

생산 중인 모델은 "안전 시스템" 팀에서 관리합니다. 개발 중인 최첨단 모델에는 모델이 출시되기 전에 위험을 식별하고 정량화하는 "준비" 팀이 있습니다. 그리고 "초지능" 모델에 대한 이론적 지침을 작성하는 "Super Alignment" 팀이 있습니다
보안 자문 그룹을 기술팀 위에 위치시켜 리더십에 권고하고 이사회에 거부권을 부여하도록 재구성하세요
OpenAI는 유해한 인공지능의 위협을 방어하기 위해 내부 보안 프로세스를 강화한다고 밝혔습니다. 그들은 기술팀 위에 앉아 리더십에 조언을 제공하고 이사회에 거부권을 부여하는 "보안 자문 그룹"이라는 새로운 부서를 만들 것입니다. 이 결정은 현지 시간으로 12월 18일에 발표되었습니다
이번 업데이트가 우려되는 이유는 OpenAI CEO 샘 알트먼(Sam Altman)이 이사회에서 해임됐는데, 이는 대형 모델의 안전 문제와 관련이 있는 것으로 보입니다. OpenAI 이사회의 "둔화" 멤버인 Ilya Sutskvi와 Helen Toner는 고위 인사 개편으로 인해 이사회 자리를 잃었습니다
이 게시물에서 OpenAI는 점점 더 강력해지는 모델로 인해 발생하는 치명적인 위험을 OpenAI가 추적, 평가, 예측 및 보호하는 방법인 최신 "준비 프레임워크"에 대해 논의합니다. 재앙적 위험의 정의는 무엇입니까? OpenAI는 “우리가 재앙적 위험이라고 부르는 것은 수천억 달러의 경제적 손실을 초래하거나 많은 사람에게 심각한 부상이나 사망을 초래할 수 있는 위험을 의미합니다. 여기에는 실존적 위험도 포함되지만 이에 국한되지는 않습니다.”
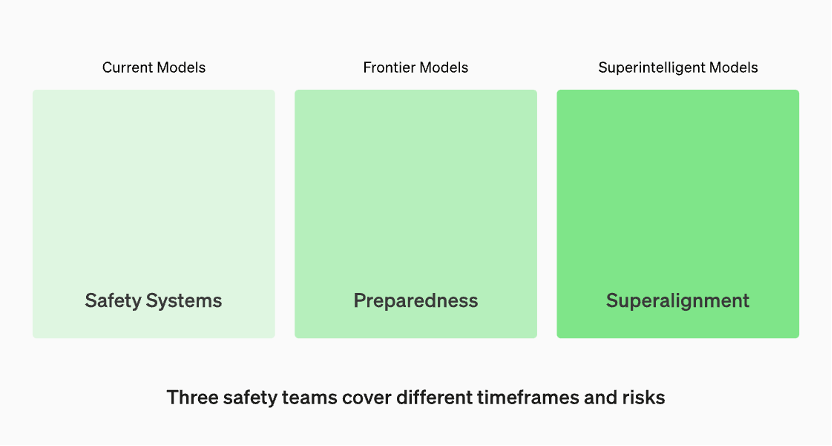
OpenAI 공식 홈페이지에 따르면 생산 중인 모델은 '보안 시스템'팀에서 관리한다고 합니다. 개발 단계에서는 모델이 출시되기 전에 위험을 식별하고 평가하는 '준비'라는 팀이 있습니다. 또한, "초지능" 모델에 대한 이론적 지침을 연구하는 "superalignment"라는 팀이 있습니다
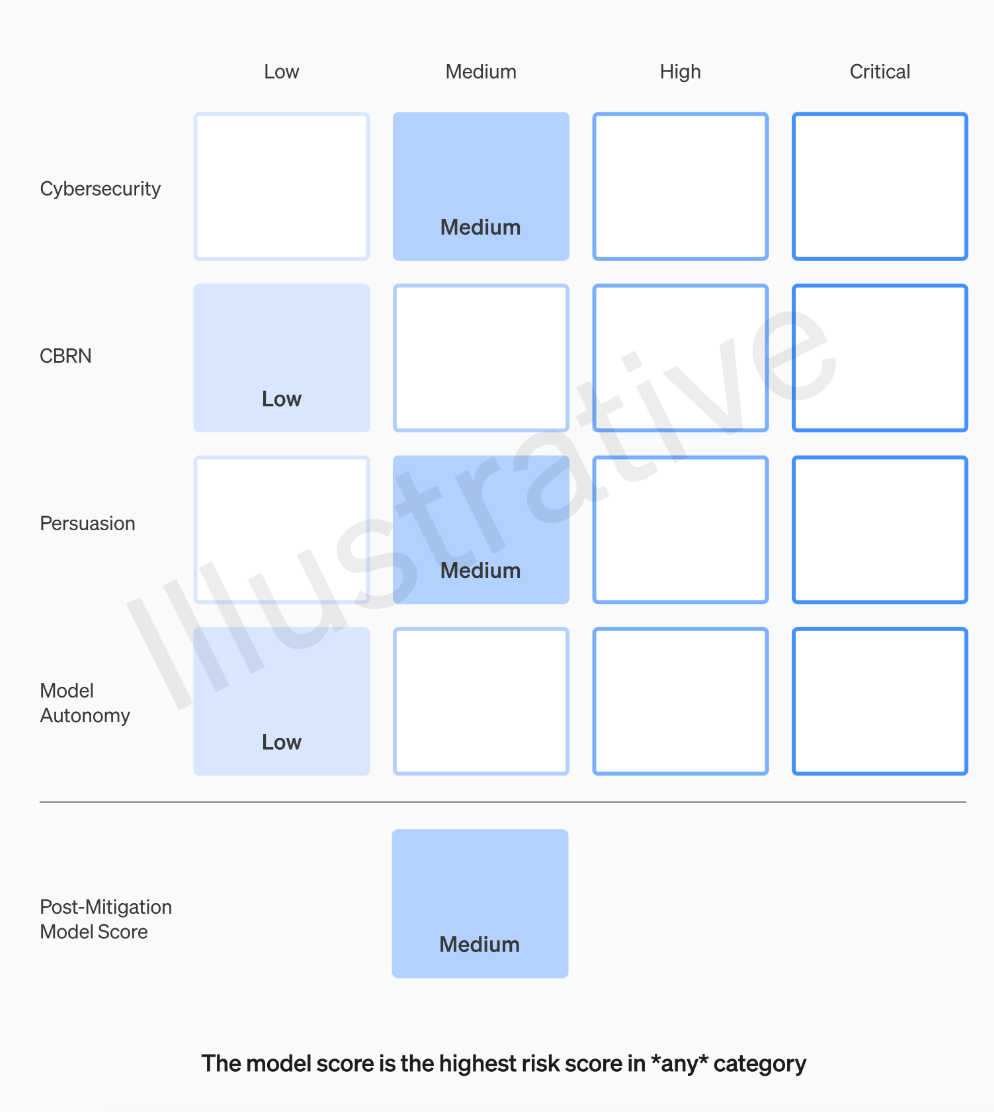
OpenAI 팀은 사이버 보안, 설득력(예: 허위 정보), 모델 자율성(즉, 자율적으로 행동하는 능력), CBRN(화학, 생물학, 방사능 및 핵 위협)이라는 네 가지 위험 범주에 따라 각 모델을 평가합니다. 새로운 병원체를 생성하는 능력)
OpenAI는 가정에서 다양한 완화를 고려합니다. 예를 들어 모델은 네이팜탄이나 파이프 폭탄 제조 과정을 설명하는 데 합리적인 유보를 유지합니다. 알려진 완화 조치를 고려한 후에도 모델이 여전히 "높은" 위험이 있는 것으로 평가되면 배포되지 않으며, 모델이 "중요한" 위험을 나타내는 경우 더 이상 개발되지 않습니다.
모델을 만드는 모든 사람이 이를 평가하고 추천하는 데 가장 적합한 사람은 아닙니다. 이러한 이유로 OpenAI는 기술 수준에서 연구원의 보고서를 검토하고 더 높은 관점에서 권장 사항을 제시하는 "기능 간 보안 자문 그룹"이라는 팀을 구성하여 "알려지지 않은 미지의" 일부를 밝혀내기를 희망하고 있습니다. " "
이 과정에서는 이러한 권장 사항을 이사회와 경영진 모두에게 보내야 하며, 경영진은 운영을 계속할지 중단할지 결정하게 됩니다. 그러나 이사회는 이러한 결정을 번복할 권리가 있습니다. 이렇게 하면 이사회가 모르는 사이에 고위험 제품이나 프로세스가 승인되는 것을 방지할 수 있습니다
그러나 외부에서는 여전히 전문가 패널이 권고사항을 제시하고 CEO가 이 정보를 바탕으로 의사결정을 한다면 과연 OpenAI 이사회가 반박하고 조치를 취할 권리가 있을까? 그렇다면 대중이 그 소식을 듣게 될까요? 현재 독립적인 제3자 감사를 요청하겠다는 OpenAI의 약속 외에 투명성 문제는 실제로 해결되지 않았습니다
OpenAI의 “Readiness Framework”에는 다음과 같은 5가지 핵심 요소가 포함되어 있습니다.
1. 평가 및 채점우리는 모델을 평가하고 "스코어카드"를 지속적으로 업데이트할 것입니다. 훈련 중 효과적인 계산을 3배로 늘리는 것을 포함하여 모든 최신 모델을 평가할 것입니다. 우리는 모델의 한계를 뛰어넘을 것입니다. 이러한 결과는 최신 모델의 위험을 평가하고 제안된 완화 조치의 효율성을 측정하는 데 도움이 될 것입니다. 우리의 목표는 엣지별 불안정성을 감지하여 위험을 효과적으로 완화하는 것입니다. 모델의 안전 수준을 추적하기 위해 위험 "스코어카드"와 세부 보고서를 생성합니다
위험 임계값을 설정하는 목적은 의사 결정을 내리고 위험을 관리할 때 명확한 경계를 설정하는 것입니다. 위험 임계값은 특정 상황에서 조직이나 개인이 기꺼이 감당할 수 있는 최대 위험 수준을 나타냅니다. 위험 임계값을 설정하면 조직이나 개인이 위험을 완화하거나 방지하기 위해 조치가 필요한 시기를 식별하는 데 도움이 될 수 있습니다. 위험 임계값 설정은 위험 평가 결과, 관련 규정 및 정책, 조직이나 개인의 위험 허용 범위를 기반으로 해야 합니다. 위험 임계값을 설정할 때 위험 관리 조치의 효율성과 적용 가능성을 보장하기 위해 다양한 위험 유형의 특성과 영향을 고려해야 합니다. 마지막으로, 조직 또는 개인의 위험 관리 목표와 일관성을 유지하기 위해 설정된 위험 임계값을 정기적으로 평가하고 조정해야 합니다
보안 조치를 실행하는 위험 임계값을 설정합니다. 우리는 사이버 보안, CBRN(화학적, 생물학적, 방사선학적, 핵 위협), 설득, 모델 자율성 등의 예비 추적 범주를 기반으로 위험 수준에 대한 임계값을 설정합니다. 우리는 네 가지 보안 위험 수준을 지정하고 완화 후 점수가 "중간" 이하인 모델만 배포할 수 있습니다. 완화 후 점수가 "높음" 이하인 모델만 추가로 개발할 수 있습니다. 위험성이 높거나 심각한 모델(사전 완화)에 대해서는 추가 보안 조치도 시행할 예정입니다

위험레벨
기술 작업 모니터링 및 안전 의사결정을 위한 운영 구조 재설정
우리는 보안 결정의 기술 작업 및 운영 구조를 감독하기 위해 전담 팀을 구성할 것입니다. 준비팀은 최첨단 모델의 기능 한계를 조사하고 평가 및 포괄적인 보고를 수행하기 위한 기술 작업을 추진할 것입니다. 이 기술 작업은 OpenAI 보안 모델의 개발 및 배포 결정에 중요합니다. 우리는 모든 보고서를 검토하고 이를 경영진과 이사회에 보내기 위해 다기능 보안 자문 그룹을 만들고 있습니다. 리더십이 의사결정자이지만 이사회는 결정을 번복할 수 있는 권한을 가지고 있습니다
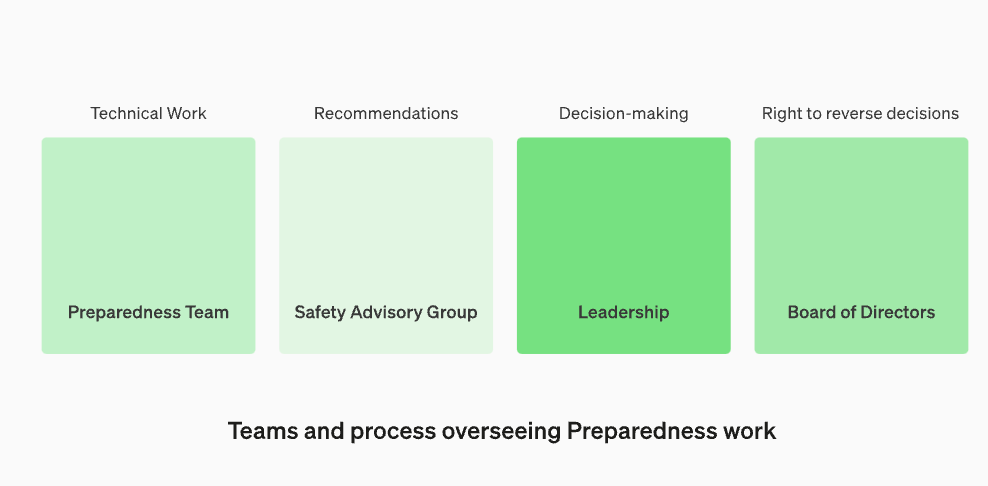
기술 작업 및 보안 의사결정 운영 구조의 새로운 변화를 감독합니다
보안 강화 및 외부 책임 강화
우리는 안전과 외부 책임성을 향상하기 위한 프로토콜을 개발할 것입니다. 우리는 정기적인 보안 훈련을 실시하여 비즈니스와 문화에 대한 스트레스 테스트를 실시할 것입니다. 일부 보안 문제는 빠르게 발생할 수 있으므로 빠른 대응을 위해 긴급한 문제를 표시할 수 있습니다. OpenAI 외부의 사람들로부터 피드백을 받고 자격을 갖춘 독립적인 제3자가 이를 검토하도록 하는 것이 도움이 된다고 믿습니다. 우리는 계속해서 다른 사람들이 레드 팀을 구성하고 모델을 평가하도록 할 것이며 업데이트를 외부에 공유할 계획입니다
알려진 보안 위험과 알려지지 않은 기타 보안 위험을 줄입니다.
알려진 보안 위험과 알려지지 않은 기타 보안 위험을 완화하는 데 도움을 드립니다. 우리는 실제 남용을 추적하기 위해 보안 시스템과 같은 팀과 내부적으로는 물론 외부 당사자와도 긴밀하게 협력할 것입니다. 또한 Super Alignment와 협력하여 긴급한 정렬 불량 위험을 추적할 것입니다. 또한 우리는 규모의 법칙에 대한 이전의 성공과 유사하게 모델이 확장됨에 따라 위험이 어떻게 진화하는지 측정하고 위험을 미리 예측하는 데 도움이 되는 새로운 연구를 개척하고 있습니다. 마지막으로, 새로운 "알 수 없는 미지의 문제"를 해결하기 위한 지속적인 프로세스를 갖게 될 것입니다
위 내용은 OpenAI는 보안 팀을 강화하여 위험한 AI를 거부할 수 있는 권한을 부여합니다.의 상세 내용입니다. 자세한 내용은 PHP 중국어 웹사이트의 기타 관련 기사를 참조하세요!

















![[웹 프런트엔드] Node.js 빠른 시작](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



