여기서는 설명의 기초로 2.6 커널을 사용하고 있지만, 사실 2.4 커널의 연결리스트 구조는 2.6 커널과 별반 다르지 않습니다. 차이점은 2.6에서는 두 개의 연결 목록 데이터 구조, 즉 연결 목록(rcu)의 읽기/복사 업데이트와 HASH 연결 목록(hlist)을 확장한다는 것입니다. 두 확장 모두 가장 기본적인 리스트 구조를 기반으로 하기 때문에 본 글에서는 기본적인 연결 리스트 구조를 주로 소개하고, 이어서 rcu와 hlist에 대해 간략하게 소개한다.
연결된 목록 데이터 구조의 정의는 매우 간단합니다([include/linux/list.h]에서 발췌, 달리 명시하지 않는 한 다음 코드는 모두 이 파일에서 가져옴). 으아악
list_head 구조에는 list_head 구조를 가리키는 두 개의 포인터 prev와 next가 포함되어 있습니다. 커널의 연결 목록이 이중 연결 목록의 기능을 가지고 있음을 알 수 있습니다. 실제로는 이중 원형 연결 목록으로 구성됩니다.첫 번째 섹션에서 소개한 이중 연결 목록 구조 모델과 달리 여기의 list_head에는 데이터 필드가 없습니다. Linux 커널 연결 목록에서는 연결 목록 구조에 데이터를 포함하는 대신 연결 목록 노드가 데이터 구조에 포함됩니다.
데이터 구조 교과서에서 연결 목록의 고전적인 정의는 일반적으로 다음과 같습니다(단일 연결 목록을 예로 들어):
으아악
ElemType으로 인해 각 데이터 항목 유형은 자체 연결 목록 구조를 정의해야 합니다. 숙련된 C++ 프로그래머는 표준 템플릿 라이브러리가 템플릿을 사용하여 데이터 항목 유형에 독립적인 연결된 목록 작업 인터페이스를 추상화하는 C++ 템플릿을 사용한다는 것을 알아야 합니다.
在Linux内核链表中,需要用链表组织起来的数据通常会包含一个struct list_head成员,例如在[include/linux/netfilter.h]中定义了一个nf_sockopt_ops结构来描述Netfilter为某一协议族准备的getsockopt/setsockopt接口,其中就有一个(struct list_head list)成员,各个协议族的nf_sockopt_ops结构都通过这个list成员组织在一个链表中,表头是定义在[net/core/netfilter.c]中的nf_sockopts(struct list_head)。从下图中我们可以看到,这种通用的链表结构避免了为每个数据项类型定义自己的链表的麻烦。Linux的简捷实用、不求完美和标准的风格,在这里体现得相当充分。

实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏:
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) struct list_head name = LIST_HEAD_INIT(name)
当我们用LIST_HEAD(nf_sockopts)声明一个名为nf_sockopts的链表头时,它的next、prev指针都初始化为指向自己,这样,我们就有了一个空链表,因为Linux用头指针的next是否指向自己来判断链表是否为空:
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
除了用LIST_HEAD()宏在声明的时候初始化一个链表以外,Linux还提供了一个INIT_LIST_HEAD宏用于运行时初始化链表:
#define INIT_LIST_HEAD(ptr) do { /
(ptr)->next = (ptr); (ptr)->prev = (ptr); /
} while (0)
我们用INIT_LIST_HEAD(&nf_sockopts)来使用它。
a) 插入
对链表的插入操作有两种:在表头插入和在表尾插入。Linux为此提供了两个接口:
static inline void list_add(struct list_head *new, struct list_head *head); static inline void list_add_tail(struct list_head *new, struct list_head *head);
因为Linux链表是循环表,且表头的next、prev分别指向链表中的第一个和最末一个节点,所以,list_add和list_add_tail的区别并不大,实际上,Linux分别用
__list_add(new, head, head->next);
和
__list_add(new, head->prev, head);
来实现两个接口,可见,在表头插入是插入在head之后,而在表尾插入是插入在head->prev之后。
假设有一个新nf_sockopt_ops结构变量new_sockopt需要添加到nf_sockopts链表头,我们应当这样操作:
list_add(&new_sockopt.list, &nf_sockopts);
从这里我们看出,nf_sockopts链表中记录的并不是new_sockopt的地址,而是其中的list元素的地址。如何通过链表访问到new_sockopt呢?下面会有详细介绍。
b) 删除
static inline void list_del(struct list_head *entry);
当我们需要删除nf_sockopts链表中添加的new_sockopt项时,我们这么操作:
list_del(&new_sockopt.list);
被剔除下来的new_sockopt.list,prev、next指针分别被设为LIST_POSITION2和LIST_POSITION1两个特殊值,这样设置是为了保证不在链表中的节点项不可访问–对LIST_POSITION1和LIST_POSITION2的访问都将引起页故障。与之相对应,list_del_init()函数将节点从链表中解下来之后,调用LIST_INIT_HEAD()将节点置为空链状态。
c) 搬移
Linux提供了将原本属于一个链表的节点移动到另一个链表的操作,并根据插入到新链表的位置分为两类:
static inline void list_move(struct list_head *list, struct list_head *head); static inline void list_move_tail(struct list_head *list, struct list_head *head);
例如list_move(&new_sockopt.list,&nf_sockopts)会把new_sockopt从它所在的链表上删除,并将其再链入nf_sockopts的表头。
d) 合并
除了针对节点的插入、删除操作,Linux链表还提供了整个链表的插入功能:
static inline void list_splice(struct list_head *list, struct list_head *head);
假设当前有两个链表,表头分别是list1和list2(都是struct list_head变量),当调用list_splice(&list1,&list2)时,只要list1非空,list1链表的内容将被挂接在list2链表上,位于list2和list2.next(原list2表的第一个节点)之间。新list2链表将以原list1表的第一个节点为首节点,而尾节点不变。如图(虚箭头为next指针):
图4 链表合并list_splice(&list1,&list2)

当list1被挂接到list2之后,作为原表头指针的list1的next、prev仍然指向原来的节点,为了避免引起混乱,Linux提供了一个list_splice_init()函数:
static inline void list_splice_init(struct list_head *list, struct list_head *head);
该函数在将list合并到head链表的基础上,调用INIT_LIST_HEAD(list)将list设置为空链。
遍历是链表最经常的操作之一,为了方便核心应用遍历链表,Linux链表将遍历操作抽象成几个宏。在介绍遍历宏之前,我们先看看如何从链表中访问到我们真正需要的数据项。
a) 由链表节点到数据项变量
我们知道,Linux链表中仅保存了数据项结构中list_head成员变量的地址,那么我们如何通过这个list_head成员访问到作为它的所有者的节点数据呢?Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名,例如,我们要访问nf_sockopts链表中首个nf_sockopt_ops变量,则如此调用:
list_entry(nf_sockopts->next, struct nf_sockopt_ops, list);
这里”list”正是nf_sockopt_ops结构中定义的用于链表操作的节点成员变量名。
list_entry的使用相当简单,相比之下,它的实现则有一些难懂:
#define list_entry(ptr, type, member) container_of(ptr, type, member)
container_of宏定义在[include/linux/kernel.h]中:
#define container_of(ptr, type, member) ({ /
const typeof( ((type *)0)->member ) *__mptr = (ptr); /
(type *)( (char *)__mptr - offsetof(type,member) );})
offsetof宏定义在[include/linux/stddef.h]中:
#define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER)
size_t最终定义为unsigned int(i386)。
这里使用的是一个利用编译器技术的小技巧,即先求得结构成员在与结构中的偏移量,然后根据成员变量的地址反过来得出属主结构变量的地址。
container_of()和offsetof()并不仅用于链表操作,这里最有趣的地方是((type *)0)->member,它将0地址强制”转换”为type结构的指针,再访问到type结构中的member成员。在container_of宏中,它用来给typeof()提供参数(typeof()是gcc的扩展,和sizeof()类似),以获得member成员的数据类型;在offsetof()中,这个member成员的地址实际上就是type数据结构中member成员相对于结构变量的偏移量。
如果这么说还不好理解的话,不妨看看下面这张图:
图5 offsetof()宏的原理

对于给定一个结构,offsetof(type,member)是一个常量,list_entry()正是利用这个不变的偏移量来求得链表数据项的变量地址。
b) 遍历宏
在[net/core/netfilter.c]的nf_register_sockopt()函数中有这么一段话:
……
struct list_head *i;
……
list_for_each(i, &nf_sockopts) {
struct nf_sockopt_ops *ops = (struct nf_sockopt_ops *)i;
……
}
……
函数首先定义一个(struct list_head *)指针变量i,然后调用list_for_each(i,&nf_sockopts)进行遍历。在[include/linux/list.h]中,list_for_each()宏是这么定义的:
#define list_for_each(pos, head) / for (pos = (head)->next, prefetch(pos->next); pos != (head); / pos = pos->next, prefetch(pos->next))
它实际上是一个for循环,利用传入的pos作为循环变量,从表头head开始,逐项向后(next方向)移动pos,直至又回到head(prefetch()可以不考虑,用于预取以提高遍历速度)。
那么在nf_register_sockopt()中实际上就是遍历nf_sockopts链表。为什么能直接将获得的list_head成员变量地址当成struct nf_sockopt_ops数据项变量的地址呢?我们注意到在struct nf_sockopt_ops结构中,list是其中的第一项成员,因此,它的地址也就是结构变量的地址。更规范的获得数据变量地址的用法应该是:
struct nf_sockopt_ops *ops = list_entry(i, struct nf_sockopt_ops, list);
大多数情况下,遍历链表的时候都需要获得链表节点数据项,也就是说list_for_each()和list_entry()总是同时使用。对此Linux给出了一个list_for_each_entry()宏:
#define list_for_each_entry(pos, head, member) ……
与list_for_each()不同,这里的pos是数据项结构指针类型,而不是(struct list_head *)。nf_register_sockopt()函数可以利用这个宏而设计得更简单:
……
struct nf_sockopt_ops *ops;
list_for_each_entry(ops,&nf_sockopts,list){
……
}
……
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
如果遍历不是从链表头开始,而是从已知的某个节点pos开始,则可以使用list_for_each_entry_continue(pos,head,member)。有时还会出现这种需求,即经过一系列计算后,如果pos有值,则从pos开始遍历,如果没有,则从链表头开始,为此,Linux专门提供了一个list_prepare_entry(pos,head,member)宏,将它的返回值作为list_for_each_entry_continue()的pos参数,就可以满足这一要求。
在并发执行的环境下,链表操作通常都应该考虑同步安全性问题,为了方便,Linux将这一操作留给应用自己处理。Linux链表自己考虑的安全性主要有两个方面:
a) list_empty()判断
기본 list_empty()는 헤드 포인터의 다음이 자신을 가리키는지 여부에 따라 연결 목록이 비어 있는지 여부만 결정합니다. Linux 연결 목록은 헤드 포인터의 다음과 이전을 동시에 결정하는 list_empty_careful() 매크로를 제공합니다. 둘 다 자신을 가리키는 경우에만 true를 반환합니다. 이는 주로 동일한 연결 리스트를 다른 CPU에서 처리하여 next와 prev가 일치하지 않는 상황에 대처하기 위한 것입니다. 그러나 코드 주석에서는 이 보안 보장 기능이 제한되어 있음을 인정합니다. 다른 CPU의 연결 목록 작업이 list_del_init()만 아니면 보안을 보장할 수 없습니다. 즉 잠금 보호가 여전히 필요합니다.
b) 순회 중에 노드가 삭제됩니다
연결된 목록 순회를 위한 여러 매크로는 모두 pos 포인터를 이동하여 순회 목적을 달성합니다. 그러나 순회 작업에 pos 포인터가 가리키는 노드 삭제가 포함되면 pos 포인터의 이동이 중단됩니다. 왜냐하면 list_del(pos)가 pos의 다음 및 이전 값을 LIST_POSITION2 및 LIST_POSITION1의 특수 값으로 설정하기 때문입니다. .
물론 호출자는 순회 작업을 일관되게 만들기 위해 다음 포인터를 직접 캐시할 수 있지만 프로그래밍 일관성을 위해 Linux 연결 목록은 여전히 기본 순회 작업에 해당하는 두 개의 "_safe" 인터페이스를 제공합니다: list_for_each_safe(pos, n, head ), list_for_each_entry_safe(pos, n, head, member), 호출자는 pos와 동일한 유형의 또 다른 포인터 n을 제공하고 for 루프에 pos의 다음 노드 주소를 임시 저장하여 다음으로 인한 오류를 방지해야 합니다. pos 노드 해제.
그림 6 목록 및 hlist
훌륭함을 추구하는 Linux 연결 목록 디자이너(list.h가 서명되지 않았기 때문에 아마도 Linus Torvalds일 것임)는 이중 머리(다음, 이전) 이중 연결 목록이 HASH에 대해 "너무 낭비적"이라고 믿습니다. 그래서 그는 HASH 테이블에 사용된 hlist 데이터 구조는 단일 포인터 헤더 이중 순환 연결 리스트입니다. 위 그림에서 볼 수 있듯이 hlist 헤더에는 첫 번째 노드에 대한 포인터만 있고 테일 노드에 대한 포인터가 없습니다. 이는 큰 문제일 수 있습니다. HASH 테이블에 저장된 헤더는 공간 소비를 절반으로 줄일 수 있습니다.
헤더와 노드의 데이터 구조가 다르기 때문에 헤더와 첫 번째 노드 사이에 삽입 작업이 발생하면 이전 방법은 작동하지 않습니다. 헤더의 첫 번째 포인터는 새로 삽입된 노드를 가리키도록 수정해야 합니다. , 그러나 통합된 설명과 같은 list_add()처럼 사용할 수는 없습니다. 이러한 이유로 hlist 노드의 prev는 더 이상 이전 노드에 대한 포인터가 아니라 이전 노드(헤더일 수도 있음)의 다음(헤더의 첫 번째)에 대한 포인터입니다(struct list_head **pprev). 테이블 헤드에 삽입하는 작업은 일관된 "*(node->pprev)"를 통해 선행 노드의 다음(또는 첫 번째) 포인터에 액세스하고 수정할 수 있습니다.
Linux 연결 목록 함수 인터페이스에는 "_rcu"로 끝나는 일련의 매크로도 있는데, 이는 위에 소개된 많은 함수에 해당합니다. RCU(Read-Copy Update)는 쓰기 작업을 지연시켜 동기화 성능을 향상시키는 2.5/2.6 커널에 도입된 새로운 기술입니다.
우리는 시스템에서 쓰기 작업보다 데이터 읽기 작업이 훨씬 더 많다는 것을 알고 있으며, SMP 환경에서는 프로세서 수가 증가함에 따라 rwlock 메커니즘의 성능이 급격히 떨어집니다(참고 자료 4 참조). 이러한 응용 배경에 대해 IBM Linux 기술 센터의 Paul E. McKenney는 "읽기 복사 업데이트" 기술을 제안하고 이를 Linux 커널에 적용했습니다. RCU 기술의 핵심은 쓰기 작업이 쓰기와 업데이트의 두 단계로 나누어져 있어 시스템에 쓰기 작업이 있으면 모든 읽기 작업이 완료될 때까지 업데이트 작업이 지연된다는 것입니다. 데이터가 완료되었습니다. Linux 연결 목록의 RCU 기능은 Linux RCU의 일부에 불과합니다. RCU 구현 분석은 이 기사의 범위를 벗어납니다. 관심 있는 독자는 이 기사의 참조 자료와 RCU 연결 목록을 참조할 수 있습니다. 기본 연결리스트의 사용법은 기본적으로 동일합니다.
첨부 파일의 프로그램은 정방향 및 역방향으로 파일을 출력할 수 있다는 점 외에는 실질적인 효과가 없습니다. Linux 연결 목록의 사용을 보여주기 위한 용도로만 사용됩니다.
단순화를 위해 예제에서는 사용자 모드 프로그램 템플릿을 사용합니다. 실행해야 하는 경우 다음 명령을 사용하여 컴파일할 수 있습니다.
gcc -D__KERNEL__ -I/usr/src/linux-2.6.7/include pfile.c -o pfile
因为内核链表限制在内核态使用,但实际上对于数据结构本身而言并非只能在核态运行,因此,在笔者的编译中使用”-D__KERNEL__”开关”欺骗”编译器。
위 내용은 Linux 커널 연결 목록의 상세 분석의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



