

'청소년 최초의 멀티모달 대형 모델' Vary-toy이 나왔습니다!
모델 크기가 2B 미만이고 소비자급 그래픽 카드에서 학습이 가능하며 GTX1080ti 8G 구형 그래픽 카드에서도 쉽게 실행할 수 있습니다.
문서 이미지를 마크다운 형식으로 변환하고 싶으십니까? 과거에는 텍스트 인식, 레이아웃 감지 및 정렬, 수식표 처리, 텍스트 정리 등 여러 단계가 필요했습니다.
이제 하나의 명령만 필요합니다:
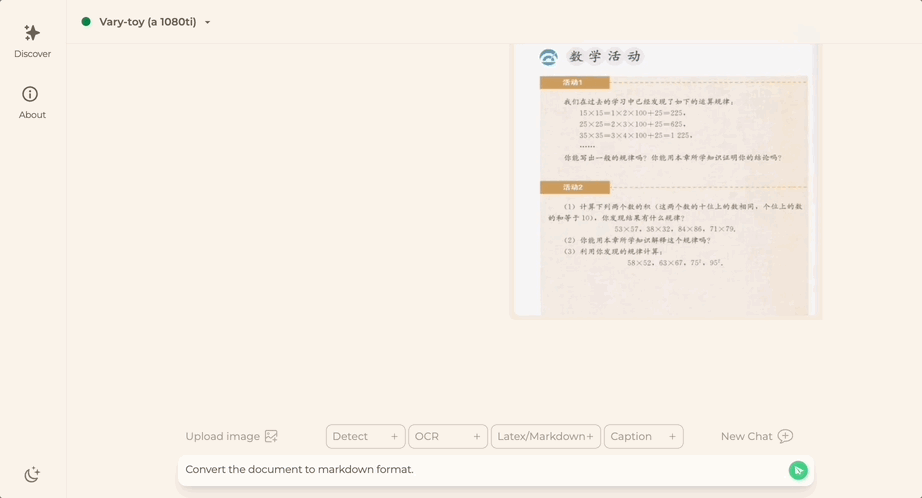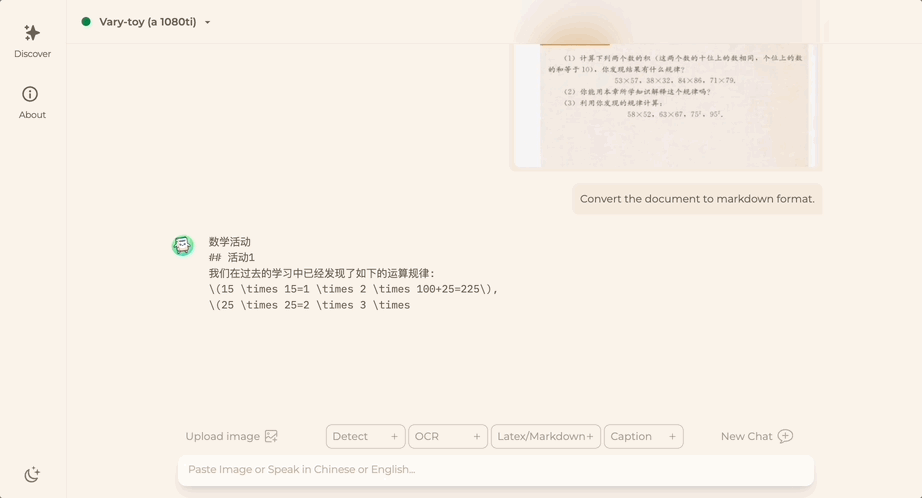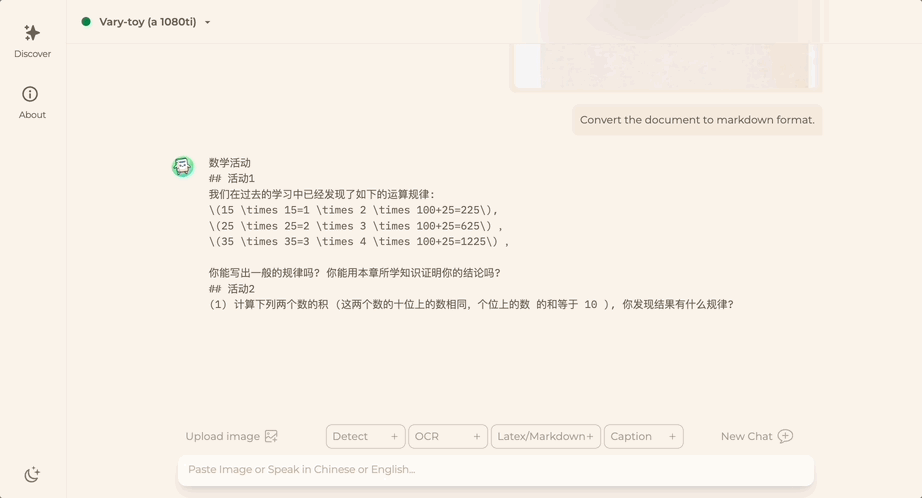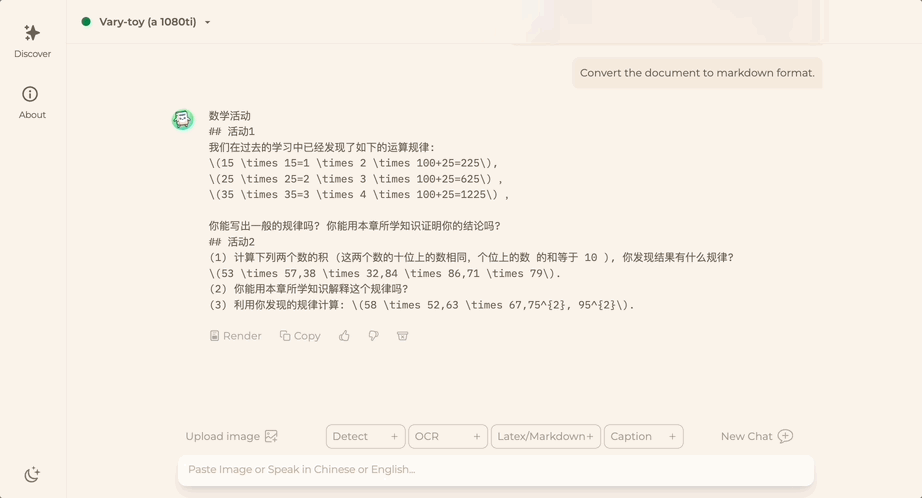
중국어 또는 영어에 관계없이 사진의 큰 텍스트는 몇 분 안에 추출할 수 있습니다.

사진의 개체 감지는 여전히 특정 좌표:

이 연구는 Megvii, 국립과학기술대학교, 화중대학교 연구진이 공동으로 제안한 것입니다.
보고에 따르면 Vary-toy는 규모는 작지만 LVLM(Large Scale Visual Language Model): 문서 OCR 인식(Document OCR), 시각적 위치 지정(시각적 위치 지정)의 현재 주류 연구의 거의 모든 기능을 다루고 있습니다. 접지) , 이미지 캡션, 시각적 질문 답변 (VQA) .

이제 Vary-toy 코드와 모델은 오픈 소스이며 시험 플레이가 가능한 온라인 데모가 있습니다.

네티즌들은 관심을 표하는 가운데 구·GTX1080에 집중하고 있으며 분위기는

사실 Vary 팀은 빠르면 12월에 Vary를 출시했습니다. 지난해 첫 번째 연구 결과는 'Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models'입니다.
연구원들은 치밀한 인식 능력에서 CLIP 시각적 단어 목록의 단점을 지적하고, 간단하고 효과적인 단어 목록 확장 방식을 사용하여 새로운 OCR 패러다임을 제공했습니다.
Vary는 출시 이후 폭넓은 관심을 받았습니다. 현재 Github에 별이 1200개 이상 있지만, 제한된 리소스로 인해 많은 사람들이 실행하지 못하고 있습니다.
오픈소스가 잘 구축되어 있고 성능도 우수한 '소형' VLM이 상대적으로 적은 점을 고려하여, '젊은층 최초의 멀티 모드 대형 모델'로 알려진 Vary-toy를 새롭게 출시했습니다.
Vary에 비해 Vary-toy는 더 작을 뿐만 아니라 더 강력한 시각적 어휘를 훈련합니다. 새로운 어휘는 더 이상 모델을 문서 수준 OCR로 제한하지 않고 보다 보편적이고 포괄적인 시각적 어휘를 제공합니다. 문서 수준 OCR뿐만 아니라 일반적인 시각적 대상 감지도 수행할 수 있습니다.
그럼 이건 어떻게 하는 걸까요? Vary-toy의 모델 구조와 학습 과정은 아래 그림과 같습니다. 일반적으로 학습은 두 단계로 나누어집니다.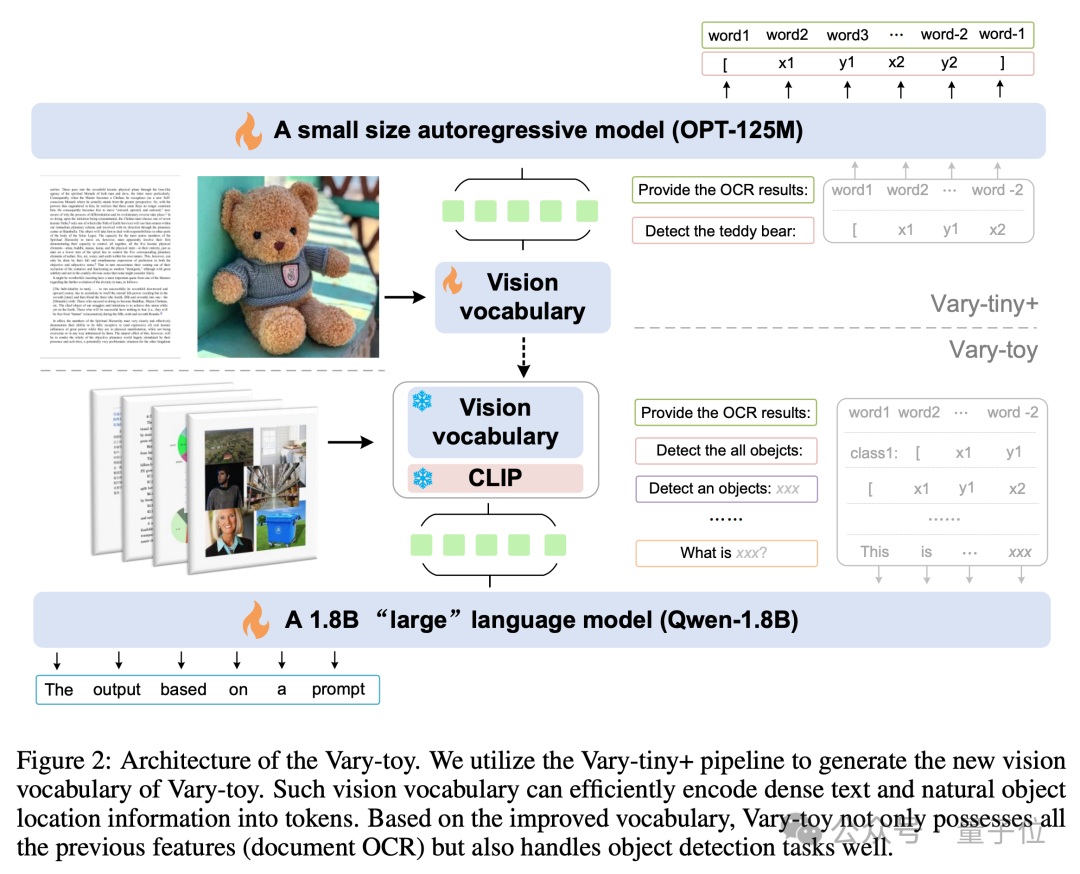
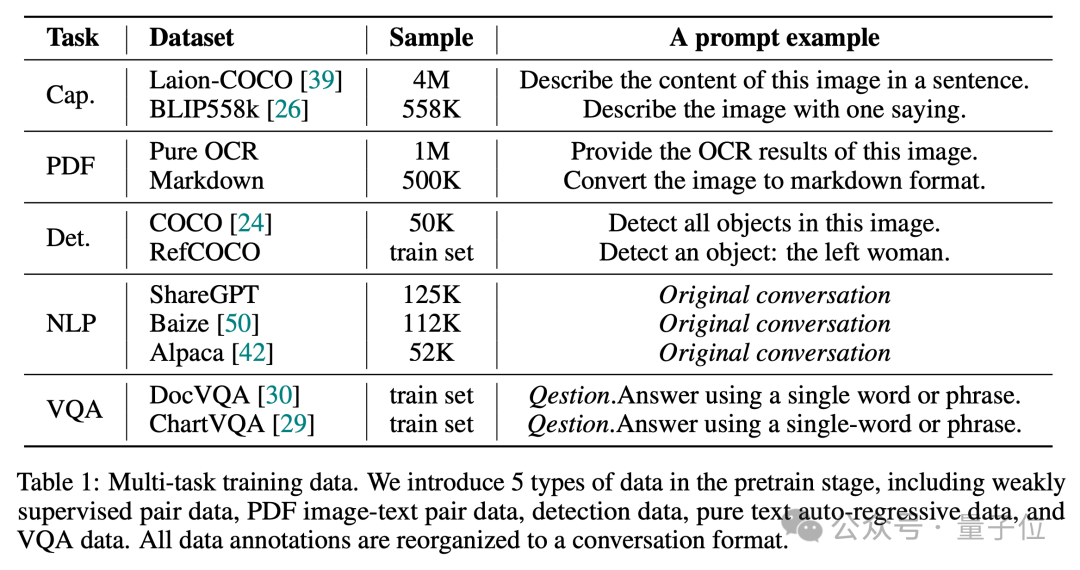
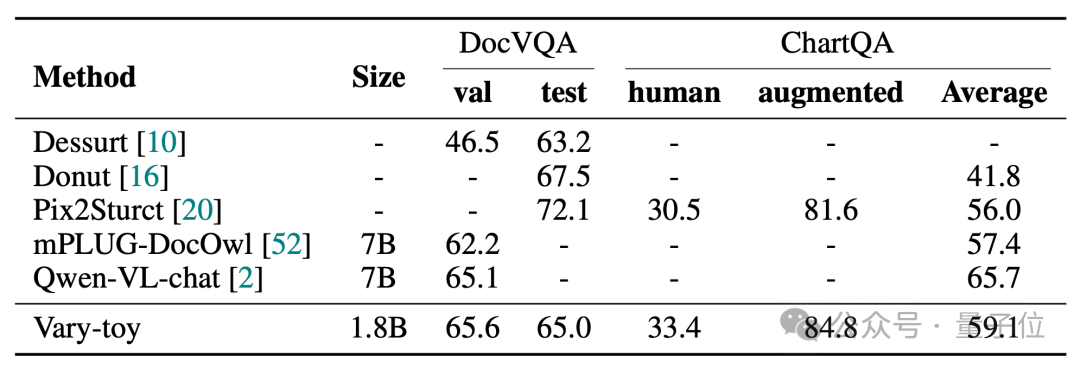
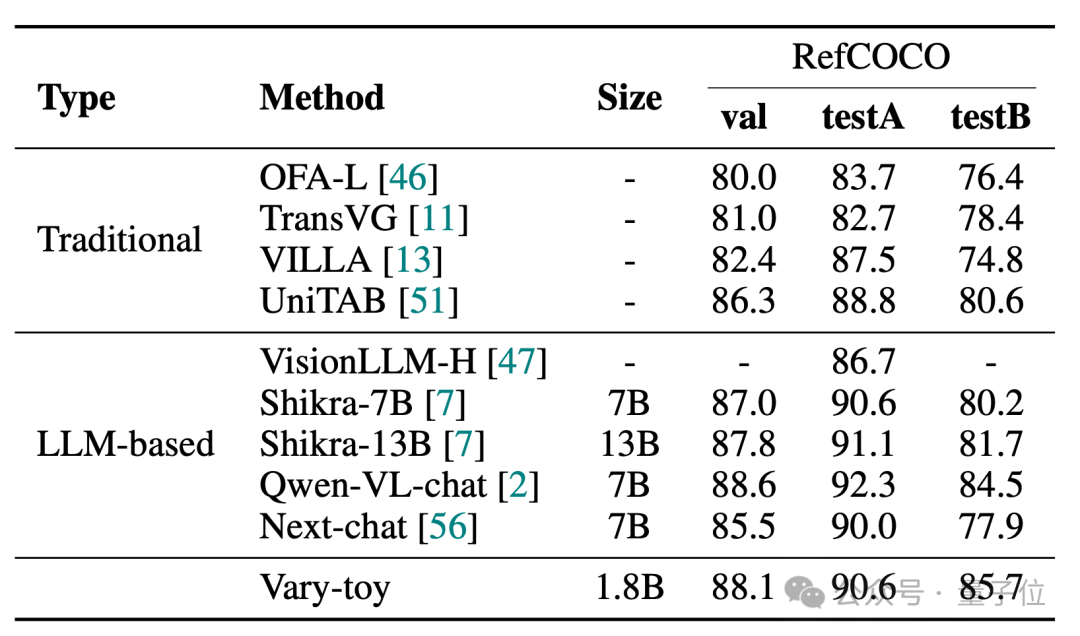
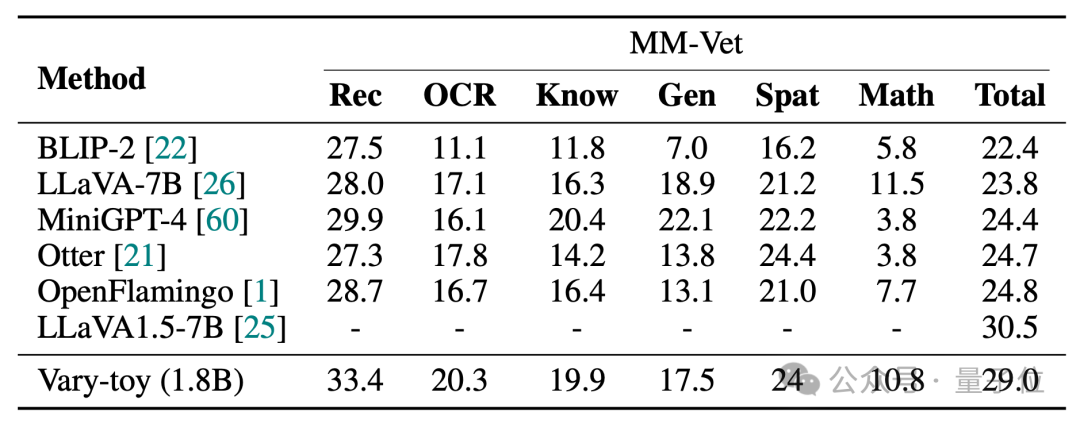
Vary-toy는 DocVQA에서 65.6% ANLS, ChartQA에서 59.1% 정확도, RefCOCO에서 88.1% 정확도를 달성할 수 있습니다.
MMVet은 벤치마크 점수 또는 시각화 효과 여부에 관계없이 29% 정확도를 달성할 수 있습니다. , 2B 미만인 Vary-toy는 일부 인기 있는 7B 모델의 성능과도 경쟁할 수 있습니다.
프로젝트 링크:
[1]https://arxiv.org/abs/2401.12503
[3]https://varytoy.github.io/
위 내용은 다중 모드 대형 모델은 오픈 소스를 통해 온라인에서 젊은이들이 선호합니다. 1080Ti를 쉽게 실행할 수 있습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



