

오픈소스 MoE 모델이 드디어 국내 최초 플레이어를 맞이합니다!
성능은 Dense Llama 2-7B 모델에 뒤지지 않지만 계산량이 40%에 불과합니다.
이 모델은 19면 전사라고 할 수 있는데, 특히 수학과 코딩 능력 면에서 라마를 압도하는 모델입니다.
Deep Search 팀이 개발한 최신 오픈소스 160억 매개변수 전문가 모델 DeepSeek MoE입니다.
뛰어난 성능 외에도 DeepSeek MoE의 주요 초점은 컴퓨팅 성능을 절약하는 것입니다.
이 성능 활성화 매개변수 다이어그램에서는 "선택"되어 왼쪽 상단 모서리의 큰 공백 영역을 차지합니다.
공개된 지 하루 만에 DeepSeek 팀의 X 트윗은 많은 수의 리트윗과 관심을 받았습니다.
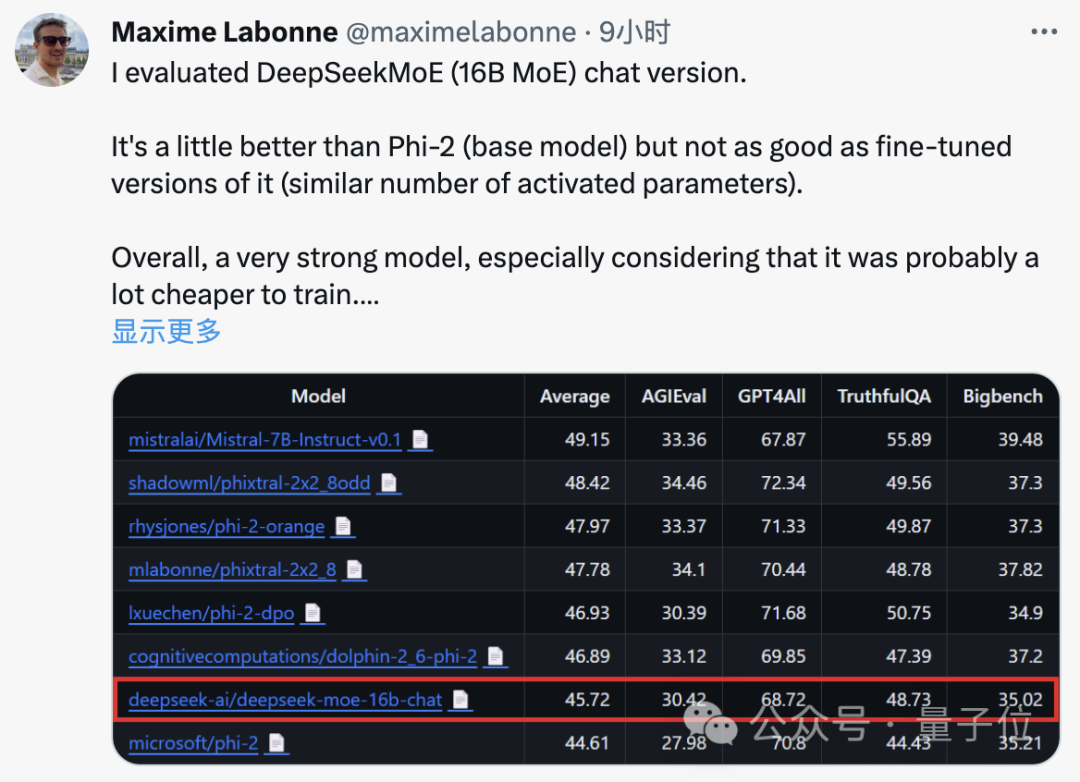
JP Morgan의 기계 학습 엔지니어인 Maxime Labonne도 테스트 후 DeepSeek MoE의 채팅 버전이 Microsoft의 "소형 모델" Phi-2보다 약간 더 나은 성능을 발휘한다고 말했습니다.
동시에 DeepSeek MoE도 GitHub에서 별 300개 이상을 받고 Hugging Face 텍스트 생성 모델 순위 홈페이지에 등장했습니다.
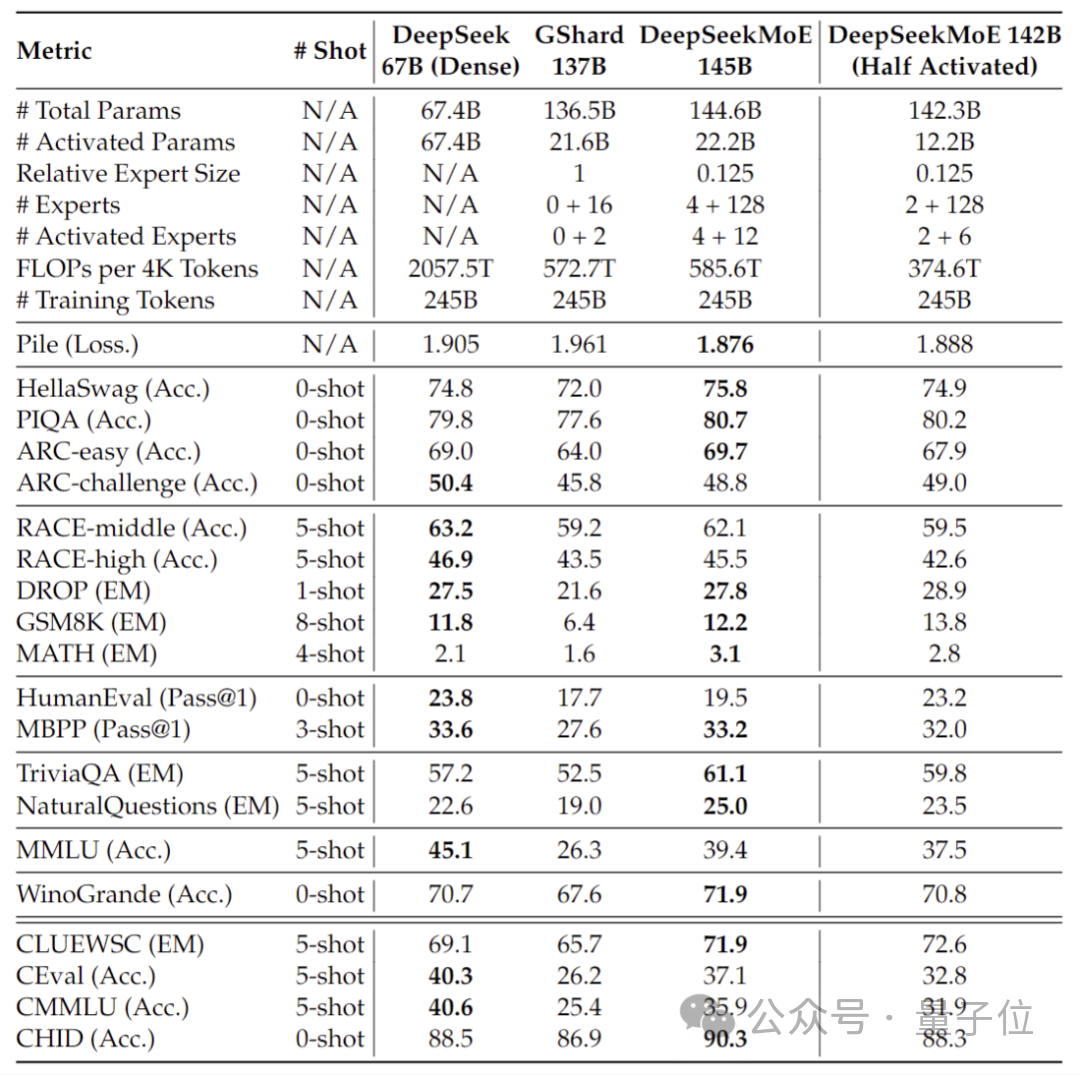
그럼 DeepSeek MoE의 구체적인 성능은 어떤가요?
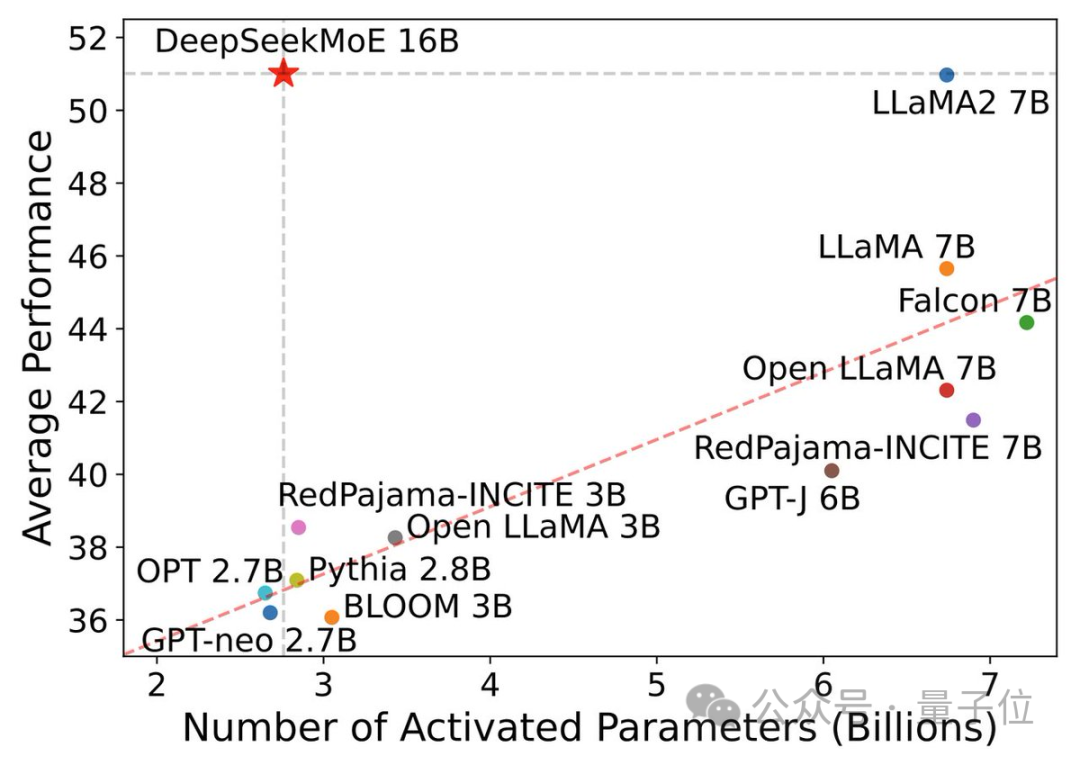
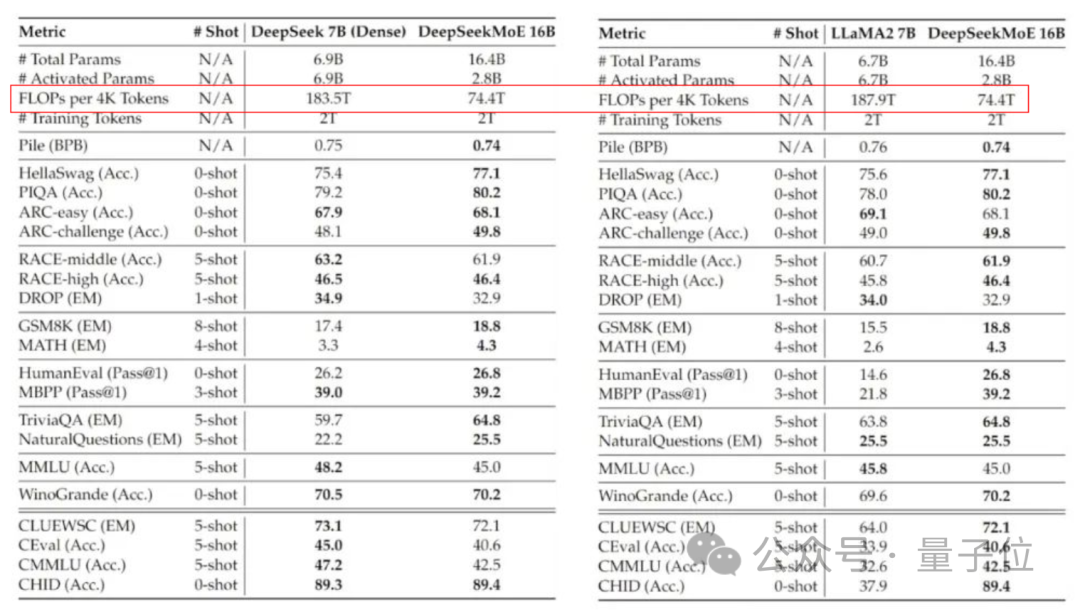
DeepSeek MoE의 현재 버전에는 160억 개의 매개변수가 있으며, 실제 활성화되는 매개변수 수는 약 28억 개입니다.
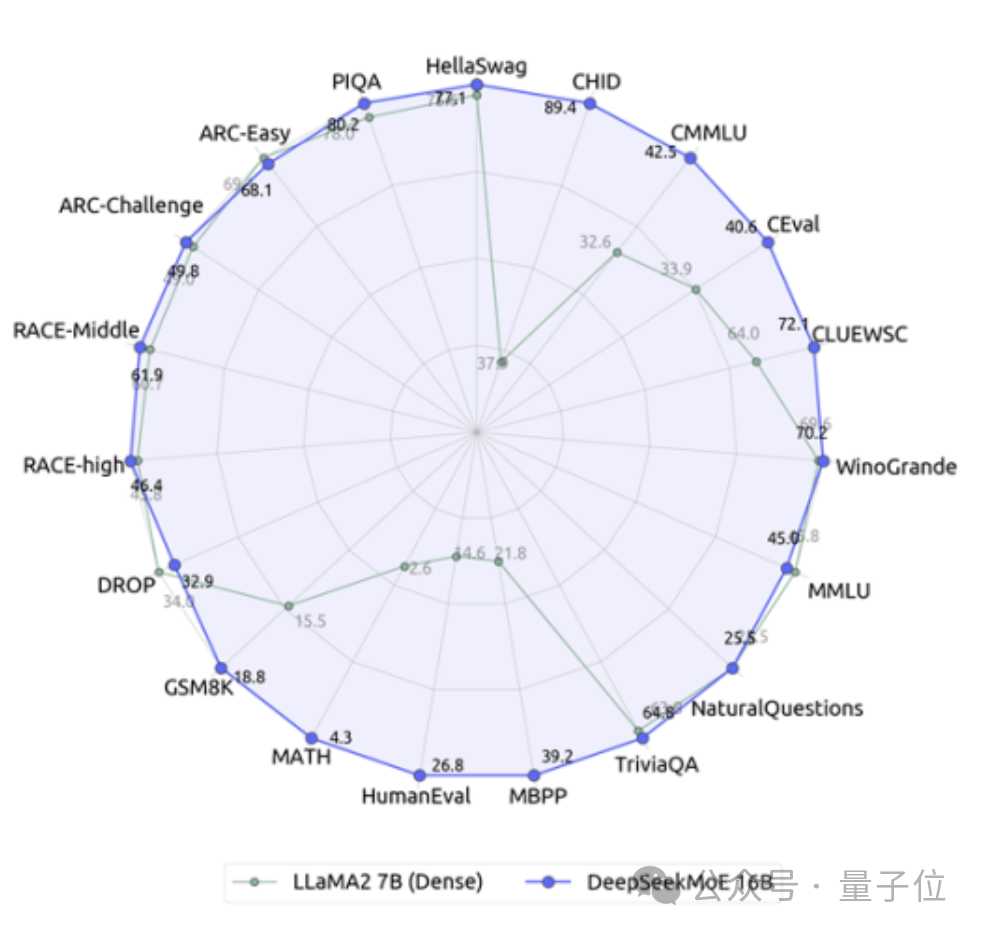
자체 7B 밀도 모델과 비교하면 19개 데이터 세트에서 두 가지의 성능은 다르지만 전체적인 성능은 비교적 비슷합니다.
역시 밀도가 높은 모델인 Llama 2-7B와 비교하여 DeepSeek MoE는 수학, 코드 등에서도 확실한 이점을 보여줍니다.
그러나 두 밀도 모델의 계산 부하는 4k 토큰당 180TFLOP를 초과하는 반면 DeepSeek MoE는 74.4TFLOP에 불과하며 이는 둘의 40%에 불과합니다.
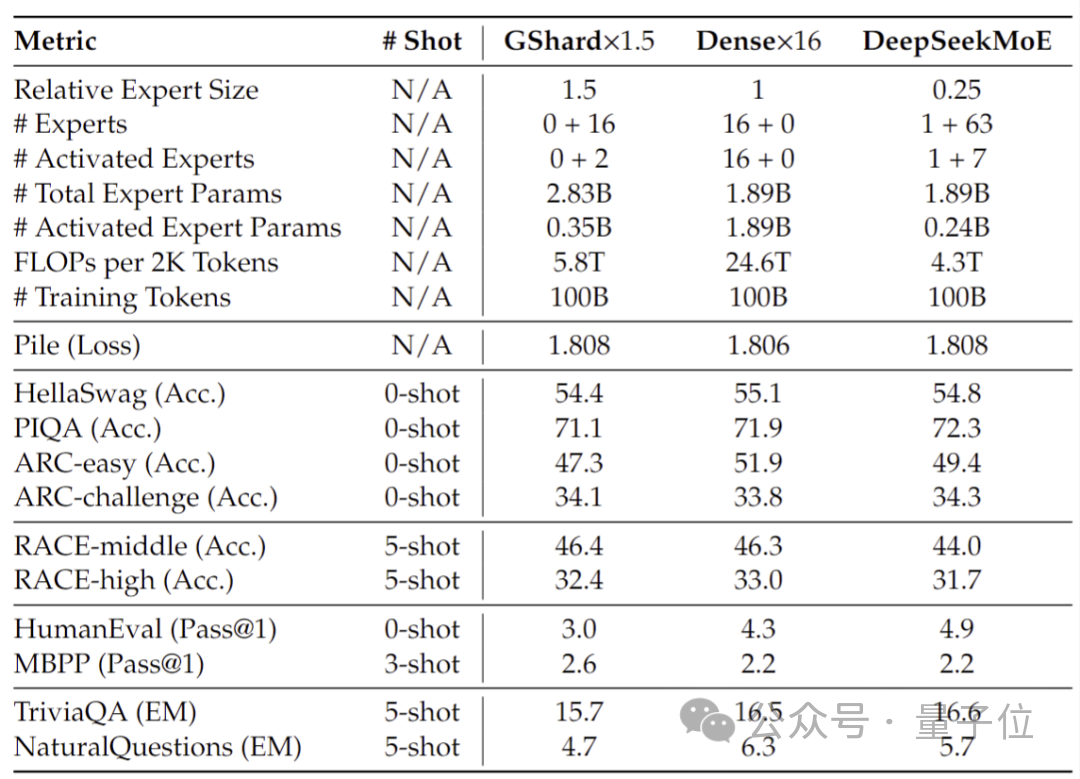
20억 개의 매개변수에서 수행된 성능 테스트에 따르면 DeepSeek MoE는 GShard 2.8B와 동등하거나 더 나은 결과를 얻을 수도 있습니다. GShard 2.8B는 매개변수 수가 1.5배 더 많고 계산을 덜 사용하는 MoE 모델이기도 합니다.
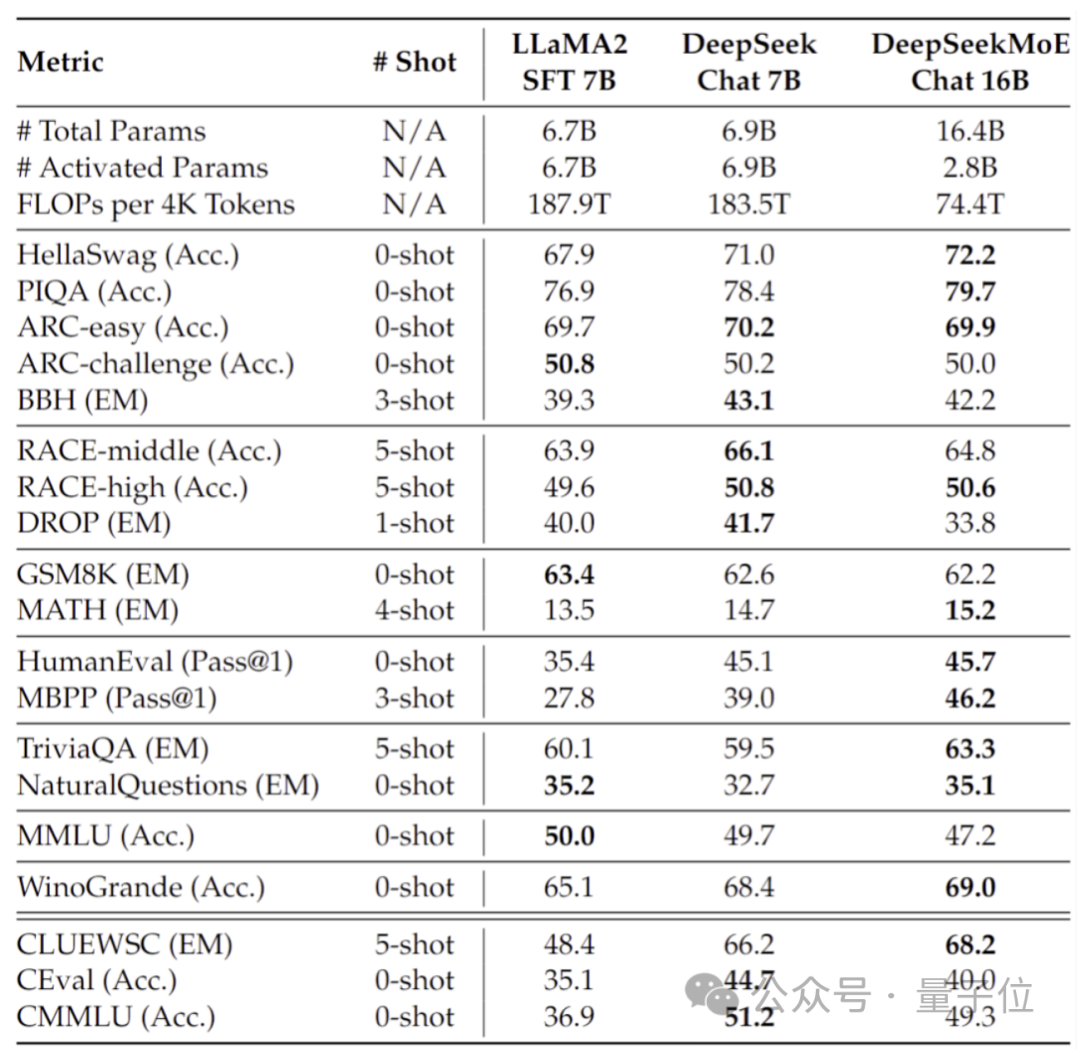
또한 Deep Seek 팀은 SFT를 기반으로 DeepSeek MoE의 Chat 버전을 미세 조정했으며 성능도 자체 Dense 버전 및 Llama 2-7B에 가깝습니다.
또한 DeepSeek 팀은 DeepSeek MoE 모델의 145B 버전이 개발 중이라고 밝혔습니다.
단계별 예비 실험에서는 145B DeepSeek MoE가 GShard 137B에 비해 큰 우위를 갖고 있으며 계산량의 28.5%로 DeepSeek 67B 모델의 밀집 버전과 동등한 성능을 달성할 수 있는 것으로 나타났습니다.
연구 개발이 완료된 후 팀은 145B 버전도 오픈 소스화할 예정입니다.
이 모델의 성능 뒤에는 DeepSeek의 새로운 자체 개발 MoE 아키텍처가 있습니다.
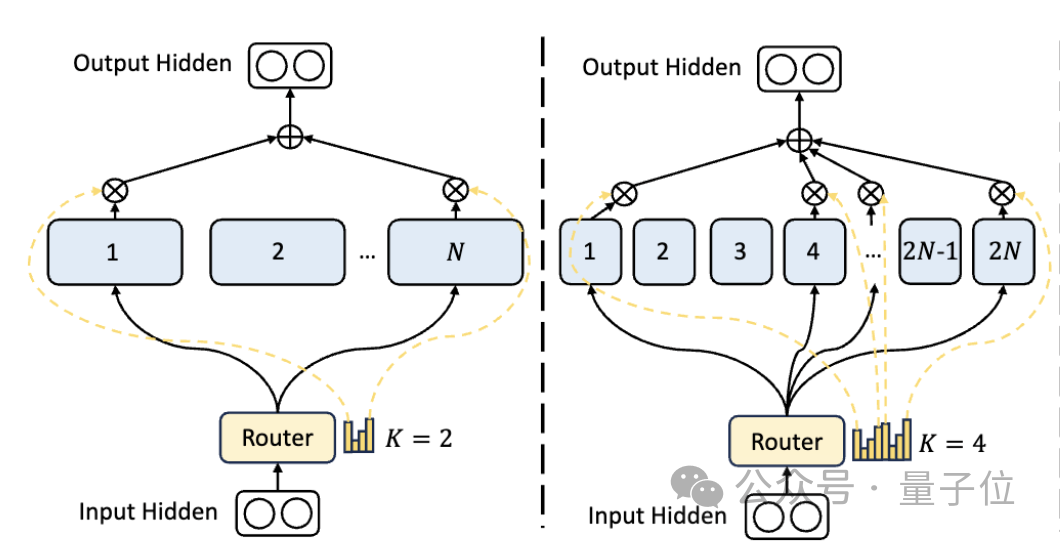
우선, 기존 MoE 아키텍처에 비해 DeepSeek은 더욱 세분화된 전문가 부서를 보유하고 있습니다.
전체 매개변수 수가 고정되면 기존 모델은 N명의 전문가를 분류할 수 있지만 DeepSeek은 2N명의 전문가를 분류할 수 있습니다.
동시에 작업을 수행할 때마다 선택되는 전문가의 수가 기존 모델의 2배이므로 사용되는 매개변수의 전체 수는 동일하게 유지되지만 선택의 자유도는 증가합니다.
이 세분화 전략을 통해 활성화 전문가의 보다 유연하고 적응력 있는 조합이 가능해지며, 이를 통해 다양한 작업에 대한 모델의 정확도와 지식 획득의 타당성이 향상됩니다.
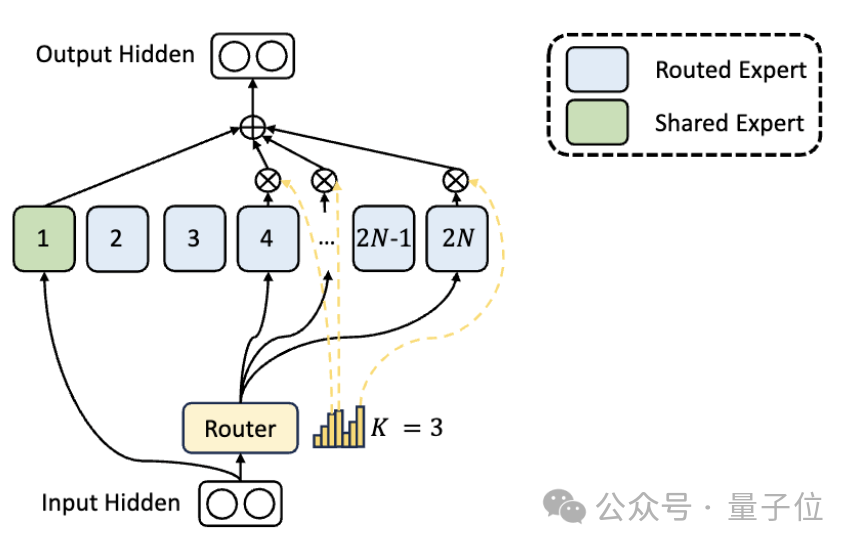
DeepSeek은 전문가 부문의 차이점 외에도 "전문가 공유" 설정도 혁신적으로 도입합니다.
이러한 공유 전문가는 모든 입력에 대해 토큰을 활성화하며 라우팅 모듈의 영향을 받지 않습니다. 목적은 다양한 상황에서 필요한 공통 지식을 포착하고 통합하는 것입니다.
이러한 공유 지식을 공유 전문가로 압축하면 다른 전문가 간의 매개변수 중복이 줄어들어 모델의 매개변수 효율성이 향상됩니다.
공유 전문가 설정은 다른 전문가가 자신의 고유한 지식 영역에 더 집중할 수 있도록 도와줌으로써 전반적인 전문가 전문성 수준을 높여줍니다.
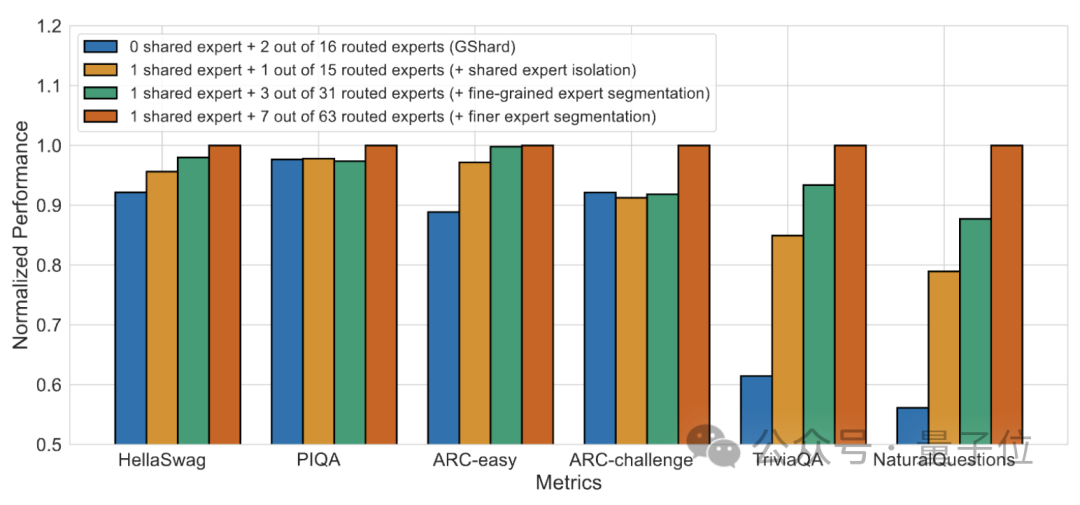
Ablation 실험 결과 두 솔루션 모두 DeepSeek MoE의 "비용 절감 및 효율성 향상"에 중요한 역할을 한 것으로 나타났습니다.
논문 주소: https://arxiv.org/abs/2401.06066.
참조 링크: https://mp.weixin.qq.com/s/T9-EGxYuHcGQgXArLXGbgg.
위 내용은 국내 대형 오픈소스 MoE 모델을 도입해 성능은 라마 2-7B와 비슷하면서도 연산량은 60% 줄였다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



