

관심 없는 대형 모델 Eagle7B: RWKV 기반으로 추론 비용이 10~100배 절감됩니다
AI 트랙에서는 수천억 개의 모델에 비해 최근 소형 모델이 많은 주목을 받고 있습니다. 매개변수. 예를 들어, 프랑스 AI 스타트업이 출시한 Mistral-7B 모델은 모든 벤치마크에서 Llama 2를 13B 앞섰고, 코드, 수학, 추론에서는 Llama 1을 34B 앞섰습니다.
대형 모델에 비해 소형 모델은 컴퓨팅 전력 요구 사항이 낮고 장치 측에서 실행할 수 있는 능력 등 많은 장점이 있습니다.
최근 오픈 소스 비영리 조직인 RWKV에서 7.52B 매개변수 Eagle 7B라는 새로운 언어 모델이 등장했습니다. 이는 다음과 같은 특징을 갖습니다. -v5 아키텍처 구축, 이 아키텍처의 추론 비용은 낮습니다(RWKV는 선형 변환기이므로 추론 비용이 10~100배 이상 절감됩니다).
 100개 이상의 언어와 1조 1천억 개 이상의 토큰으로 학습 ;
100개 이상의 언어와 1조 1천억 개 이상의 토큰으로 학습 ;
 RWKV-v5 Eagle 7B는 제한 없이 개인용 또는 상업용으로 사용할 수 있다는 점을 언급할 가치가 있습니다.
RWKV-v5 Eagle 7B는 제한 없이 개인용 또는 상업용으로 사용할 수 있다는 점을 언급할 가치가 있습니다.
23개 언어에 대한 테스트 결과
다국어에 대한 다양한 모델의 성능은 다음과 같습니다. 테스트 벤치마크에는 xLAMBDA, xStoryCloze, xWinograd, xCopa가 포함됩니다. ㅋㅋㅋ . 그러나 다국어 벤치마크가 부족해 연구에서는 좀 더 많이 사용되는 23개 언어에 대해서만 능력을 테스트할 수 있고, 나머지 75개 이상의 언어에 대한 능력은 아직 알 수 없다.
영어 성적
다양한 모델들의 영어 성적은 상식추론, 세계지식 등 12가지 벤치마크를 통해 평가됩니다.
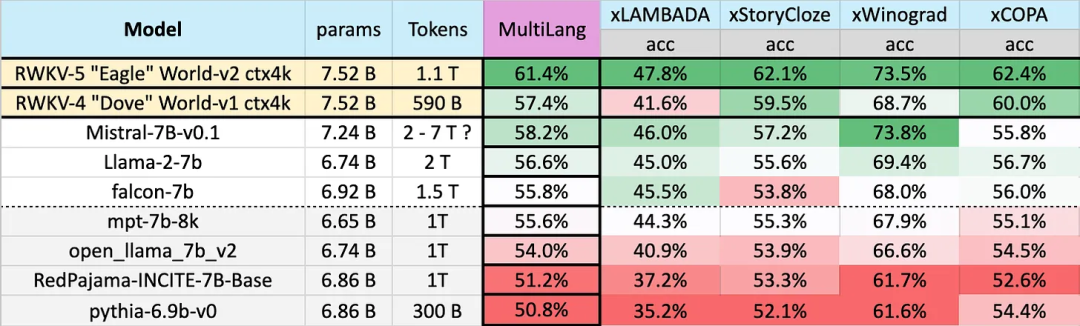 결과에서 우리는 RWKV가 v4에서 v5 아키텍처로 크게 도약한 것을 다시 한 번 확인할 수 있습니다. v4는 이전에 1T 토큰 MPT-7b에 패했지만 v5는 벤치마크 테스트에서 따라잡기 시작했습니다. 어떤 경우에는(일부 벤치마크 테스트 LAMBADA, StoryCloze16, WinoGrande, HeadQA_en, Sciq에서도) Falcon 또는 심지어 llama2를 능가할 수 있습니다.
결과에서 우리는 RWKV가 v4에서 v5 아키텍처로 크게 도약한 것을 다시 한 번 확인할 수 있습니다. v4는 이전에 1T 토큰 MPT-7b에 패했지만 v5는 벤치마크 테스트에서 따라잡기 시작했습니다. 어떤 경우에는(일부 벤치마크 테스트 LAMBADA, StoryCloze16, WinoGrande, HeadQA_en, Sciq에서도) Falcon 또는 심지어 llama2를 능가할 수 있습니다.
이전 Mistral-7B는 7B 규모 모델에서 선두를 유지하기 위해 2~7조 토큰의 훈련 방법을 사용했습니다. 연구에서는 RWKV-v5 Eagle 7B가 llama2 성능을 능가하고 Mistral 수준에 도달할 수 있도록 이러한 격차를 해소하기를 희망합니다.
아래 그림은 3000억 토큰 포인트에 가까운 RWKV-v5 Eagle 7B의 체크포인트가 pythia-6.9b와 유사한 성능을 보여줍니다.
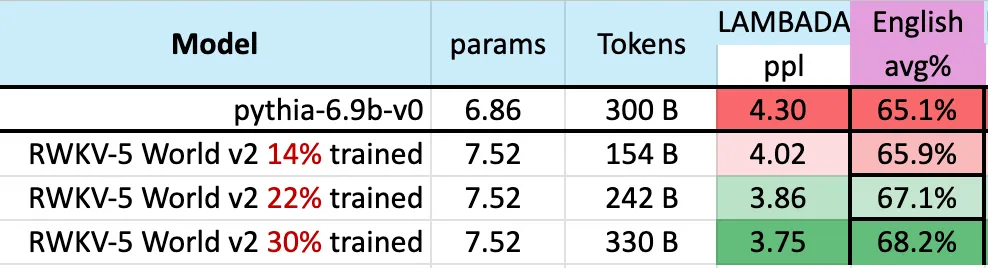
이것은 RWKV-v4 아키텍처에 대한 이전 작업과 일치합니다. 파일 기반) 합의는 RWKV와 같은 선형 변환기가 성능 수준이 변환기와 유사하고 동일한 수의 토큰으로 훈련된다는 것입니다.
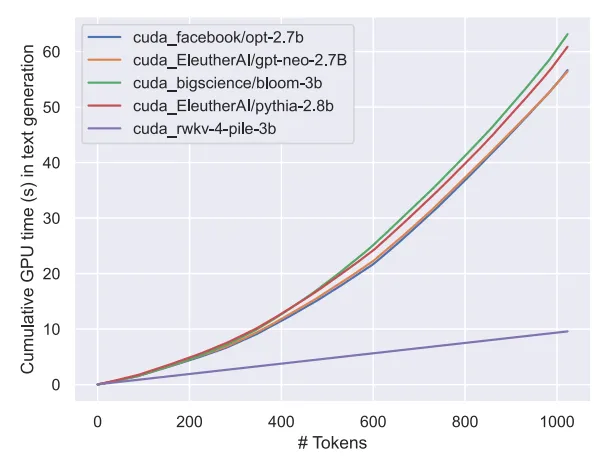
예상대로 이 모델의 등장은 (평가 벤치마크 측면에서) 가장 강력한 선형 변압기의 등장을 의미합니다.
위 내용은 Attention-free 대형 모델 Eagle7B: RWKV 기준으로 추론 비용이 10~100배 감소의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!






























![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



