

현재 연구자들은 모두가 수백억, 심지어 수천억에 달하는 매개변수 척도를 가진 대형 모델을 연구하고 있지만, 작고 고성능인 소형 모델에 초점을 맞추기 시작했습니다.
소형 모델은 스마트폰, IoT 기기, 임베디드 시스템 등 엣지 기기에 널리 사용됩니다. 이러한 장치는 컴퓨팅 능력과 저장 공간이 제한되어 있어 대규모 언어 모델을 효율적으로 실행할 수 없는 경우가 많습니다. 따라서 작은 모델을 연구하는 것이 특히 중요합니다.
다음에 소개할 두 가지 연구는 소형 모델에 대한 귀하의 요구를 충족할 수 있습니다.
싱가포르 기술 디자인 대학(SUTD)의 연구원들은 최근 약 3조 개의 토큰 열차에 대해 사전 훈련된 11억 개의 매개변수를 갖춘 언어 모델인 TinyLlama를 출시했습니다.

TinyLlama는 Llama 2 아키텍처 및 토크나이저를 기반으로 하므로 Llama를 사용하는 많은 오픈 소스 프로젝트와 쉽게 통합할 수 있습니다. 또한 TinyLlama는 매개변수가 11억개에 불과하고 크기가 작기 때문에 제한된 계산 및 메모리 공간이 필요한 애플리케이션에 이상적입니다.
연구에 따르면 A100-40G GPU 16개만 90일 안에 TinyLlama 훈련을 완료할 수 있는 것으로 나타났습니다.

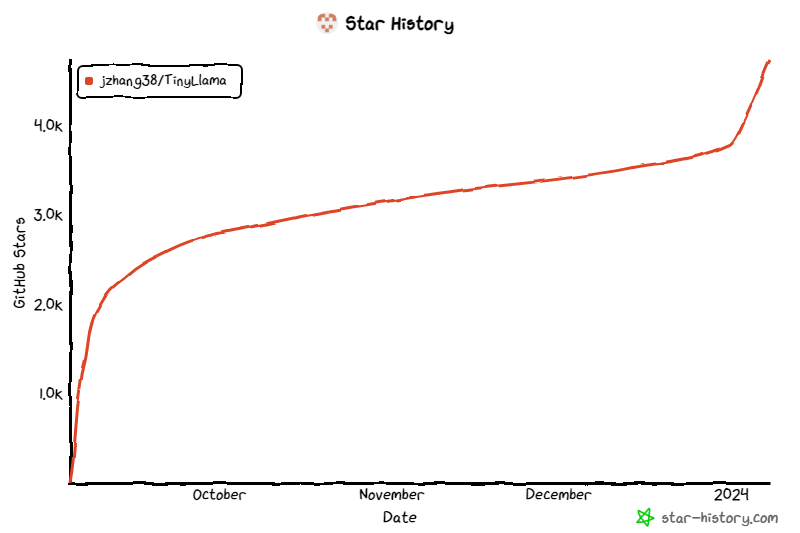
이 프로젝트는 출시 이후 계속해서 주목을 받아 현재 별 수가 4.7K에 이르렀습니다.
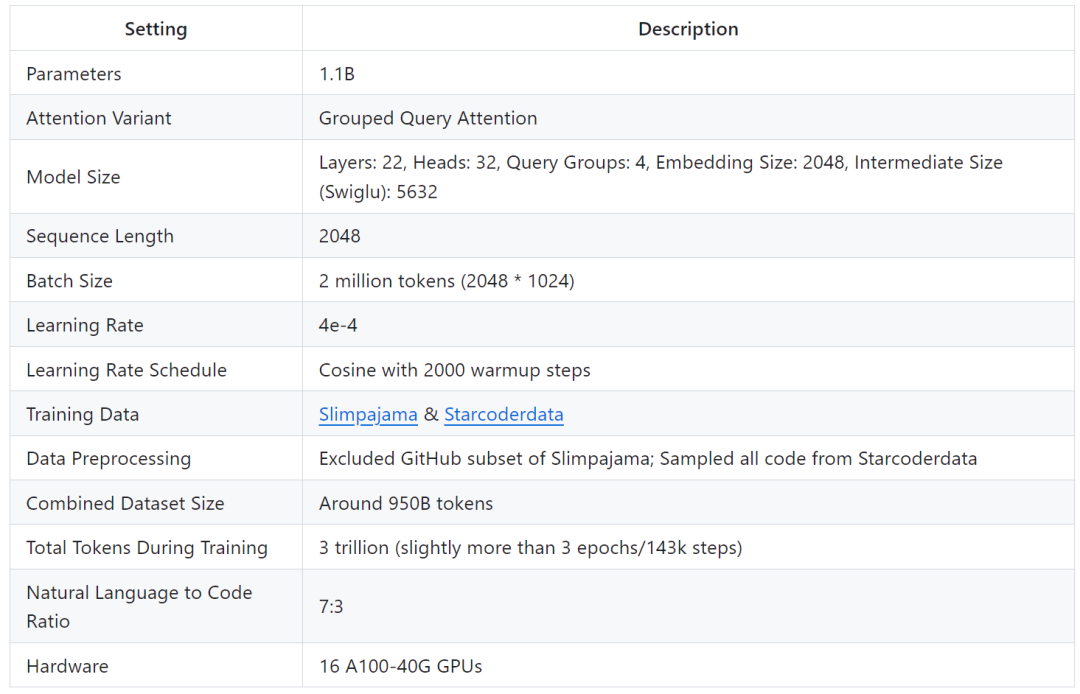
TinyLlama 모델 아키텍처 세부 사항은 다음과 같습니다.

훈련 세부 사항은 다음과 같습니다.
연구원들은 이 연구의 목적이 다음과 같다고 말했습니다. 내 사용은 더 큰 데이터 더 작은 모델을 훈련할 수 있는 가능성. 그들은 확장 법칙에서 권장하는 것보다 훨씬 더 많은 수의 토큰으로 훈련할 때 더 작은 모델의 동작을 탐색하는 데 중점을 두었습니다.
구체적으로, 이 연구에서는 1.1B 매개변수가 있는 Transformer(디코더 전용) 모델을 훈련하기 위해 약 3조 개의 토큰을 사용했습니다. 우리가 아는 한, 이는 1B 매개변수가 있는 모델을 훈련하기 위해 이렇게 많은 양의 데이터를 사용하는 첫 번째 시도입니다.
TinyLlama는 상대적으로 작은 크기에도 불구하고 다양한 다운스트림 작업에서 매우 뛰어난 성능을 발휘하여 동일한 크기의 기존 오픈 소스 언어 모델보다 훨씬 뛰어납니다. 특히 TinyLlama는 다양한 다운스트림 작업에서 OPT-1.3B 및 Pythia1.4B보다 성능이 뛰어납니다.
또한 TinyLlama는 Flash Attention 2, FSDP(Fully Sharded Data Parallel), xFormers 등과 같은 다양한 최적화 방법도 사용합니다.
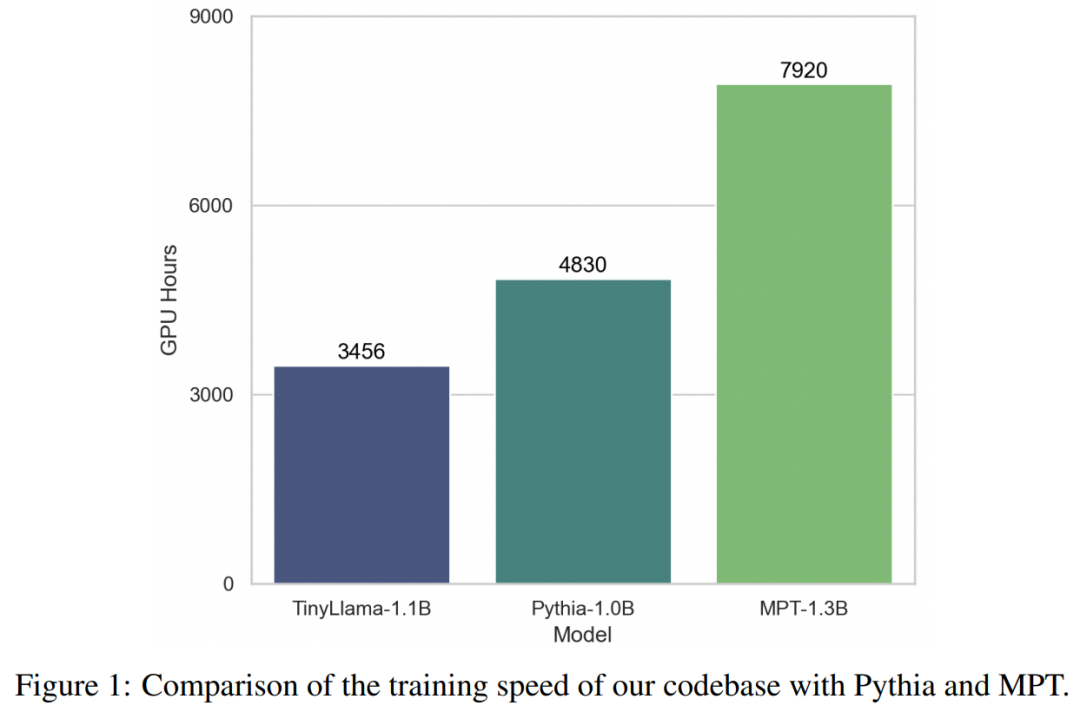
이러한 기술의 지원으로 TinyLlama 교육 처리량은 A100-40G GPU당 초당 24,000개 토큰에 도달합니다. 예를 들어 TinyLlama-1.1B 모델에는 300B 토큰의 경우 A100 GPU 시간이 3,456시간만 필요한 반면, Pythia의 경우 4,830시간, MPT의 경우 7,920시간이 필요합니다. 이는 본 연구 최적화의 효율성과 대규모 모델 훈련에서 상당한 시간과 자원을 절약할 수 있는 잠재력을 보여줍니다.
TinyLlama는 24,000개 토큰/초/A100의 훈련 속도를 달성합니다. 이 속도는 사용자가 8개의 A100에서 32시간 안에 훈련할 수 있는 11억 개의 매개변수와 220억 개의 토큰을 갖춘 친칠라 최적 모델과 동일합니다. 동시에 이러한 최적화를 통해 사용자는 GPU당 배치 크기를 16,000개 토큰으로 유지하면서 11억 개의 매개변수 모델을 40GB GPU에 넣을 수 있습니다. 배치 크기를 조금 더 작게 변경하면 RTX 3090/4090에서 TinyLlama를 훈련시킬 수 있습니다.

실험에서 이 연구는 주로 약 10억 개의 매개변수를 포함하는 순수 디코더 아키텍처를 갖춘 언어 모델에 중점을 두었습니다. 구체적으로 이 연구에서는 TinyLlama를 OPT-1.3B, Pythia-1.0B 및 Pythia-1.4B와 비교했습니다.
상식 추론 작업에 대한 TinyLlama의 성능은 아래와 같습니다. TinyLlama는 많은 작업에서 기준보다 뛰어난 성능을 보이며 가장 높은 평균 점수를 얻는 것을 볼 수 있습니다.

또한, 연구원들은 사전 훈련 중 상식 추론 벤치마크에서 TinyLlama의 정확도를 추적했습니다. 그림 2에서 볼 수 있듯이 TinyLlama의 성능은 컴퓨팅 리소스가 증가함에 따라 향상되며 대부분의 벤치마크에서 Pythia-1.4B의 정확도.
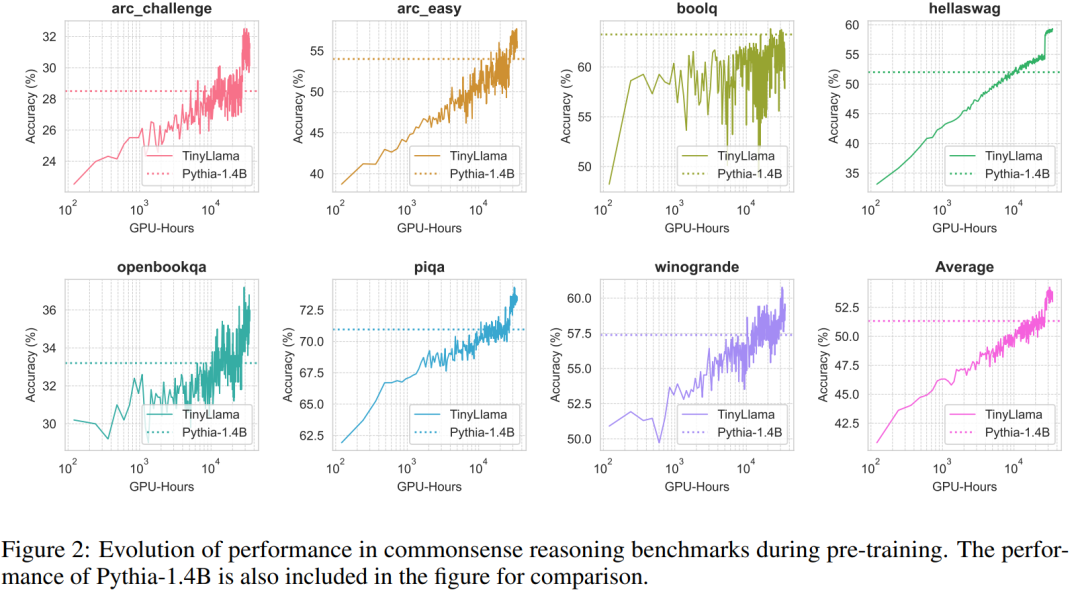
표 3을 보면 TinyLlama가 기존 모델에 비해 더 나은 문제 해결 능력을 보이는 것을 알 수 있습니다.
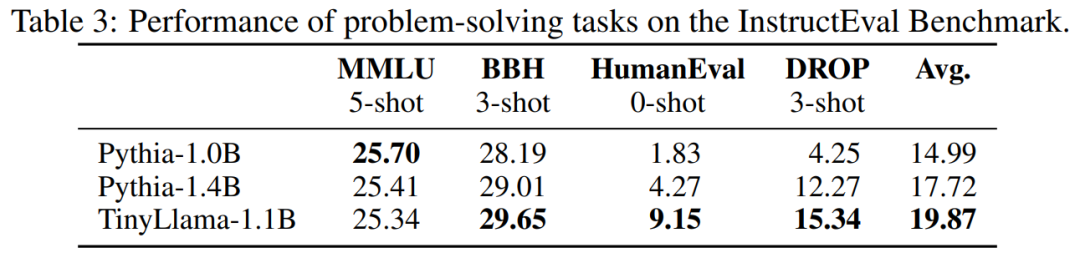
손이 빠른 네티즌들은 이미 시작하기 시작했습니다. 달리기 효과는 놀라울 정도로 좋습니다. GTX3060에서 실행하면 초당 136톡의 속도로 달릴 수 있습니다.
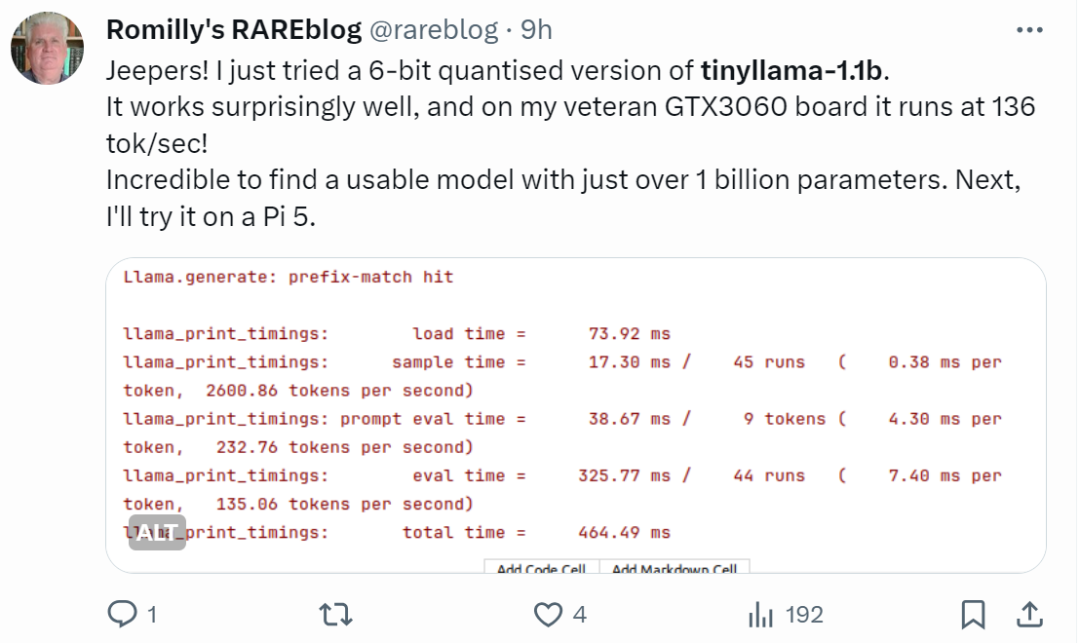
"정말 빠르네요!"
TinyLlama 출시로 인해 SLM(Small Language Model)이 시작되었습니다. 폭넓은 관심을 끌기 위해. Texas Tech와 A&M University의 Xiaotian Han이 SLM-LiteLlama를 출시했습니다. 460M 매개변수를 가지고 있으며 1T 토큰으로 훈련됩니다. 이는 Meta AI의 LLaMa 2의 오픈 소스 포크이지만 모델 크기가 훨씬 작습니다.
프로젝트 주소: https://huggingface.co/ahxt/LiteLlama-460M-1T
LiteLlama-460M-1T는 RedPajama 데이터 세트로 훈련되었으며 GPT2Tokenizer를 사용하여 텍스트를 토큰화합니다. 저자는 MMLU 작업에 대해 모델을 평가했으며 그 결과는 아래 그림에 나와 있습니다. 매개 변수 수가 크게 줄어들었음에도 LiteLlama-460M-1T는 여전히 다른 모델과 비슷하거나 더 나은 결과를 얻을 수 있습니다.
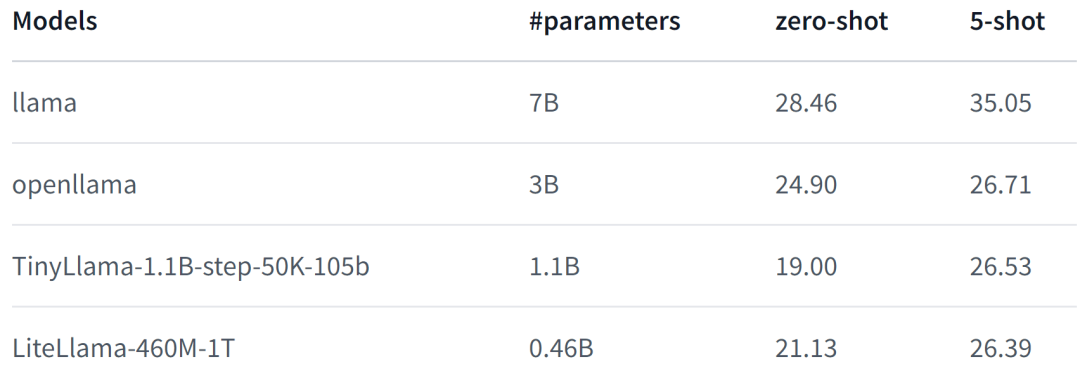
다음은 모델의 성능입니다.
규모가 대폭 줄어들면서 일부 네티즌들은 4GB 메모리에서도 구동이 가능한지 궁금해하고 있다. 당신도 알고 싶다면 직접 시도해 보는 것은 어떨까요?
위 내용은 작지만 강력한 모델이 증가하고 있습니다. TinyLlama와 LiteLlama가 인기 있는 선택이 되었습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



