

SSM(State Space Model)은 많은 주목을 받고 있는 기술로 Transformer의 대안으로 여겨지고 있습니다. Transformer와 비교하여 SSM은 긴 컨텍스트 작업을 처리할 때 선형 시간 추론을 달성할 수 있으며 병렬 교육과 뛰어난 성능을 제공합니다. 특히 선택적 SSM과 하드웨어 인식 설계를 기반으로 하는 Mamba는 뛰어난 성능을 보여주었고 주목 기반 Transformer 아키텍처에 대한 강력한 대안 중 하나로 자리 잡았습니다.
최근 연구원들은 SSM과 Mamba를 다른 방법과 결합하여 더욱 강력한 아키텍처를 만드는 방법도 모색하고 있습니다. 예를 들어, Machine Heart는 "Mamba가 Transformer를 대체할 수 있지만 조합하여 사용할 수도 있습니다"라고 보고한 적이 있습니다.
최근 폴란드 연구팀은 SSM이 하이브리드 전문가 시스템(MoE/Mixture of Experts)과 결합되면 SSM의 대규모 확장을 기대할 수 있다는 사실을 발견했습니다. MoE는 Transformer를 확장하는 데 일반적으로 사용되는 기술입니다. 예를 들어 최신 Mixtral 모델은 Heart of the Machine 기사를 참조하세요.
이 폴란드 연구팀의 연구 결과는 Mamba와 하이브리드 전문가층을 결합한 모델인 MoE-Mamba입니다.

문서 주소: https://arxiv.org/pdf/2401.04081.pdf
MoE-Mamba는 SSM과 MoE의 효율성을 동시에 향상시킬 수 있습니다. 또한 팀은 전문가 수가 다양할 때 MoE-Mamba가 예상대로 행동한다는 사실도 발견했습니다.
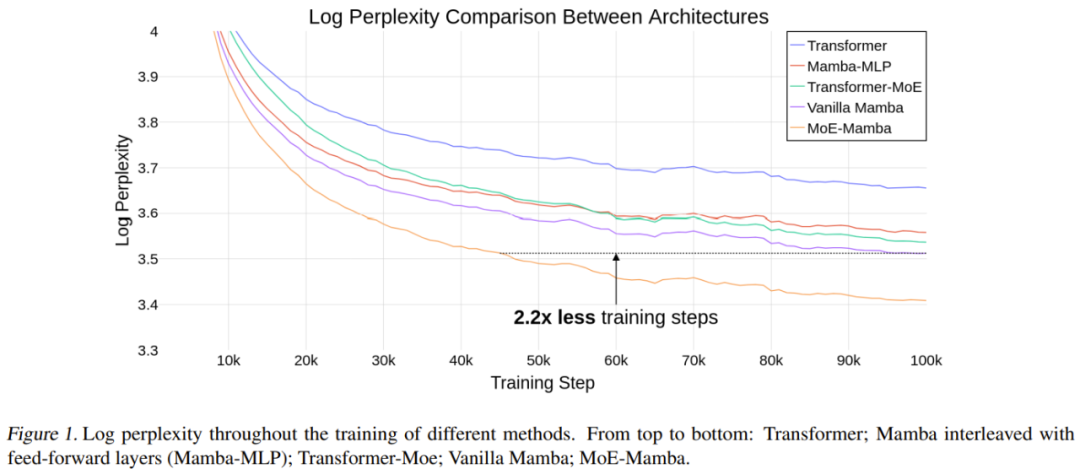
팀에서 실험적 시연을 실시한 결과 Mamba에 비해 MoE-Mamba는 동일한 성능 요구 사항으로 2.2배 더 적은 훈련 단계가 필요한 것으로 나타났으며 이는 Transformer 및 Transformer-MoE에 비해 새로운 방법의 성능이 잠재적인 이점을 보여줍니다. 이러한 예비 결과는 또한 유망한 연구 방향을 제시합니다. SSM은 수백억 개의 매개변수로 확장될 수 있습니다.
상태 공간 모델
상태 공간 모델(SSM)은 시퀀스 모델링에 사용되는 아키텍처 유형입니다. 이러한 모델에 대한 아이디어는 사이버네틱스 분야에서 유래되었으며 RNN과 CNN의 조합으로 볼 수 있습니다. 상당한 장점이 있지만 언어 모델링 작업에서 지배적인 아키텍처가 되지 못하게 하는 몇 가지 문제도 있습니다. 그러나 최근 연구 혁신을 통해 Deep SSM은 계산 효율성과 강력한 성능을 유지하면서 수십억 개의 매개변수로 확장할 수 있게 되었습니다.
Mamba
Mamba는 SSM을 기반으로 구축된 모델로, 선형 시간 추론 속도(컨텍스트 길이에 대한)를 달성할 수 있으며 하드웨어 인식 설계를 통해 효율적인 훈련 프로세스도 달성합니다. Mamba는 루프 순차성의 영향을 완화하는 작업 효율적인 병렬 스캔 접근 방식을 사용하는 동시에 융합된 GPU 작업을 통해 확장 상태를 구현할 필요가 없습니다. 역전파에 필요한 중간 상태는 저장되지 않고 역방향 전달 중에 다시 계산되므로 메모리 요구 사항이 줄어듭니다. Attention 메커니즘에 비해 Mamba의 장점은 추론 단계에서 특히 중요합니다. 왜냐하면 계산 복잡성을 줄일 뿐만 아니라 메모리 사용량이 컨텍스트 길이에 의존하지 않기 때문입니다.
Mamba는 시퀀스 모델의 효율성과 유효성 사이의 근본적인 균형을 해결할 수 있으며 이는 상태 압축의 중요성을 강조합니다. 효율적인 모델은 작은 상태를 요구해야 하며, 효과적인 모델이 요구하는 상태는 컨텍스트의 모든 핵심 정보를 포함해야 합니다. 시간적 및 입력 불변성을 요구하는 다른 SSM과 달리 Mamba는 정보가 시퀀스 차원을 따라 전파되는 방식을 제어하는 선택 메커니즘을 도입합니다. 이 디자인 선택은 선택적 복제 및 유도와 같은 합성 작업에 대한 직관적인 이해에서 영감을 얻어 모델이 관련 없는 정보를 필터링하면서 중요한 정보를 식별하고 유지할 수 있도록 합니다.
연구에 따르면 Mamba는 더 긴 컨텍스트(최대 100만 개 토큰)를 효율적으로 활용할 수 있는 능력이 있으며 컨텍스트 길이가 늘어남에 따라 사전 훈련 당혹감도 개선됩니다. Mamba 모델은 Mamba 블록을 쌓아서 구성한 모델로 NLP, 유전체학, 오디오 등 다양한 분야에서 매우 좋은 결과를 얻었습니다. 성능은 기존 Transformer 모델과 비슷하거나 능가합니다. 따라서 Mamba는 일반 시퀀스 모델링 백본 모델의 강력한 후보 모델이 되었습니다. "5배의 처리량, 포괄적인 성능을 포괄하는 Transformer: 새로운 아키텍처 Mamba가 AI 서클을 폭파합니다"를 참조하세요.
Mixed Experts
MoE(혼합 전문가) 기술은 모델 추론 및 훈련에 필요한 FLOP에 영향을 주지 않고 모델의 매개변수 수를 크게 늘릴 수 있습니다. MoE는 1991년 Jacobs et al.에 의해 처음 제안되었으며 2017년 Shazeer et al.에 의해 NLP 작업에 사용되기 시작했습니다.
MoE에는 장점이 있습니다. 활성화가 매우 희박합니다. 처리된 각 토큰에 대해 모델 매개변수의 작은 부분만 사용됩니다. 계산 요구 사항으로 인해 Transformer의 순방향 계층은 여러 MoE 기술의 표준 대상이 되었습니다.
연구 커뮤니티에서는 라우팅 프로세스라고도 알려진 전문가에게 토큰을 할당하는 프로세스인 MoE의 핵심 문제를 해결하기 위해 다양한 방법을 제안했습니다. 현재 토큰 선택(Token Choice)과 전문가 선택(Expert Choice)이라는 두 가지 기본 라우팅 알고리즘이 있습니다. 전자는 각 토큰을 특정 수(K)의 전문가에게 라우팅하는 것이고, 후자는 각 토큰을 고정된 수의 전문가에게 라우팅하는 것입니다.
Fedus et al.은 2022년 논문 "Switch Transformers: Scaling to t조 매개변수 모델을 간단하고 효율적인 희소성"에서 제안했습니다. 이는 각 토큰을 단일 전문가(K=1)에게 라우팅하는 토큰 선택 아키텍처입니다. 그들은 이 방법을 사용하여 Transformer의 매개변수 크기를 1조 6천억까지 성공적으로 확장했습니다. 폴란드의 이 팀도 실험에 이 MoE 설계를 사용했습니다.
최근에는 MoE에서도 OpenMoE와 같은 오픈소스 커뮤니티에 진출하기 시작했습니다.
프로젝트 주소: https://github.com/XueFuzhao/OpenMoE
Mistral의 오픈 소스 Mixtral 8×7B는 추론 계산이 필요하면서도 LLaMa 2 70B와 비슷한 성능을 가지고 있다는 점을 언급할 가치가 있습니다. 예산은 후자의 약 6분의 1에 불과합니다.
Mamba의 주요 기본 메커니즘은 Transformer에서 사용되는 어텐션 메커니즘과 상당히 다르지만 Mamba는 Transformer 모델의 상위 수준 모듈 기반 구조를 유지합니다. 이 패러다임을 사용하면 동일한 모듈로 구성된 하나 이상의 레이어가 서로 쌓이고 각 레이어의 출력이 잔여 스트림에 추가됩니다(그림 2 참조). 그런 다음 이 잔여 스트림의 최종 값은 언어 모델링 작업을 위한 다음 토큰을 예측하는 데 사용됩니다.
MoE-Mamba는 이 두 아키텍처의 호환성을 활용합니다. 그림 2에서 볼 수 있듯이 MoE-Mamba에서는 모든 간격 Mamba 계층이 스위치 기반 MoE 피드포워드 계층으로 대체됩니다.
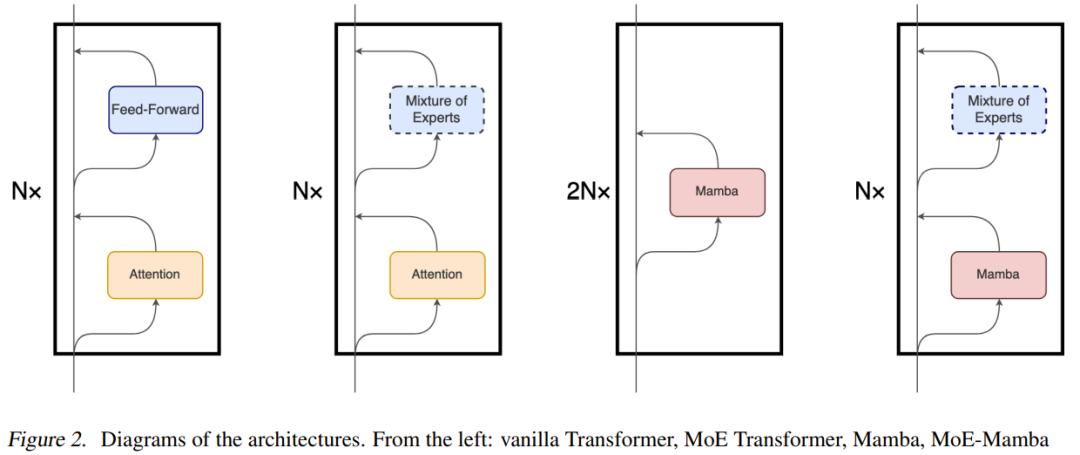
그러나 팀은 이 디자인이 "Mamba: 선택적 상태 공간을 사용한 선형 시간 시퀀스 모델링"의 디자인과 다소 유사하다는 점에도 주목했습니다. 후자는 Mamba 레이어와 피드포워드 레이어를 교대로 쌓지만 그 결과는 모델은 단순한 Mamba보다 약간 열등합니다. 이 디자인은 그림 1에서 Mamba-MLP로 표시됩니다.
MoE-Mamba는 Mamba 계층에서 수행되는 각 토큰의 무조건 처리와 MoE 계층에서 수행되는 조건부 처리를 분리하여 시퀀스의 전체 컨텍스트를 내부 표현으로 효율적으로 통합할 수 있으며, 조건부 처리는 처리는 각 토큰에 가장 관련성이 높은 전문가를 사용할 수 있습니다. 조건부 처리와 무조건부 처리를 번갈아 수행한다는 아이디어는 일부 MoE 기반 모델에 적용되었지만 일반적으로 기본 및 MoE 피드포워드 레이어를 번갈아 사용합니다.
교육 설정
팀에서는 Basic Transformer, Mamba, Mamba-MLP, MoE 및 MoE-Mamba의 5가지 설정을 비교했습니다.
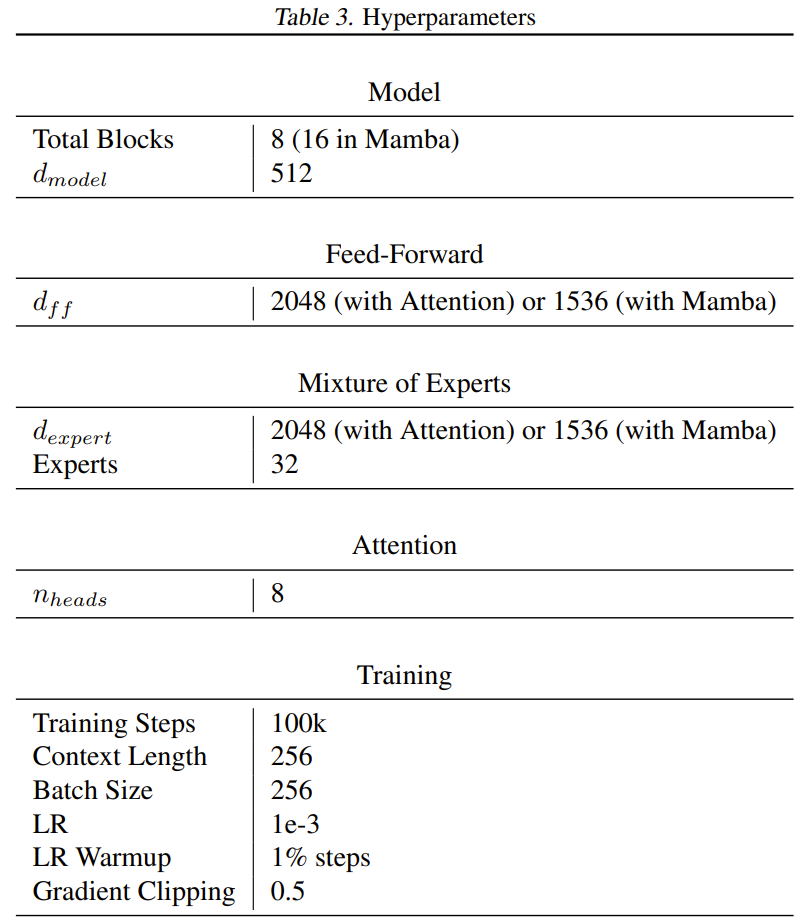
대부분의 Transformer에서 피드포워드 레이어에는 8dm² 매개변수가 포함되어 있는 반면, Mamba 종이는 Mamba를 더 작게(약 6dm²) 만들어 두 개의 Mamba 레이어의 매개변수 수가 피드포워드 레이어 1개와 어텐션 레이어 1개와 거의 같아 보입니다. 똑같다. Mamba와 새 모델에서 토큰당 대략 동일한 수의 활성 매개변수를 얻기 위해 팀은 각 전문가 전달 레이어의 크기를 6dm²로 줄였습니다. 포함 및 포함 해제 레이어를 제외하고 모든 모델은 토큰당 약 2,600만 개의 매개변수를 사용합니다. 훈련 과정에는 65억 개의 토큰이 사용되며 훈련 단계 수는 100,000개입니다.
훈련에 사용된 데이터 세트는 영어 C4 데이터 세트이며, 작업은 다음 토큰을 예측하는 것입니다. 텍스트는 GPT2 토크나이저를 사용하여 토큰화됩니다. 표 3은 하이퍼파라미터의 전체 목록을 제공합니다.
Results
표 1은 훈련 결과를 제공합니다. MoE-Mamba는 일반 Mamba 모델보다 성능이 훨씬 뛰어납니다.
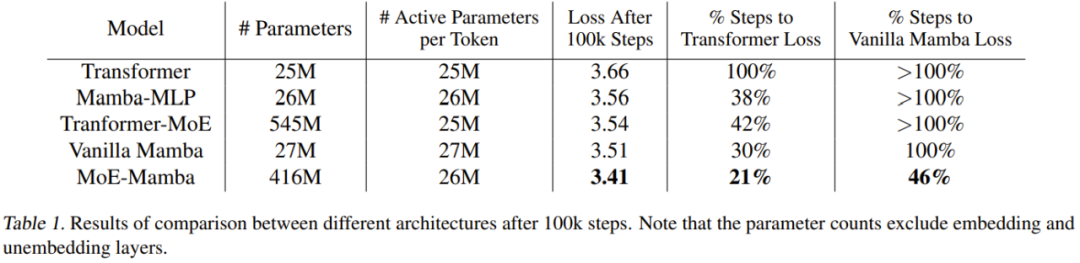
MoE-Mamba가 단 46%의 훈련 단계만으로 일반 Mamba와 동일한 수준의 결과를 달성한다는 점은 주목할 가치가 있습니다. 일반적인 Mamba에 맞춰 학습률을 조정하였기 때문에 학습 과정을 MoE-Mamba에 최적화하면 MoE-Mamba의 성능이 더 좋아질 것으로 예상할 수 있습니다.
전문가 수가 증가함에 따라 Mamba가 확장되는지 평가하기 위해 연구원들은 다양한 수의 전문가를 사용하여 모델을 비교했습니다.
그림 3은 다양한 수의 전문가를 사용할 때의 훈련 실행 단계를 보여줍니다.
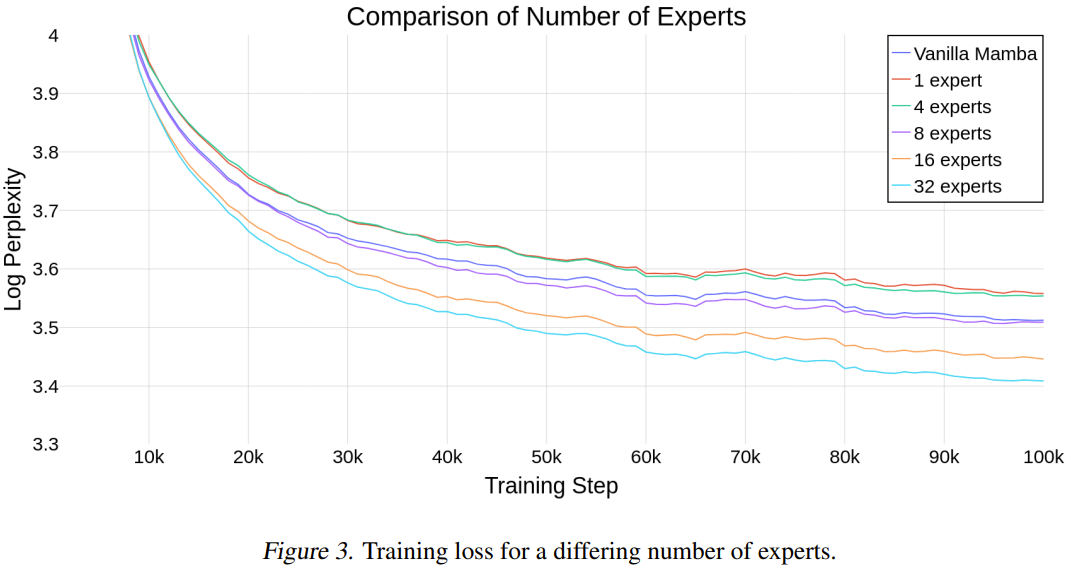
표 2는 100,000걸음 이후의 결과를 보여줍니다.
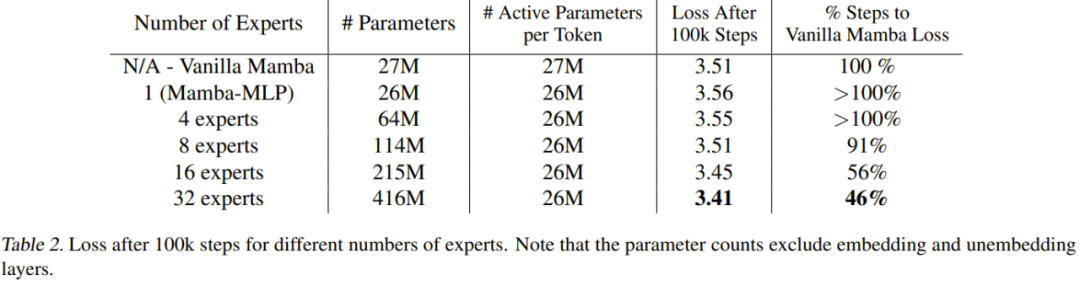
이 결과는 새로 제안된 방법이 전문가 수에 따라 잘 확장된다는 것을 보여줍니다. 전문가 수가 8명 이상이면 신형 모델의 최종 성능이 일반 맘바보다 좋다. Mamba-MLP는 일반 Mamba보다 성능이 떨어지기 때문에 소수의 전문가를 활용한 MoE-Mamba가 Mamba보다 성능이 좋지 않을 것으로 예상할 수 있습니다. 새로운 방법은 전문가 수가 32명일 때 가장 좋은 결과를 보였다.
위 내용은 MoE와 Mamba는 협력하여 상태공간 모델을 수십억 개의 매개변수로 확장합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



