최근 칭화대학교 컴퓨터과학과 Zhu Jun 교수 연구팀이 발표한 슈뢰딩거 다리[1] 기반 음성 합성 시스템은 "데이터- 데이터에 대한" 생성 패러다임 "잡음에 대한 데이터" 패러다임. 
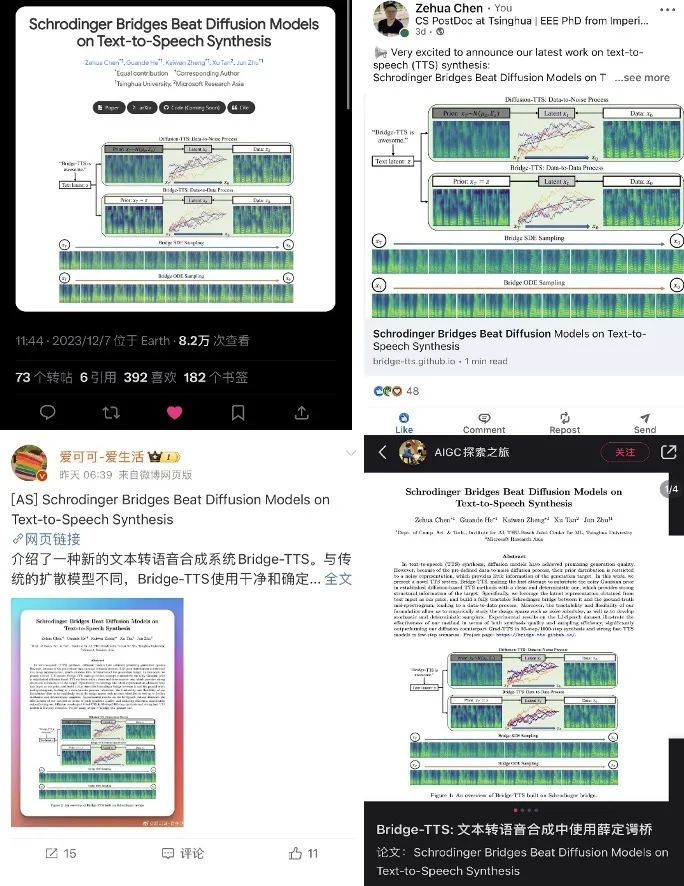
문서 링크: https://arxiv.org/abs/2312.03491 프로젝트 웹사이트: https://bridge-tts.github.io/ 코드 구현: https://github.com/thu -ml/Bridge-TTS2021년부터 텍스트-음성 합성(text-to-speech) 분야에서는 확산 모델이 가장 인기를 끌기 시작했습니다. , TTS) Huawei의 Noah's Ark Laboratory에서 제안한 Grad-TTS [2]와 Zhejiang University에서 제안한 DiffSinger [3]와 같은 핵심 생성 방법 중 하나가 높은 생성 품질을 달성했습니다. 그 이후로 많은 연구 작업에서 사전 최적화[2, 3, 4], 모델 증류[5, 6], 잔차 예측[7] 및 기타 방법을 통해 확산 모델의 샘플링 속도를 효과적으로 향상시켰습니다. 그러나 본 연구에서 보듯이 확산 모델은 "noise to data"라는 생성 패러다임에 국한되어 있기 때문에 사전 분포는 항상 생성 대상에 대한 제한된 정보를 제공하며 조건 정보를 충분히 활용할 수 없습니다. 음성 합성 분야의 최신 연구 작업인 Bridge-TTS는 슈뢰딩거 브리지 기반 생성 프레임워크를 사용하여 "데이터-데이터" 생성 프로세스를 최초로 실현합니다. 음성 합성의 사전 정보입니다. 노이즈에서 클린 데이터로 수정되고 는 분포에서 결정적 표현으로 수정됩니다.
이 방법의 주요 아키텍처는 위 그림에 나와 있습니다. 먼저 텍스트 인코더를 통해 입력 텍스트를 추출하여 생성된 대상의 잠재 공간 표현(멜-스펙트로그램, 멜 스펙트럼)을 추출합니다. 이후 이 정보를 잡음 분포에 통합하거나 조건 정보로 사용하는 확산 모델과 달리 Bridge-TTS 방식은 이를 직접 사전 정보로 활용하고 무작위 또는 결정적 샘플링을 지원하여 고품질, 고속 작업 결과
음성 합성 품질 검증을 위한 표준 데이터 세트인 LJ-Speech에서 연구팀은 9개의 고품질 음성 합성 시스템과 확산 장치로 Bridge-TTS를 가속화했습니다. 모델 샘플링 방법을 비교했습니다. 아래에 표시된 것처럼 이 방법은 샘플 품질(1000단계, 50단계 샘플링) 및 후처리 없이 샘플링 속도에서 고품질 확산 모델 기반 TTS 시스템[2, 3, 7]을 능가합니다. 추가 모델 증류와 같이 잔차 예측, 점진적 증류 및 최신 합의 증류와 같은 많은 가속 방법을 능가합니다 [5, 6, 7]. 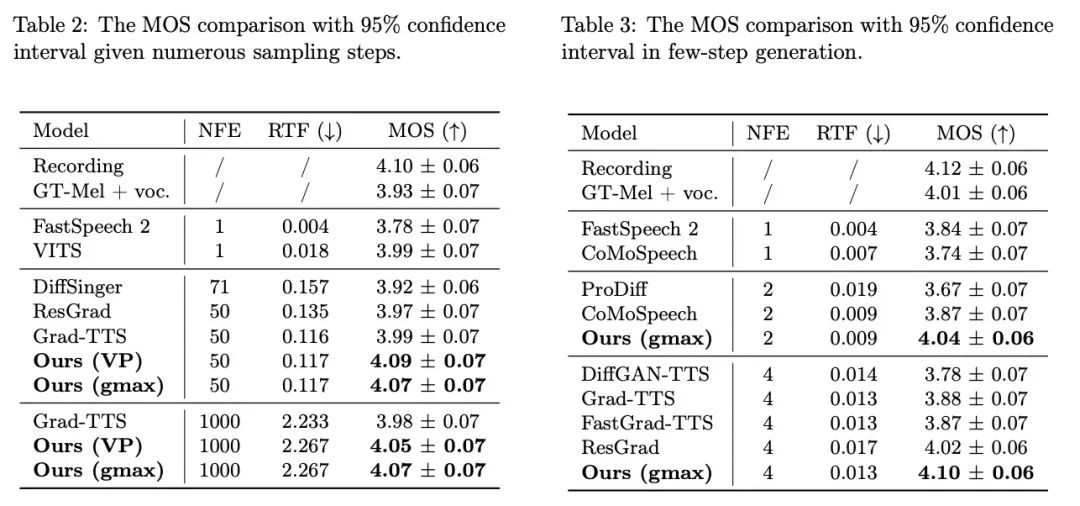 다음은 Bridge-TTS의 생성 효과와 확산 모델 기반 방법의 예입니다. 더 많은 세대 샘플 비교를 보려면 프로젝트 웹사이트(https://bridge-tts.github.io/)를 방문하세요.
다음은 Bridge-TTS의 생성 효과와 확산 모델 기반 방법의 예입니다. 더 많은 세대 샘플 비교를 보려면 프로젝트 웹사이트(https://bridge-tts.github.io/)를 방문하세요.
- 1000단계 합성 효과 비교
텍스트 입력: "그러면 우리의 목적에 따라 인쇄는 활자를 통해 책을 만드는 예술로 간주될 수 있습니다."
- 4 단계 합성 효과 비교
입력 텍스트: "첫 번째 책은 검은색 글자로 인쇄되었습니다. 즉, 고대 로마 문자의 고딕 발전 문자입니다."
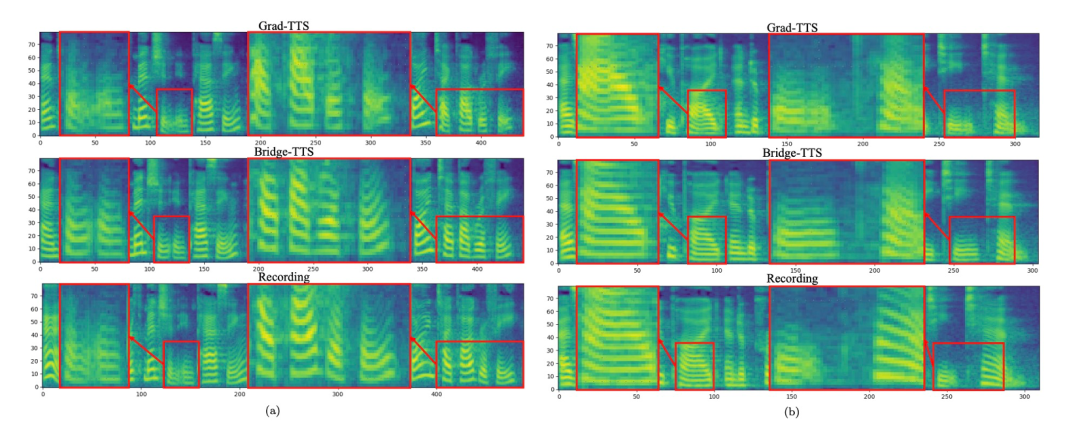
입력 텍스트: "교도소 인구는 크게 변동했습니다." 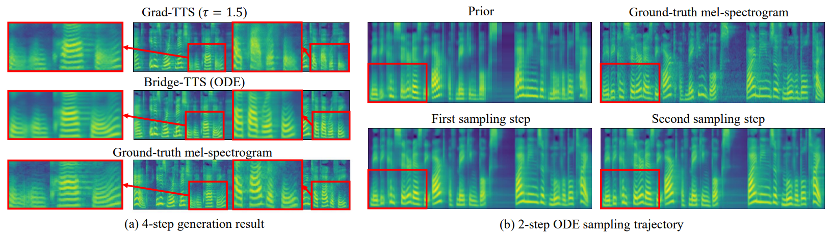 주파수 영역에서는 1000단계의 합성에서 더 많은 샘플이 생성되며, 이 방법은 샘플링 단계를 50단계로 줄였을 때 확산 모델에 비해 더 높은 품질의 멜 스펙트럼을 생성합니다. 확산 모델은 일부 샘플링 세부 사항을 희생했지만 Schrödinger 브리지 기반 방법은 여전히 고품질 생성 결과를 유지합니다. 4단계 및 2단계 합성에서 이 방법은 증류, 다단계 학습, 적대적 손실 함수가 필요하지 않으며 여전히 고품질 생성 효과를 달성합니다. 1000단계 합성에서 Bridge-TTS와 확산모델 기반 방법의 Mel 스펙트럼 비교
주파수 영역에서는 1000단계의 합성에서 더 많은 샘플이 생성되며, 이 방법은 샘플링 단계를 50단계로 줄였을 때 확산 모델에 비해 더 높은 품질의 멜 스펙트럼을 생성합니다. 확산 모델은 일부 샘플링 세부 사항을 희생했지만 Schrödinger 브리지 기반 방법은 여전히 고품질 생성 결과를 유지합니다. 4단계 및 2단계 합성에서 이 방법은 증류, 다단계 학습, 적대적 손실 함수가 필요하지 않으며 여전히 고품질 생성 효과를 달성합니다. 1000단계 합성에서 Bridge-TTS와 확산모델 기반 방법의 Mel 스펙트럼 비교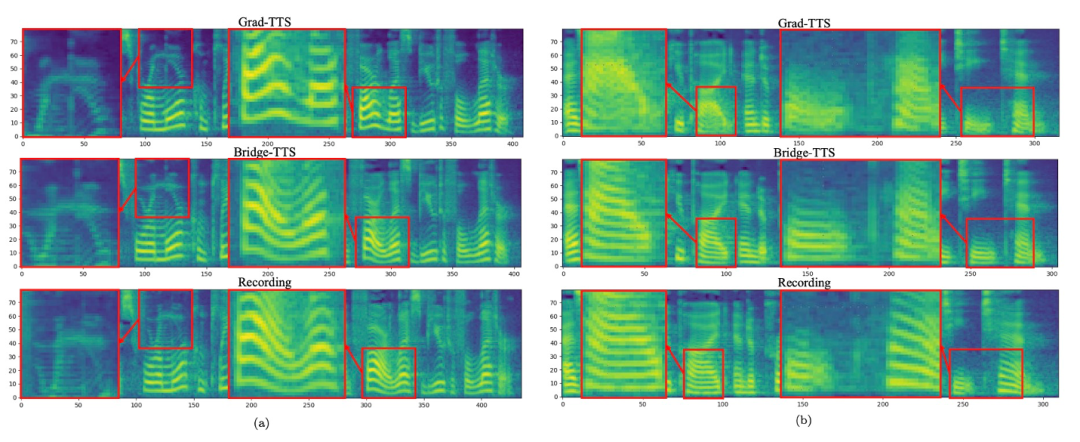
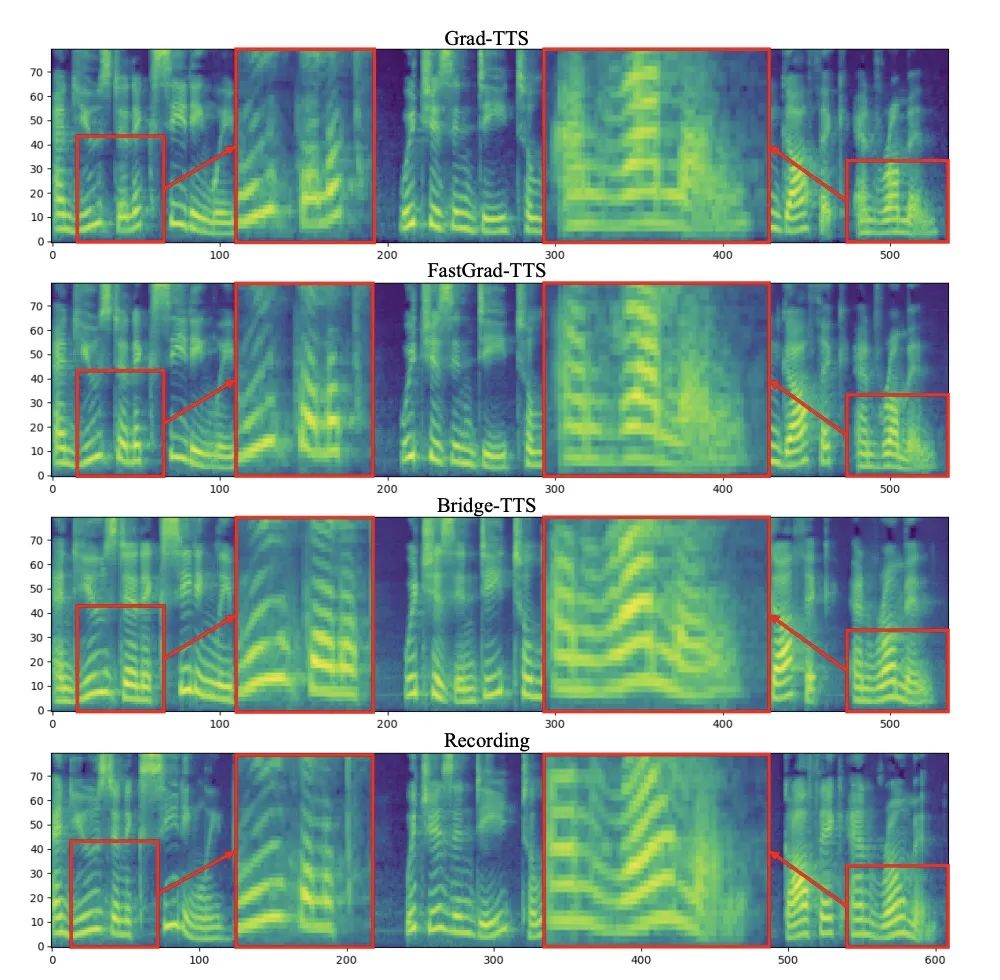
50단계 합성에서 Bridge-TTS와 확산 모델 기반 방법 확산 모델 방법의 멜 스펙트럼 비교
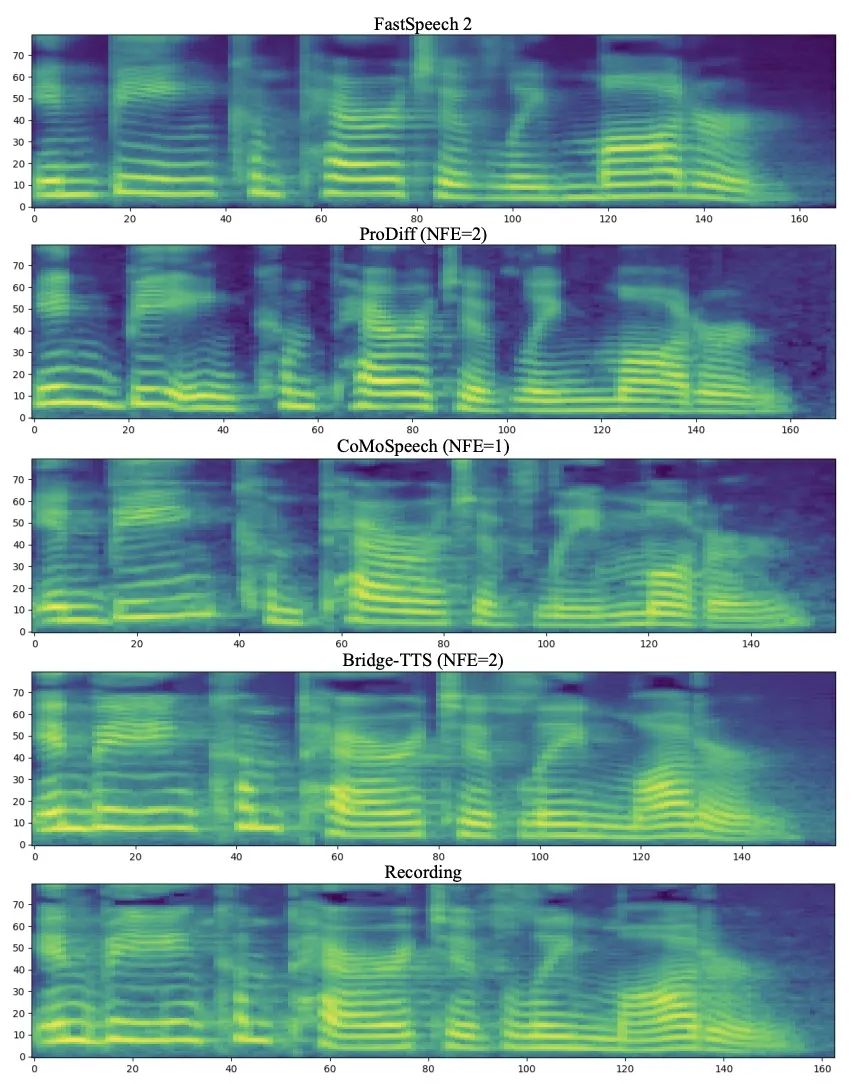
4단계 합성에서 Bridge-TTS와 확산 모델 기반 방법의 Mel 스펙트럼 비교2단계 합성에서는 Bridge-TTS와 확산 기반 방법 방법 모델 방법의 멜 스펙트럼 비교 Bridge-TTS는 출시 당시 참신한 디자인과 음성 합성의 고품질 합성 효과로 트위터에서 뜨거운 관심을 받았으며 수백 개가 넘는 댓글을 받았습니다. 100개의 리트윗과 수백 개의 좋아요를 받은 허깅페이스는 12.7일 허깅페이스 데일리 페이퍼에 선정돼 이날 지지율 1위를 차지함과 동시에 링크드인, 웨이보, 지후 등 국내외 다수 플랫폼에서 팔로우를 기록했다. Xiaohongshu 및 앞으로 보고서. 많은 외국어 사이트에서도 보고되고 논의되었습니다. 슈뢰딩거 브리지는 확산 모델에 이어 최근에 등장한 모델 중 하나입니다. deep generative model은 이미지 생성, 이미지 번역 및 기타 분야에 예비 적용됩니다[8,9]. 데이터와 가우스 노이즈 간의 변환 프로세스를 설정하는 확산 모델과 달리 슈뢰딩거 브리지는 두 경계 분포 간의 변환을 지원합니다. Bridge-TTS 연구에서 저자는 다양한 순방향 프로세스, 예측 대상 및 샘플링 프로세스를 유연하게 지원하는 쌍 데이터 간의 Schrödinger 브리지를 기반으로 하는 음성 합성 프레임워크를 제안했습니다. 해당 방법의 개요는 아래 그림에 나와 있습니다. 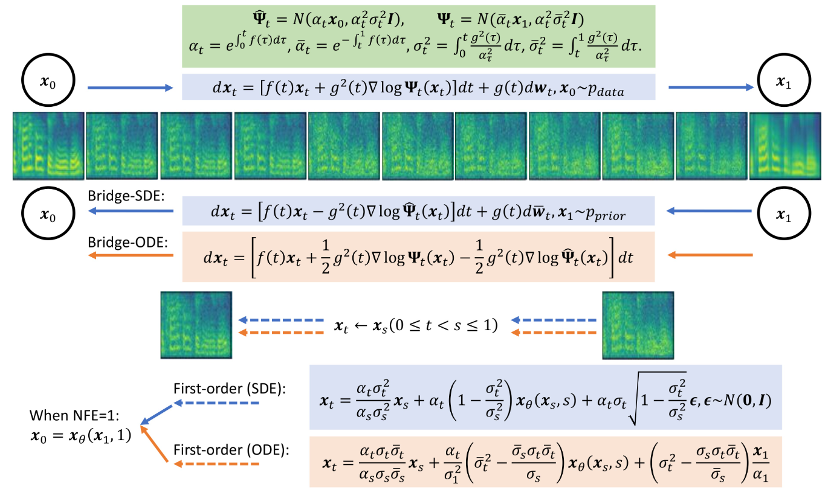
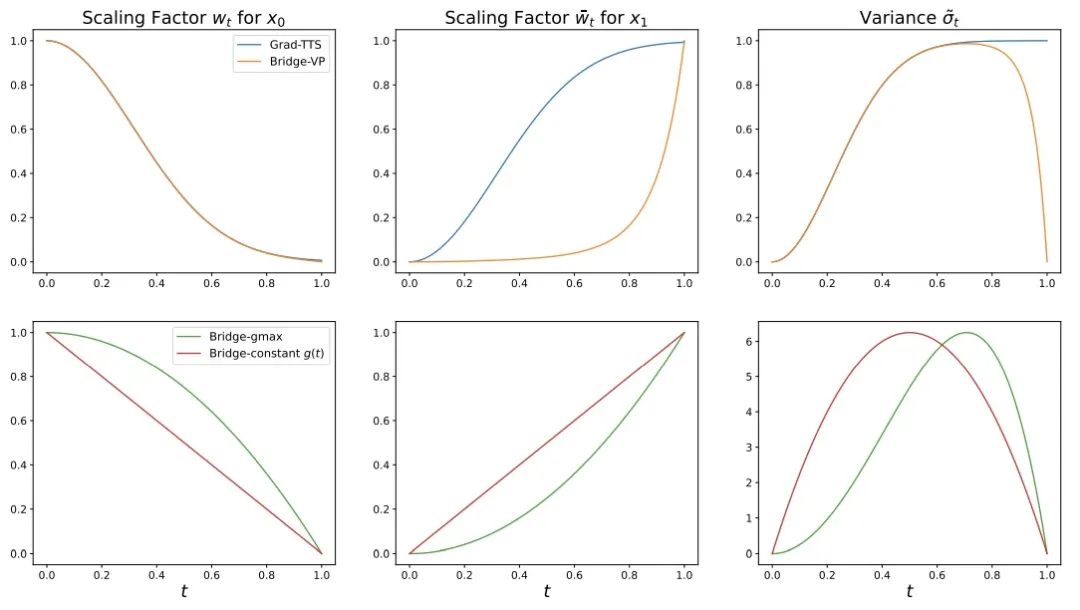
- 전진 프로세스: 이 연구는 강력한 정보 사전 정보와 생성 목표 사이에 완전히 해결 가능한 슈뢰딩거 브리지를 구축하여 유연한 전진 프로세스를 지원합니다. 대칭 노이즈 중에서 선택합니다. 전략:
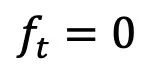 , 상수
, 상수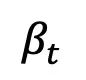 및 비대칭 잡음 전략:
및 비대칭 잡음 전략:  , 선형
, 선형 및 확산 모델에 직접적으로 대응하는 분산 보존(VP)잡음 전략. 이 방법은 음성 합성 작업에서 비대칭 잡음 전략: 선형
및 확산 모델에 직접적으로 대응하는 분산 보존(VP)잡음 전략. 이 방법은 음성 합성 작업에서 비대칭 잡음 전략: 선형  (gmax) 및 VP 프로세스가 대칭 잡음 전략보다 더 나은 생성 효과를 갖는다는 것을 발견했습니다.
(gmax) 및 VP 프로세스가 대칭 잡음 전략보다 더 나은 생성 효과를 갖는다는 것을 발견했습니다.

- 모델 훈련: 이 방법은 단일 단계, 단일 모델, 단일 손실 함수 등 확산 모델 훈련 프로세스의 여러 장점을 유지합니다. 그리고 잡음 예측(Noise), 생성 목표 예측(Data), 확산 모델에 대응하는 흐름 매칭 기술 등 다양한 모델 매개변수화(Model paramization), 즉 네트워크 훈련 대상 선정 방법을 비교한다[10,11 ] 속도예측(Velocity) 등 기사에서는 생성 대상, 즉 멜 스펙트럼을 네트워크 예측 대상으로 사용할 경우 상대적으로 더 나은 생성 결과를 얻을 수 있음을 발견했습니다.
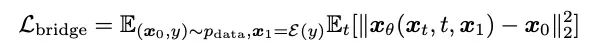
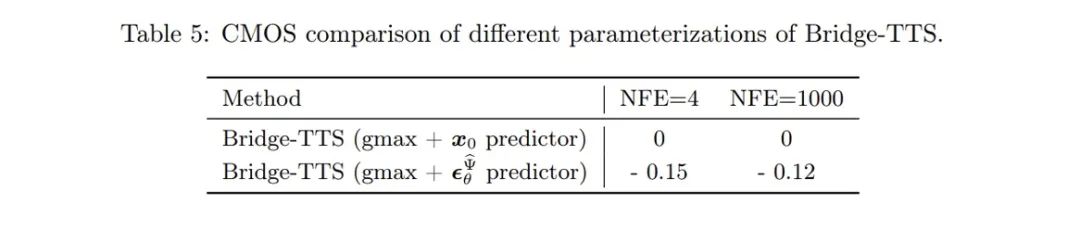
- Sampling process: 본 연구에서는 슈뢰딩거 브리지의 완전히 해결 가능한 형태 덕분에 슈뢰딩거 브리지에 해당하는 전방향-후진 SDE 시스템을 변환하여 저자는 브리지 SDE와 추론에는 Bridge ODE가 사용됩니다. 동시에 Bridge SDE/ODE 추론의 직접 시뮬레이션 속도가 느리기 때문에 샘플링 속도를 높이기 위해 본 연구에서는 확산 모델에서 일반적으로 사용되는 지수 적분기를 사용했으며[12,13], 1차 슈뢰딩거 브리지의 SDE 및 ODE 샘플링 형식:
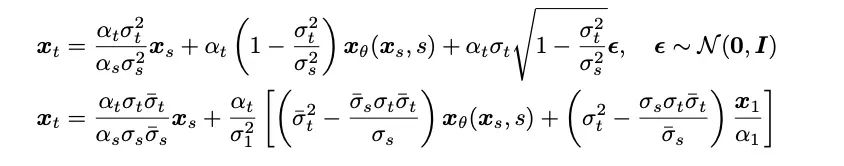
1단계 샘플링에서는 1차 SDE와 ODE의 샘플링 형식이 공동으로 네트워크의 단일 단계 예측으로 변질됩니다. 동시에 이는 사후 샘플링/확산 모델인 DDIM 샘플링과 밀접한 관련이 있으며, 기사에서는 부록에서 자세한 분석을 제공합니다. 이 기사에서는 슈뢰딩거 브리지의 2차 샘플링 SDE 및 ODE 샘플링 알고리즘도 제공합니다. 저자는 음성 합성에서 생성 품질이 1차 샘플링 프로세스와 유사하다는 것을 발견했습니다. 음성 향상, 음성 분리, 음성 편집 등 사전 정보가 강한 기타 작업에서도 저자는 이 연구가 더 큰 응용 가치를 가져올 것으로 기대합니다. 이 연구에는 세 명의 공동 제1저자가 있습니다: Chen Zehua, He Guande 및 Zheng Kaiwen은 모두 Tsinghua University 컴퓨터 과학과의 Zhu Jun 연구 그룹에 속합니다. 해당 기사의 교신저자는 Microsoft Asia Research의 Zhu Jun 교수이며 연구소의 수석 연구 관리자인 Tan Xu는 프로젝트 공동 작업자입니다. 
Tan Xu, Microsoft Research Asia 수석 연구 관리자, 음향 효과, 생체 전기 신호 합성 및 기타 애플리케이션. 그는 Microsoft, JD.com, TikTok 등 여러 회사에서 인턴으로 일했으며 ICML/NeurIPS/ICASSP 등 음성 및 기계 학습 분야의 중요한 국제 회의에서 많은 논문을 발표했습니다.

He Guande는 칭화대학교 석사 3학년 학생입니다. 그의 주요 연구 방향은 불확실성 추정 및 생성 모델입니다. 그는 이전에 ICLR과 같은 컨퍼런스에서 첫 번째 저자로 논문을 발표했습니다.

Zheng Kaiwen은 칭화 대학교 석사 2년차 학생입니다. 그의 주요 연구 방향은 심층 생성 모델의 이론과 알고리즘, 그리고 이미지, 오디오 및 3D 생성에 대한 응용입니다. 그는 이전에 ICML/NeurIPS/CVPR과 같은 주요 컨퍼런스에서 확산 모델의 흐름 일치 및 지수 적분기와 같은 기술과 관련된 많은 논문을 발표했습니다. [1] Zehua Chen, Guande He, Kaiwen Zheng, Xu Tan 및 Jun Zhu는 텍스트-음성 합성에서 확산 모델을 이겼습니다. :2312.03491, 2023. [2] Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova 및 Mikhail A. Kudinov: 텍스트 음성 변환을 위한 확산 확률 모델, 2021.[3] Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen 및 Zhou Zhao: AAAI에서 얕은 확산 메커니즘을 통한 노래 음성 합성, 2022.[ 4 ] 이상길, 김희승, 신채훈, Xu Tan, Chang Liu, Qi Meng, Tao Qin, Wei Chen, 윤성로, Tie-Yan Liu. PriorGrad: 데이터 종속 적응형 사전을 사용한 조건부 노이즈 제거 확산 모델 개선 . ICLR, 2022. [5] Rongjie Huang, Zhou Zhao, Huadai Liu, Jinglin Liu, Chenye Cui 및 Yi Ren: 고품질 텍스트 음성 변환을 위한 점진적 고속 확산 모델. ACM 멀티미디어, 2022. [6] Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu 및 Yike Guo. ACM 멀티미디어의 일관성 모델을 통한 원스텝 음성 및 노래 음성 합성. , 2023.[7] Zehua Chen, Yihan Wu, Yichong Leng, Jiawei Chen, Haohe Liu, Xu Tan, Yang Cui, Ke Wang, Lei He, Sheng Zhao, Jiang Bian 및 Danilo P. Mandic ResGrad: 텍스트 음성 변환을 위한 잔류 노이즈 제거 확률 모델. arXiv 사전 인쇄 arXiv:2212.14518, 2022.[8] Yuyang Shi, Valentin De Bortoli, Andrew Campbell 및 Arnaud Doucet. 에서 NeurIPS 2023.[9] Guan-Horng Liu, Arash Vahdat, De-An Huang, Evangelos A. Theodorou, Weili Nie 및 Anima Anandkumar: 이미지 간 슈뢰딩거 브리지. 2023.[10] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel 및 Matt Le. ICLR의 생성 모델링, 2023.[11] Kaiwen Zheng, Cheng Lu, Jianfei Chen 및 Jun Zhu. ICML의 최대 가능성 추정을 위한 향상된 기술, 2023.[12] Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li 및 Jun Zhu: 약 10단계의 확산 확률 모델 샘플링을 위한 빠른 ODE 솔버. In NeurIPS, 2022.[13] Kaiwen Zheng, Cheng Lu, Jianfei Chen 및 Jun Zhu . DPM-Solver-v3: NeurIPS에서 경험적 모델 통계를 사용하여 향상된 확산 ODE 솔버, 2023.위 내용은 Schrödinger Bridge의 도움으로 Tsinghua University의 Zhu Jun 팀은 확산 문제를 해결하기 위한 새로운 음성 합성 시스템을 개발했습니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!


 , 선형
, 선형 및 확산 모델에 직접적으로 대응하는 분산 보존(VP)잡음 전략. 이 방법은 음성 합성 작업에서 비대칭 잡음 전략: 선형
및 확산 모델에 직접적으로 대응하는 분산 보존(VP)잡음 전략. 이 방법은 음성 합성 작업에서 비대칭 잡음 전략: 선형 
















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



