

2023년에는 AI 대형 모델 분야의 강자였던 트랜스포머의 위상이 도전받기 시작할 것입니다. "Mamba"라는 새로운 아키텍처가 등장했습니다. 이는 언어 모델링에서 Transformer와 비교할 수 있고 심지어 이를 능가할 수도 있는 선택적 상태 공간 모델입니다. 동시에 Mamba는 컨텍스트 길이가 증가함에 따라 선형 확장을 달성할 수 있어 백만 단어 길이의 시퀀스를 처리하고 실제 데이터를 처리할 때 추론 처리량을 5배 향상시킬 수 있습니다. 이러한 획기적인 성능 향상은 눈길을 끌며 AI 분야 발전에 새로운 가능성을 제시한다.
Mamba는 출시된 지 한 달이 넘도록 점차 영향력을 발휘하기 시작했으며 MoE-Mamba, Vision Mamba, VMamba, U-Mamba, MambaByte 등 많은 프로젝트를 탄생시켰습니다. Mamba는 Transformer의 단점을 지속적으로 극복하는 데 큰 잠재력을 보여주었습니다. 이러한 발전은 Mamba의 지속적인 발전과 발전을 보여주며 인공 지능 분야에 새로운 가능성을 가져옵니다.
그러나 이 떠오르는 "스타"는 2024 ICLR 회의에서 좌절을 겪었습니다. 최근 공개 결과에 따르면 Mamba의 논문은 여전히 보류 상태에 있습니다. 보류 결정 열에서만 해당 이름을 볼 수 있으며 지연 또는 거부 여부를 확인할 수 없습니다.

전반적으로 Mamba는 4명의 리뷰어로부터 각각 8/8/6/3의 평점을 받았습니다. 어떤 사람들은 그런 평가를 받고도 계속 거절당하는 것이 정말 당혹스럽다고 말했습니다.

이유를 이해하려면 낮은 점수를 준 리뷰어의 말을 살펴봐야 합니다.
논문 리뷰 페이지: https://openreview.net/forum?id=AL1fq05o7H
리뷰 피드백에서 "3: 거부, 충분하지 않음" 점수를 준 리뷰어는 Mamba에 대한 여러 가지 의견을 설명했습니다.
모델 디자인에 대한 생각:
실험에 대한 생각:
또한 다른 리뷰어는 Mamba의 단점도 지적했습니다. 이 모델은 여전히 Transformers처럼 훈련 중에 보조 메모리를 요구합니다.
모든 심사자의 의견을 종합한 후, 저자팀도 논문의 내용을 수정 및 개선하고 새로운 실험 결과와 분석을 추가했습니다.
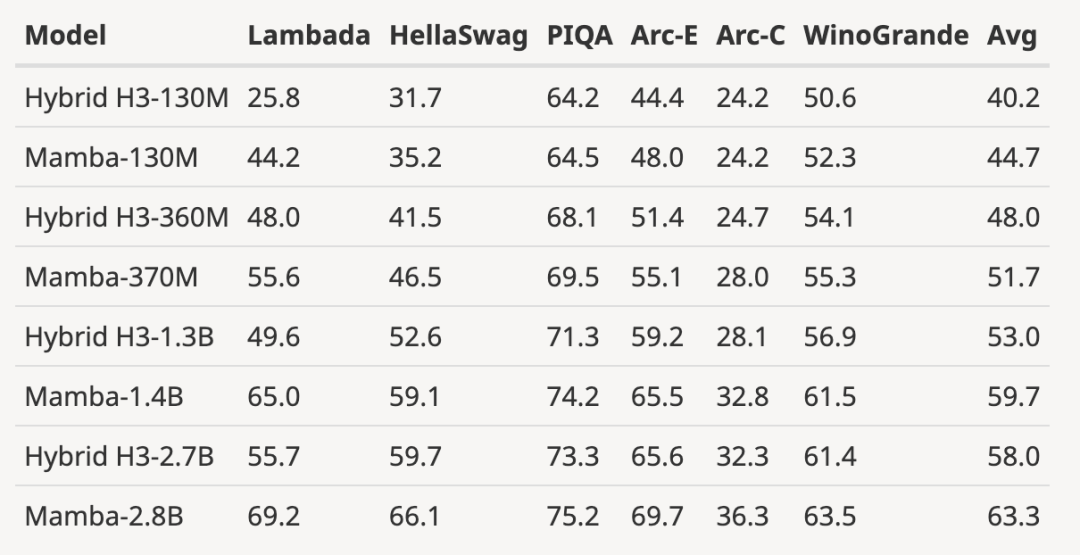
저자는 매개변수 크기가 125M~2.7B인 사전 학습된 H3 모델을 다운로드하고 일련의 평가를 수행했습니다. Mamba는 모든 언어 평가에서 훨씬 더 좋습니다. 이러한 H3 모델은 2차 주의를 사용하는 하이브리드 모델인 반면, 선형 시간 Mamba 레이어만 사용하는 저자의 순수 모델은 모든 지표에서 훨씬 더 좋습니다.
사전 훈련된 H3 모델과의 평가 비교는 다음과 같습니다.
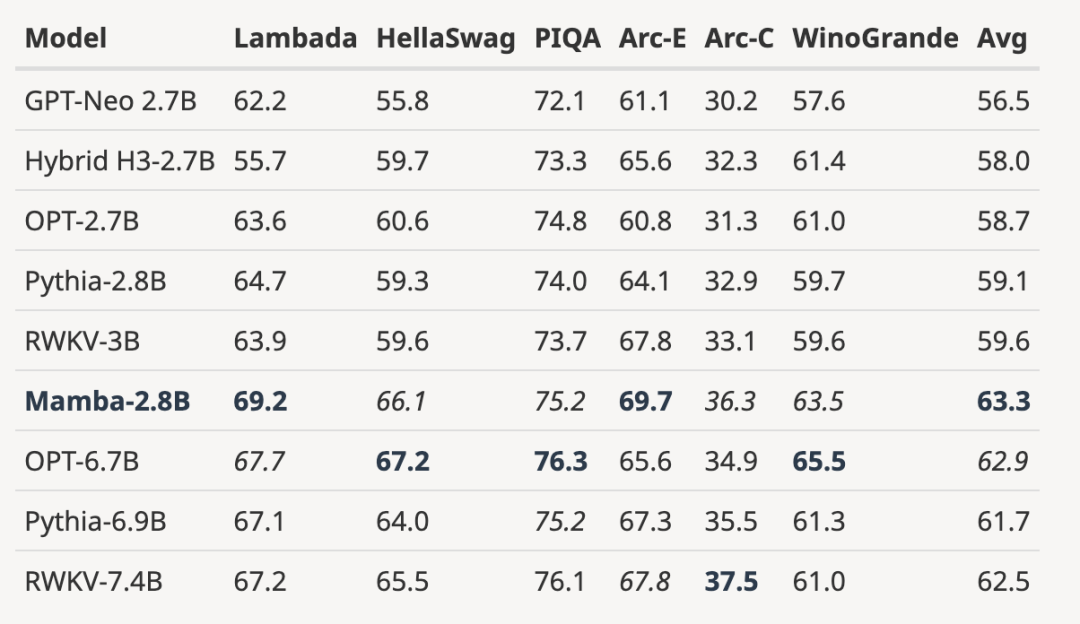
, 동일한 수의 토큰(300B)으로 훈련된 3B 오픈 소스 모델과 비교하면 모든 평가 결과에서 Mamba가 우수합니다. 이는 7B 규모 모델과도 비교할 수 있습니다. Mamba(2.8B)를 OPT, Pythia 및 RWKV(7B)와 비교할 때 Mamba는 모든 벤치마크 점수에서 최고의 평균 점수와 최고/두 번째 최고를 달성합니다.
저자는 사전 훈련된 3B 파라메트릭 언어 모델의 길이 외삽을 평가하는 그림을 첨부했습니다:
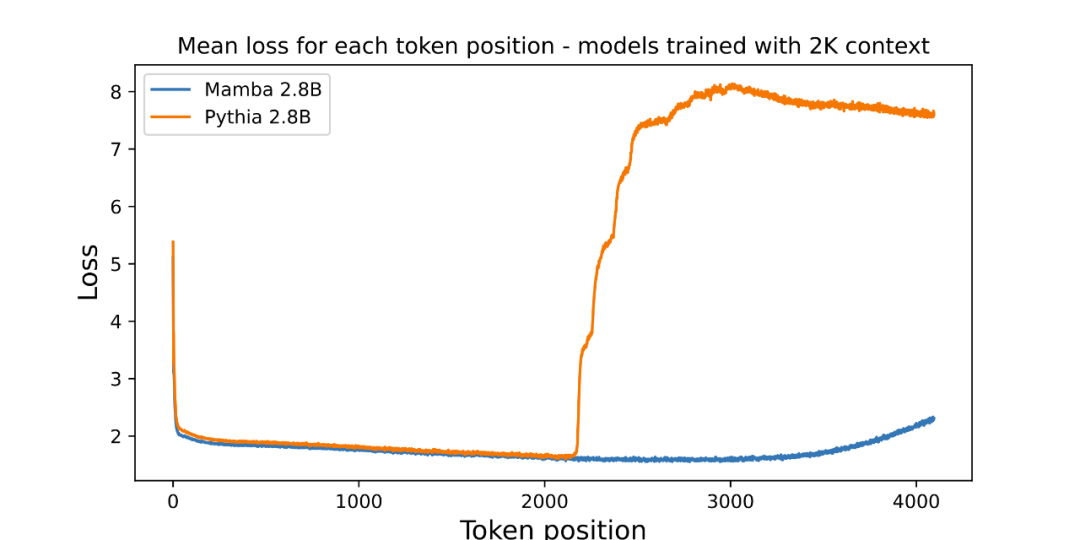
그래프는 포지션당 평균 손실(로그 가독성)을 나타냅니다. 첫 번째 토큰의 혼란은 컨텍스트가 없기 때문에 높지만 Mamba와 기본 Transformer(Pythia)의 혼란은 훈련 컨텍스트 길이(2048) 이전에 증가합니다. 흥미롭게도 Mamba의 해결 가능성은 훈련 컨텍스트를 넘어 최대 약 3000까지 크게 향상됩니다.
저자는 이 글에서 길이 외삽이 모델의 직접적인 동기가 아니라는 점을 강조하지만 이를 추가 기능으로 취급합니다.
저자는 여러 논문의 결과를 분석하여 Mamba가 다른 20개 이상의 최신 하위 2차 시퀀스 모델보다 WikiText-103에서 훨씬 더 나은 성능을 발휘한다는 것을 보여주었습니다.
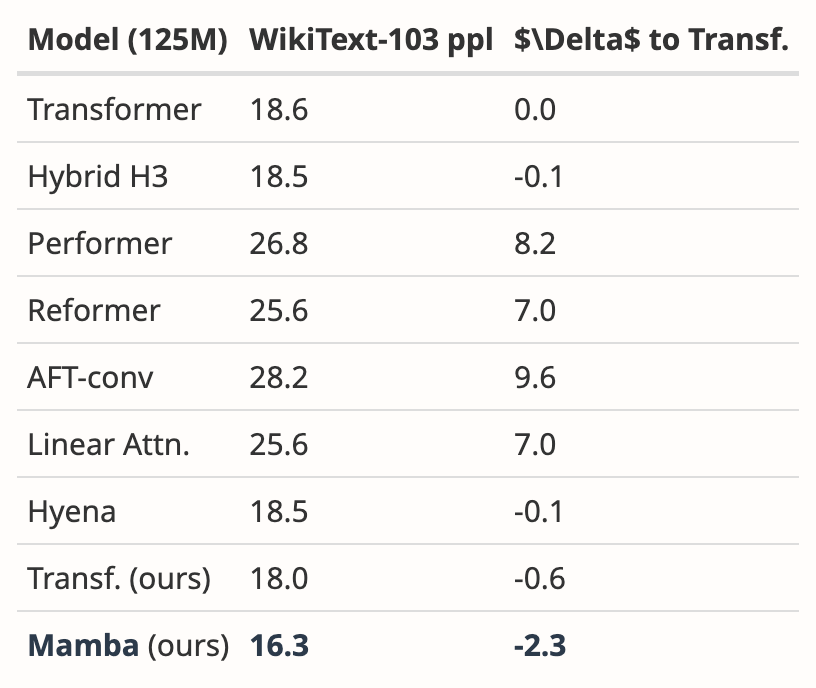
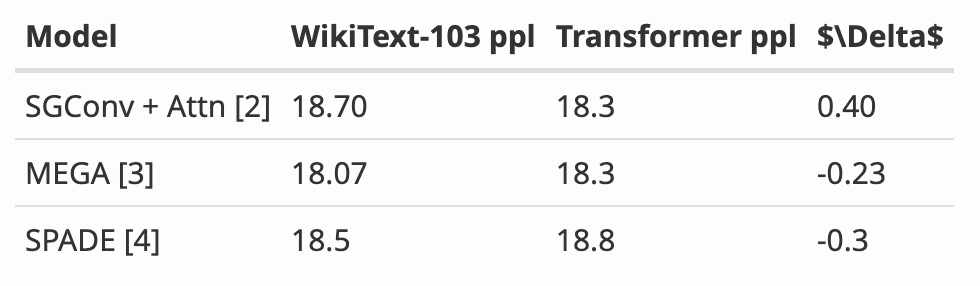
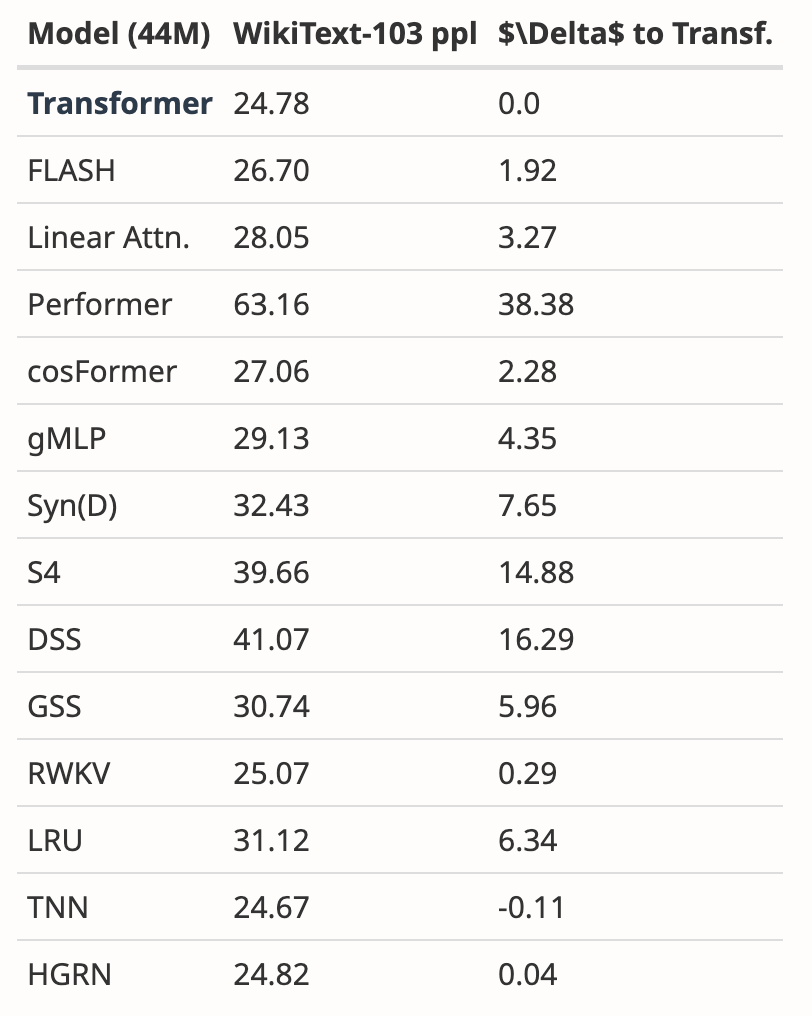
그럼에도 불구하고 두 달이 지났지만 본 논문은 아직까지 '승인'이나 '거부'라는 명확한 결과 없이 '결정 보류' 상태에 있습니다.
주요 AI 상위 학회에서는 "제출 건수의 폭발적인 문제"가 골치 아픈 문제이므로 에너지가 부족한 심사자는 필연적으로 실수를 하게 됩니다. 이로 인해 YOLO, Transformer XL, Dropout, SVM(지원 벡터 머신), 지식 증류, SIFT 및 Google 검색 엔진의 웹 페이지 순위 알고리즘 PageRank를 포함하여 역사상 많은 유명한 논문이 거부되었습니다(참조: "유명한 YOLO 및 PageRank의 영향력 있는 연구는 최고 CS 컨퍼런스에서 거부되었습니다.")
딥러닝 3대 거인 중 하나인 얀 르쿤(Yann LeCun)도 종종 거절당하는 메이저 제지 메이커이기도 합니다. 방금 그는 1887회 인용된 자신의 논문 "Deep Convolutional Networks on Graph-Structured Data"가 최고 학회에서 거부되었다고 트위터에 올렸습니다.
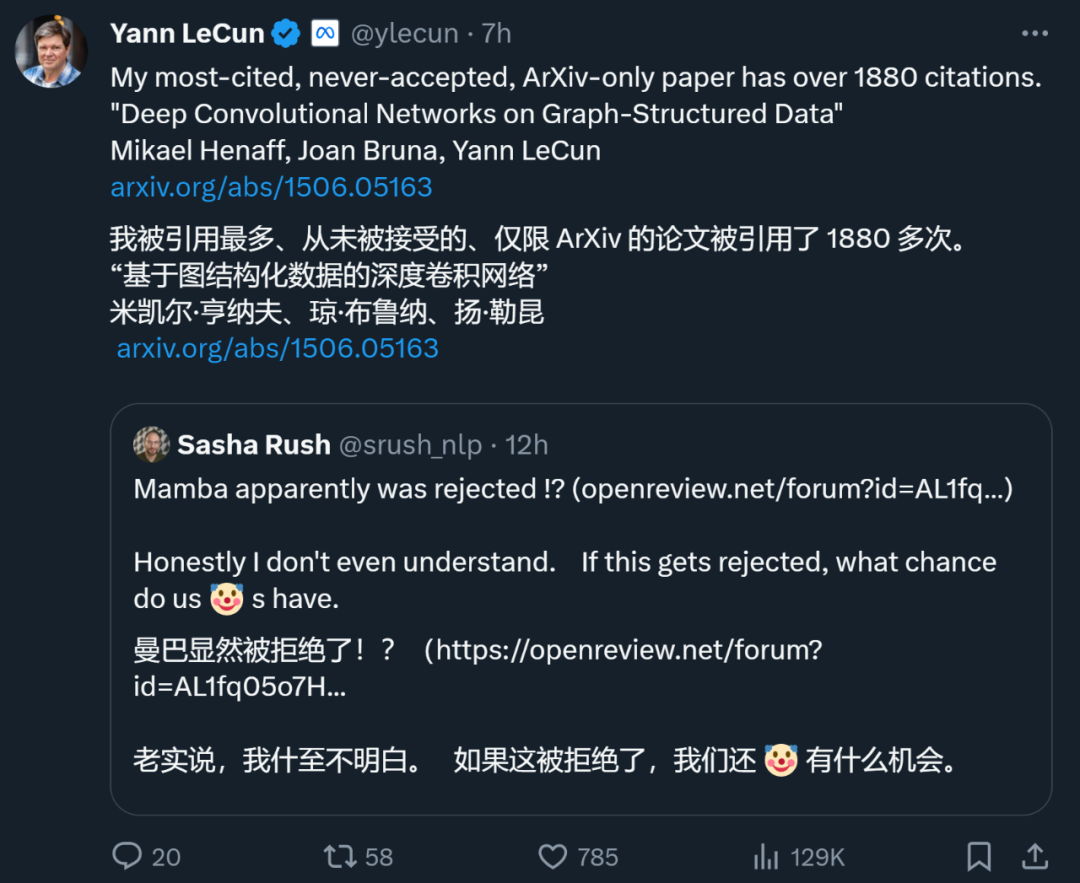
ICML 2022 기간 동안 그는 "3개의 논문을 제출했지만 3개가 거부되었습니다."

따라서, 논문이 최고 학회에서 거부되었다고 해서 그것이 가치가 없다는 의미는 아닙니다. 위에서 언급한 거절된 논문들 중 많은 사람들이 다른 학회로 옮겨가는 것을 선택했고 결국 승인되었습니다. 따라서 네티즌들은 Mamba가 Chen Danqi와 다른 젊은 학자들이 설립한 COLM으로 전환할 것을 제안했습니다. COLM은 언어 모델링 연구에 전념하는 학술 장소로, 언어 모델 기술 개발에 대한 이해, 개선 및 논평에 중점을 두고 있으며 Mamba와 같은 논문에 더 나은 선택이 될 수 있습니다.
그러나 Mamba가 궁극적으로 ICLR에 승인되었는지 여부에 관계없이 영향력 있는 작품이 되었으며 커뮤니티에도 Transformer의 족쇄를 돌파할 수 있는 희망을 주었고 전통을 뛰어넘는 탐구에 희망을 불어넣었습니다. 새로운 에너지 모델.
위 내용은 ICLR은 왜 Mamba의 논문을 받아들이지 않았나요? AI 커뮤니티가 큰 논의를 촉발시켰습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



