

Apple의 이 새로운 작품은 미래의 iPhone에 대형 모델을 추가하는 능력에 무한한 상상력을 불어넣을 것입니다.
최근에는 GPT-3, OPT, PaLM과 같은 LLM(대형 언어 모델)이 광범위한 NLP(자연어 처리) 작업에서 강력한 성능을 보여주었습니다. 그러나 이러한 성능을 달성하려면 광범위한 계산 및 메모리 추론이 필요합니다. 이러한 대규모 언어 모델에는 수천억 또는 심지어 수조 개의 매개변수가 포함될 수 있으므로 리소스가 제한된 장치에서 효율적으로 로드하고 실행하는 것이 어렵습니다.
현재 표준 솔루션은 로드하는 것입니다. 추론을 위해 전체 모델을 DRAM에 저장하지만 이로 인해 실행할 수 있는 최대 모델 크기가 심각하게 제한됩니다. 예를 들어, 70억 개의 매개변수 모델의 경우 매개변수를 반정밀도 부동 소수점 형식으로 로드하려면 14GB 이상의 메모리가 필요하며 이는 대부분의 엣지 장치의 기능을 뛰어넘습니다.
이러한 한계를 해결하기 위해 Apple 연구진은 모델 매개변수를 DRAM보다 최소한 한 자릿수 더 큰 플래시 메모리에 저장할 것을 제안했습니다. 그런 다음 추론 중에 필요한 매개변수를 직접적이고 교묘하게 플래시 로드하여 전체 모델을 DRAM에 맞출 필요가 없습니다.
이 접근 방식은 LLM이 FFN(피드포워드 네트워크) 계층에서 높은 수준의 희소성을 나타내며 OPT 및 Falcon과 같은 모델이 90%를 초과하는 희소성을 달성한다는 것을 보여주는 최근 연구를 기반으로 합니다. 따라서 우리는 이 희소성을 활용하여 입력이 0이 아니거나 출력이 0이 아닌 것으로 예측되는 매개변수만 플래시 메모리에서 선택적으로 로드합니다.

논문 주소: https://arxiv.org/pdf/2312.11514.pdf
특히 연구원들은 플래시 메모리, DRAM 및 컴퓨팅 코어(CPU 또는 GPU)를 포함하는 하드웨어에서 영감을 받은 비용 모델에 대해 논의했습니다. 그런 다음 데이터 전송을 최소화하고 플래시 처리량을 최대화하기 위해 두 가지 보완 기술이 도입되었습니다.
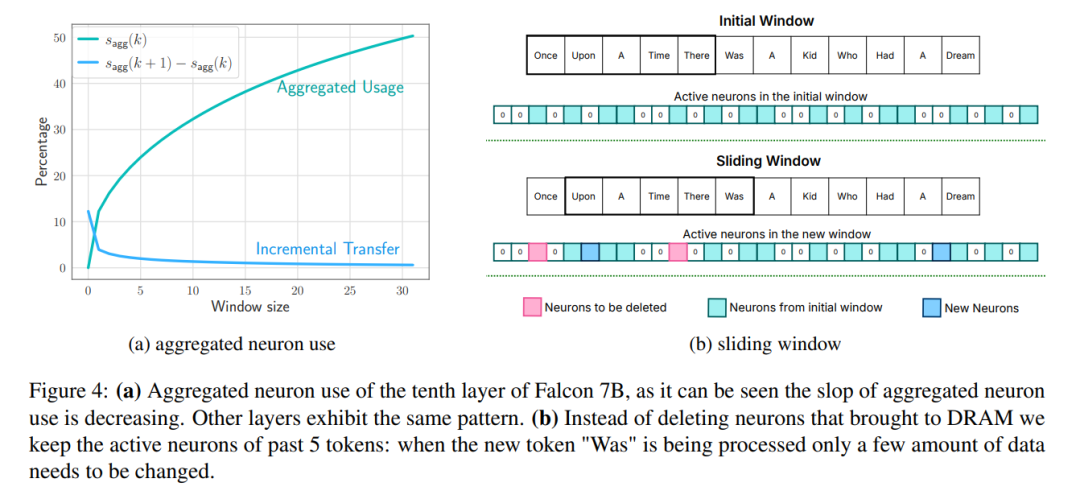
창: 처음 몇 개 태그의 매개변수만 로드하고 가장 최근에 계산된 태그의 활성화를 재사용합니다. 이 슬라이딩 윈도우 접근 방식은 가중치를 로드하기 위한 IO 요청 수를 줄입니다.
행 및 행 번들링: 위쪽 및 아래쪽 투영 레이어의 연결된 행과 열을 저장하여 더 큰 연속 플래시 메모리 블록을 읽습니다. 이렇게 하면 더 큰 블록을 읽어 처리량이 늘어납니다.
플래시에서 DRAM으로 전송되는 가중치 수를 더욱 줄이기 위해 연구원들은 FFN의 희소성을 예측하고 제로화 매개변수 로드를 방지하려고 노력했습니다. 윈도우잉과 희소성 예측의 조합을 사용하면 추론 쿼리당 플래시 FFN 레이어의 2%만 로드됩니다. 또한 내부 DRAM 전송을 최소화하고 추론 지연 시간을 줄이기 위해 정적 메모리 사전 할당을 제안했습니다.
이 백서의 플래시 로드 비용 모델은 더 나은 데이터 로드와 더 큰 청크 읽기 간의 균형을 유지합니다. 이 비용 모델을 최적화하고 필요에 따라 매개변수를 선택적으로 로드하는 플래시 전략은 CPU 및 GPU 시간의 순진한 구현에 비해 두 배의 DRAM 용량으로 모델을 실행하고 추론 속도를 각각 4~5배 및 20~25배 향상시킬 수 있습니다.
몇몇 사람들은 이 작업이 iOS 개발을 더욱 흥미롭게 만들 것이라고 말했습니다.
플래시 및 LLM 추론
대역폭 및 에너지 제한
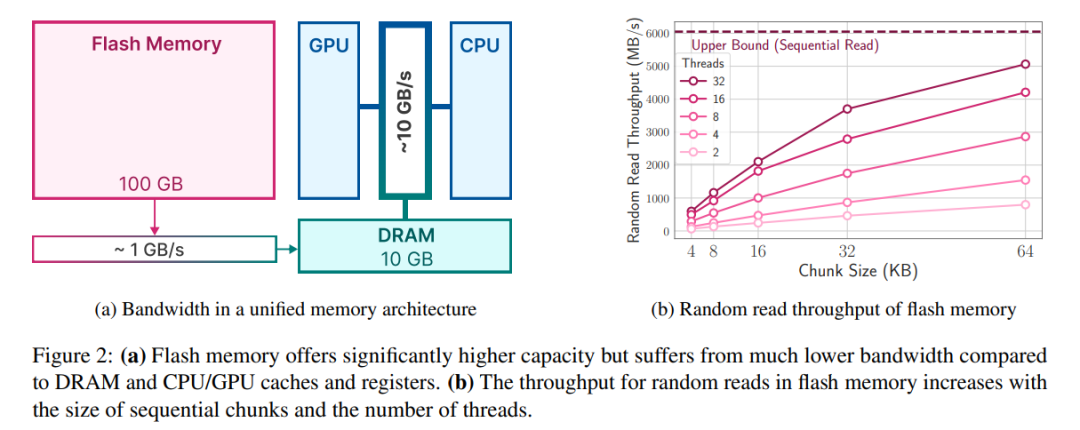
최신 NAND 플래시는 높은 대역폭과 낮은 대기 시간을 제공하지만, 특히 메모리가 제한된 시스템에서는 여전히 DRAM 성능 수준에 미치지 못합니다. 아래 그림 2a는 이러한 차이점을 보여줍니다.
NAND 플래시에 의존하는 순진한 추론 구현은 각 순방향 패스마다 전체 모델을 다시 로드해야 할 수 있습니다. 이는 모델을 압축하는 데에도 몇 초가 걸릴 만큼 시간이 많이 걸리는 프로세스입니다. 또한 DRAM에서 CPU 또는 GPU 메모리로 데이터를 전송하려면 더 많은 에너지가 필요합니다.
DRAM이 충분한 시나리오에서는 데이터 로딩 비용이 줄어들고 모델이 DRAM에 상주할 수 있습니다. 그러나 모델의 초기 로딩은 특히 첫 번째 토큰에 빠른 응답 시간이 필요한 경우 여전히 에너지를 소비합니다. 우리의 방법은 LLM의 활성화 희소성을 활용하여 모델 가중치를 선택적으로 읽어 이러한 문제를 해결함으로써 시간과 에너지 비용을 줄입니다.
다음으로 표현: 데이터 전송 속도 얻기
플래시 시스템은 많은 순차 읽기에서 가장 좋은 성능을 발휘합니다. 예를 들어 Apple MacBook Pro M2에는 2TB의 플래시 메모리가 장착되어 있으며, 벤치마크 테스트에서 캐시되지 않은 파일 1GiB의 선형 읽기 속도가 6GiB/s를 초과했습니다. 그러나 운영 체제, 드라이버, 중급 프로세서 및 플래시 컨트롤러를 포함하여 이러한 읽기의 다단계 특성으로 인해 소규모 무작위 읽기는 이러한 높은 대역폭을 달성할 수 없습니다. 각 단계마다 대기 시간이 발생하며 이는 더 작은 읽기 속도에 더 큰 영향을 미칩니다.
이러한 제한을 피하기 위해 연구자들은 동시에 사용할 수 있는 두 가지 주요 전략을 옹호합니다.
첫 번째 전략은 더 큰 데이터 블록을 읽는 것입니다. 처리량의 증가는 선형적이지 않지만(더 큰 데이터 블록에는 더 긴 전송 시간이 필요함) 초기 바이트의 지연은 총 요청 시간에서 더 작은 부분을 차지하므로 데이터 읽기가 더 효율적입니다. 그림 2b는 이 원리를 보여줍니다. 반직관적이지만 흥미로운 관찰은 어떤 경우에는 필요한 것보다 더 많은 데이터(그러나 더 큰 청크)를 읽은 다음 이를 삭제하는 것이 필요한 것만 작은 청크로 읽는 것보다 빠르다는 것입니다.
두 번째 전략은 스토리지 스택과 플래시 컨트롤러의 고유한 병렬성을 활용하여 병렬 읽기를 달성하는 것입니다. 결과는 표준 하드웨어에서 32KiB 이상의 다중 스레드 무작위 읽기를 사용하여 희소 LLM 추론에 적합한 처리량을 달성할 수 있음을 보여줍니다.
처리량을 최대화하는 열쇠는 가중치가 저장되는 방식에 있습니다. 평균 블록 길이를 늘리는 레이아웃은 대역폭을 크게 늘릴 수 있기 때문입니다. 어떤 경우에는 데이터를 더 작고 덜 효율적인 청크로 분할하는 것보다 초과 데이터를 읽고 나중에 삭제하는 것이 유익할 수 있습니다.
플래시 로딩
위의 과제에서 영감을 받아 연구원들은 데이터 전송량을 최적화하고 데이터 전송 속도를 향상시키는 방법을 제안했습니다. 이는 다음과 같이 표현될 수 있습니다. 추론 속도를 크게 향상시키기 위해 데이터 전송 속도를 얻습니다. 이 섹션에서는 사용 가능한 계산 메모리가 모델 크기보다 훨씬 작은 장치에서 추론을 수행하는 과제에 대해 설명합니다.
이 과제를 분석하려면 전체 모델 중량을 플래시 메모리에 저장해야 합니다. 연구자들이 다양한 플래시 로딩 전략을 평가하기 위해 사용하는 기본 지표는 지연 시간이며, 이는 플래시 로드를 수행하는 I/O 비용, 새로 로드된 데이터를 관리하는 데 필요한 메모리 오버헤드, 플래시 로드의 계산 비용이라는 세 가지 구성 요소로 나뉩니다. 추론 연산.
Apple은 메모리 제약 하에서 지연 시간을 줄이기 위한 솔루션을 각각 지연 시간의 특정 측면을 목표로 하는 세 가지 전략적 영역으로 나눕니다.
1. 데이터 로드 감소: 플래시 I/O 작업과 관련된 지연 시간을 줄여서 지연 시간을 줄이는 것을 목표로 합니다.
2. 데이터 블록 크기 최적화: 로드된 데이터 블록의 크기를 늘려 플래시 처리량을 향상시켜 대기 시간을 줄입니다.
다음은 연구자들이 플래시 읽기 효율성을 높이기 위해 데이터 블록 크기를 늘리기 위해 사용하는 전략입니다.
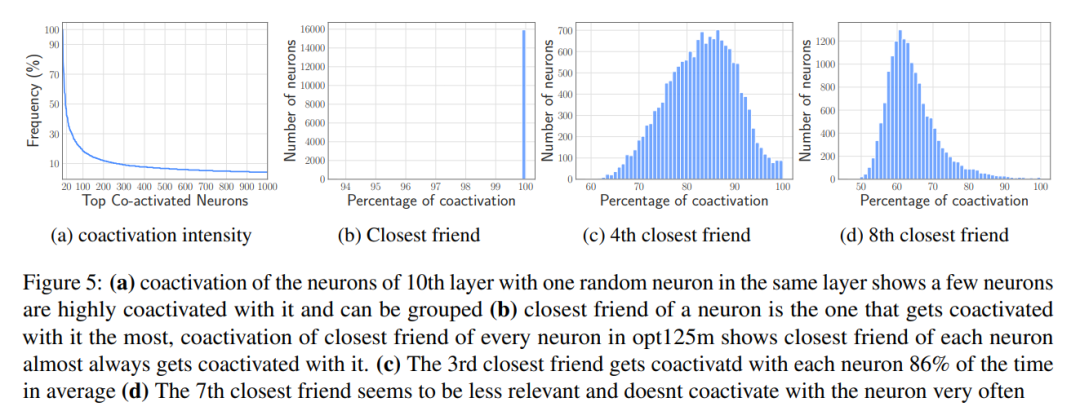
열과 행 묶기
Co-activation 기반 묶기
3. 효과적인 관리 로드된 데이터: 데이터가 메모리에 로드되면 데이터 관리를 단순화하여 오버헤드를 최소화합니다.
DRAM의 데이터 전송은 플래시 메모리에 액세스하는 것보다 효율적이지만 무시할 수 없는 비용이 발생합니다. 새로운 뉴런에 대한 데이터를 도입할 때 행렬을 다시 할당하고 새 행렬을 추가하면 DRAM에 기존 뉴런 데이터를 다시 써야 하기 때문에 상당한 오버헤드가 발생할 수 있습니다. 이는 DRAM의 FFN(피드포워드 네트워크)의 상당 부분(~25%)을 다시 작성해야 할 때 특히 비용이 많이 듭니다.
이 문제를 해결하기 위해 연구원들은 또 다른 메모리 관리 전략을 채택했습니다. 이 전략에는 필요한 모든 메모리를 사전 할당하고 효율적인 관리를 위해 해당 데이터 구조를 설정하는 작업이 포함됩니다. 그림 6에 표시된 것처럼 데이터 구조에는 포인터, 행렬, 오프셋, 사용된 숫자 및 last_k_active와 같은 요소가 포함됩니다.
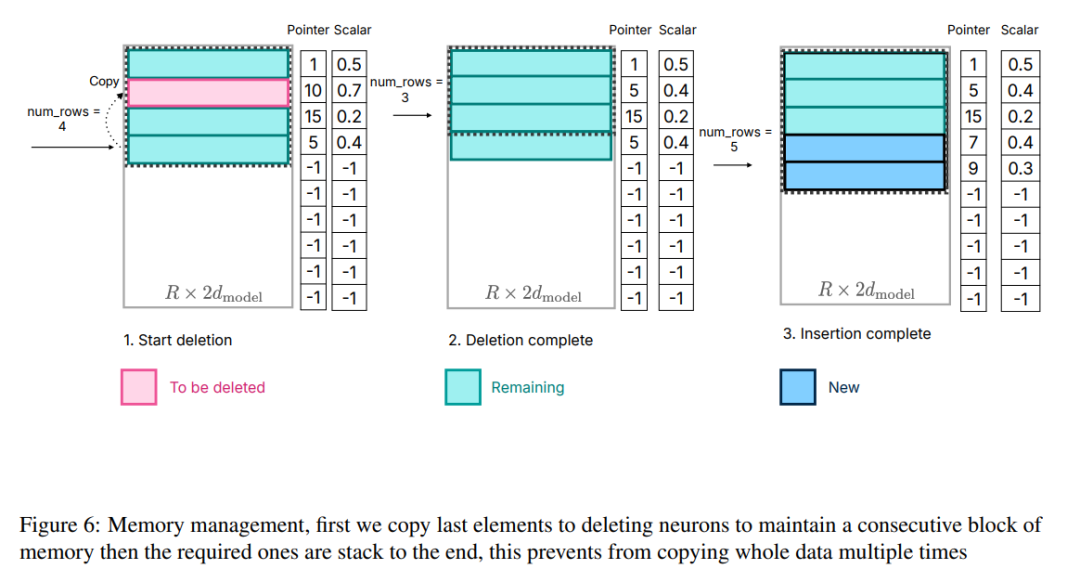
그림 6: 메모리 관리, 먼저 마지막 요소를 삭제 뉴런에 복사하여 연속성을 유지합니다. 메모리 블록을 구성한 다음 필요한 요소를 끝까지 쌓아서 전체 데이터를 여러 번 복사하는 것을 방지합니다.
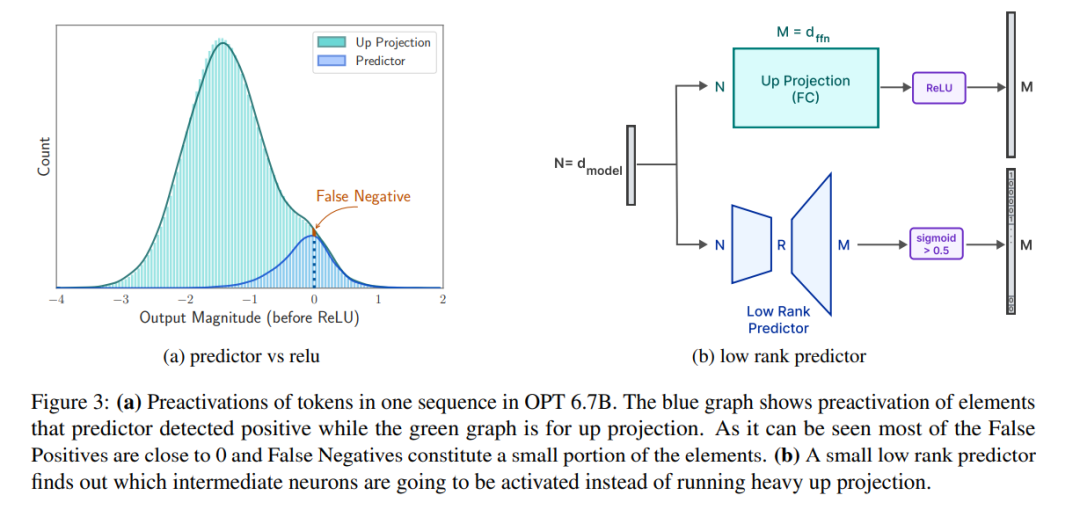
계산 과정에는 초점이 맞춰져 있지 않다는 점에 유의해야 합니다. 이 기사의 핵심 작업과 아무 관련이 없기 때문입니다. 이 파티셔닝을 통해 연구원들은 메모리가 제한된 장치에서 효율적인 추론을 달성하기 위해 플래시 상호 작용 및 메모리 관리 최적화에 집중할 수 있습니다. 그림 3a에서 볼 수 있듯이 우리의 예측자는 대부분의 활성화된 뉴런을 정확하게 식별할 수 있지만 때때로 0에 가까운 값으로 활성화되지 않은 뉴런을 잘못 식별합니다. 0에 가까운 값을 갖는 이러한 거짓 음성 뉴런이 제거된 후에도 최종 출력 결과는 크게 변경되지 않는다는 점은 주목할 가치가 있습니다. 또한 표 1에서 볼 수 있듯이 이러한 예측 정확도 수준은 제로샷 작업에 대한 모델 성능에 부정적인 영향을 미치지 않습니다.
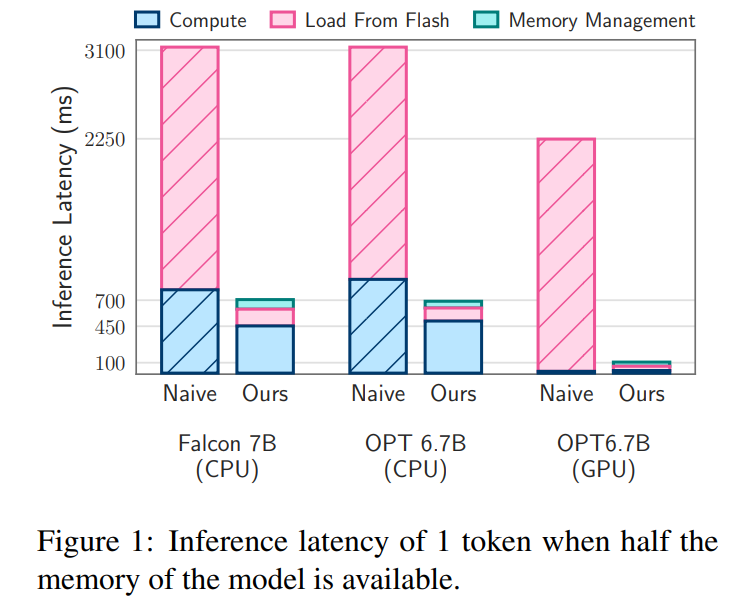
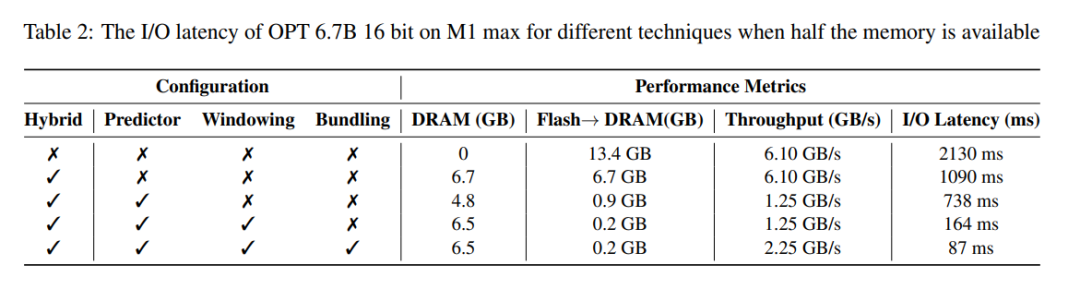
지연 분석. 창 크기가 5인 경우 각 토큰은 FFN(피드포워드 네트워크) 뉴런의 2.4%에 액세스해야 합니다. 32비트 모델의 경우 행과 열의 연결이 포함되므로 읽기당 블록 크기는 2dmodel × 4바이트 = 32KiB입니다. M1 Max에서 토큰당 플래시 로딩 지연 시간은 125밀리초이고, 메모리 관리(뉴런 삭제 및 추가 포함) 지연 시간은 65밀리초입니다. 따라서 총 메모리 관련 대기 시간은 토큰당 190밀리초 미만입니다(그림 1 참조). 이에 비해 기본 접근 방식에서는 6.1GB/s의 속도로 13.4GB의 데이터를 로드해야 하므로 토큰당 약 2330밀리초의 지연 시간이 발생합니다. 따라서 우리의 방법은 기본 방법에 비해 크게 개선되었습니다.
GPU 시스템의 16비트 모델의 경우 플래시 로드 시간은 40.5밀리초로 줄어들고 메모리 관리 시간은 40밀리초로 CPU에서 GPU로 데이터를 전송하는 추가 오버헤드로 인해 약간 증가합니다. 그럼에도 불구하고 기준 방법의 I/O 시간은 여전히 2000ms를 초과합니다.
표 2에서는 각 방법의 성능 영향을 자세히 비교합니다.
Falcon 7B 모델 결과
지연 분석. 우리 모델에서 창 크기 4를 사용하면 각 토큰은 FFN(피드포워드 네트워크) 뉴런의 3.1%에 액세스해야 합니다. 32비트 모델에서 이는 읽기당 블록 크기가 35.5KiB(2dmodel × 4바이트로 계산됨)에 해당합니다. M1 Max 장치에서 이 데이터를 플래시 로드하는 데는 약 161밀리초가 걸리고 메모리 관리 프로세스는 90밀리초를 추가하므로 토큰당 총 대기 시간은 250밀리초입니다. 이에 비해 기본 대기 시간이 약 2330밀리초인 경우 우리의 방법은 약 9~10배 더 빠릅니다.
위 내용은 모델 추론 가속: CPU 성능이 5배 향상되었습니다. Apple은 대규모 추론 가속을 위해 플래시 메모리를 사용합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



